## Why this PR?
Fixes#2624
There's a missing import statement in AzureOpenAI embeddings example.
## What's new in this PR?
- Import `OpenAIEmbeddings` before creating it's object.
## How it's tested?
- By running notebook and creating embedding object.
Signed-off-by: letmerecall <girishsharma001@gmail.com>
Referencing #2595
Added optional default parameter to adjust index metadata upon
collection creation per chroma code
ce0bc89777/chromadb/api/local.py (L74)
Allowing for user to have the ability to adjust distance calculation
functions.
closes#1634
Adds support for loading files from a shared Google Drive folder to
`GoogleDriveLoader`. Shared drives are commonly used by businesses on
their Google Workspace accounts (this is my particular use case).
RWKV is an RNN with a hidden state that is part of its inference.
However, the model state should not be carried across uses and it's a
bug to do so.
This resets the state for multiple invocations
Added support for passing the openai_organization as an argument, as it
was only supported by the environment variable but openai_api_key was
supported by both environment variables and arguments.
`ChatOpenAI(temperature=0, model_name="gpt-4", openai_api_key="sk-****",
openai_organization="org-****")`
Almost all integration tests have failed, but we haven't encountered any
import errors yet. Some tests failed due to lazy import issues. It
doesn't seem like a problem to resolve some of these errors in the next
PR.
I have a headache from resolving conflicts with `deeplake` and `boto3`,
so I will temporarily comment out `boto3`.
fix https://github.com/hwchase17/langchain/issues/2426
Using `pytest-vcr` in integration tests has several benefits. Firstly,
it removes the need to mock external services, as VCR records and
replays HTTP interactions on the fly. Secondly, it simplifies the
integration test setup by eliminating the need to set up and tear down
external services in some cases. Finally, it allows for more reliable
and deterministic integration tests by ensuring that HTTP interactions
are always replayed with the same response.
Overall, `pytest-vcr` is a valuable tool for simplifying integration
test setup and improving their reliability
This commit adds the `pytest-vcr` package as a dependency for
integration tests in the `pyproject.toml` file. It also introduces two
new fixtures in `tests/integration_tests/conftest.py` files for managing
cassette directories and VCR configurations.
In addition, the
`tests/integration_tests/vectorstores/test_elasticsearch.py` file has
been updated to use the `@pytest.mark.vcr` decorator for recording and
replaying HTTP interactions.
Finally, this commit removes the `documents` fixture from the
`test_elasticsearch.py` file and replaces it with a new fixture defined
in `tests/integration_tests/vectorstores/conftest.py` that yields a list
of documents to use in any other tests.
This also includes my second attempt to fix issue :
https://github.com/hwchase17/langchain/issues/2386
Maybe related https://github.com/hwchase17/langchain/issues/2484
I noticed that the value of get_num_tokens_from_messages in `ChatOpenAI`
is always one less than the response from OpenAI's API. Upon checking
the official documentation, I found that it had been updated, so I made
the necessary corrections.
Then now I got the same value from OpenAI's API.
d972e7482e (diff-2d4485035b3a3469802dbad11d7b4f834df0ea0e2790f418976b303bc82c1874L474)
The gitbook importer had some issues while trying to ingest a particular
site, these commits allowed it to work as expected. The last commit
(06017ff) is to open the door to extending this class for other
documentation formats (which will come in a future PR).
Right now, eval chains require an answer for every question. It's
cumbersome to collect this ground truth so getting around this issue
with 2 things:
* Adding a context param in `ContextQAEvalChain` and simply evaluating
if the question is answered accurately from context
* Adding chain of though explanation prompting to improve the accuracy
of this w/o GT.
This also gets to feature parity with openai/evals which has the same
contextual eval w/o GT.
TODO in follow-up:
* Better prompt inheritance. No need for seperate prompt for CoT
reasoning. How can we merge them together
---------
Co-authored-by: Vashisht Madhavan <vashishtmadhavan@Vashs-MacBook-Pro.local>
#991 has already implemented this convenient feature to prevent
exceeding max token limit in embedding model.
> By default, this function is deactivated so as not to change the
previous behavior. If you specify something like 8191 here, it will work
as desired.
According to the author, this is not set by default.
Until now, the default model in OpenAIEmbeddings's max token size is
8191 tokens, no other openai model has a larger token limit.
So I believe it will be better to set this as default value, other wise
users may encounter this error and hard to solve it.
Add support for defining the organization of OpenAI, similarly to what
is done in the reference code below:
```
import os
import openai
openai.organization = os.getenv("OPENAI_ORGANIZATION")
openai.api_key = os.getenv("OPENAI_API_KEY")
```
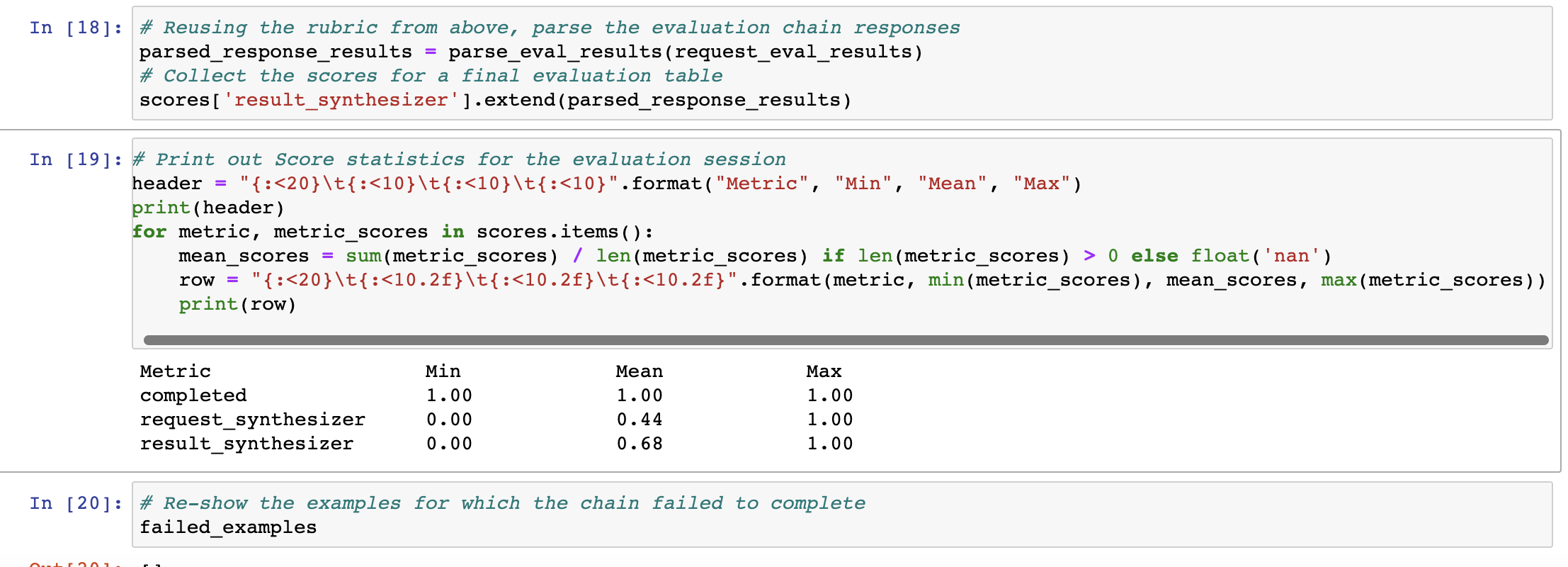
Evaluation so far has shown that agents do a reasonable job of emitting
`json` blocks as arguments when cued (instead of typescript), and `json`
permits the `strict=False` flag to permit control characters, which are
likely to appear in the response in particular.
This PR makes this change to the request and response synthesizer
chains, and fixes the temperature to the OpenAI agent in the eval
notebook. It also adds a `raise_error = False` flag in the notebook to
facilitate debugging
This still doesn't handle the following
- non-JSON media types
- anyOf, allOf, oneOf's
And doesn't emit the typescript definitions for referred types yet, but
that can be saved for a separate PR.
Also, we could have better support for Swagger 2.0 specs and OpenAPI
3.0.3 (can use the same lib for the latter) recommend offline conversion
for now.
{kind=link}