forked from Archives/langchain
Add an Example Evaluation Notebook for the API Chain (#2516)
Taking the Klarna API as an example, uses evaluation chain's to judge the quality of the request and response synthesizers based on a small set of curated queries. Also updates intermediate steps for chain to emit a dict so each step can be keyed for lookup 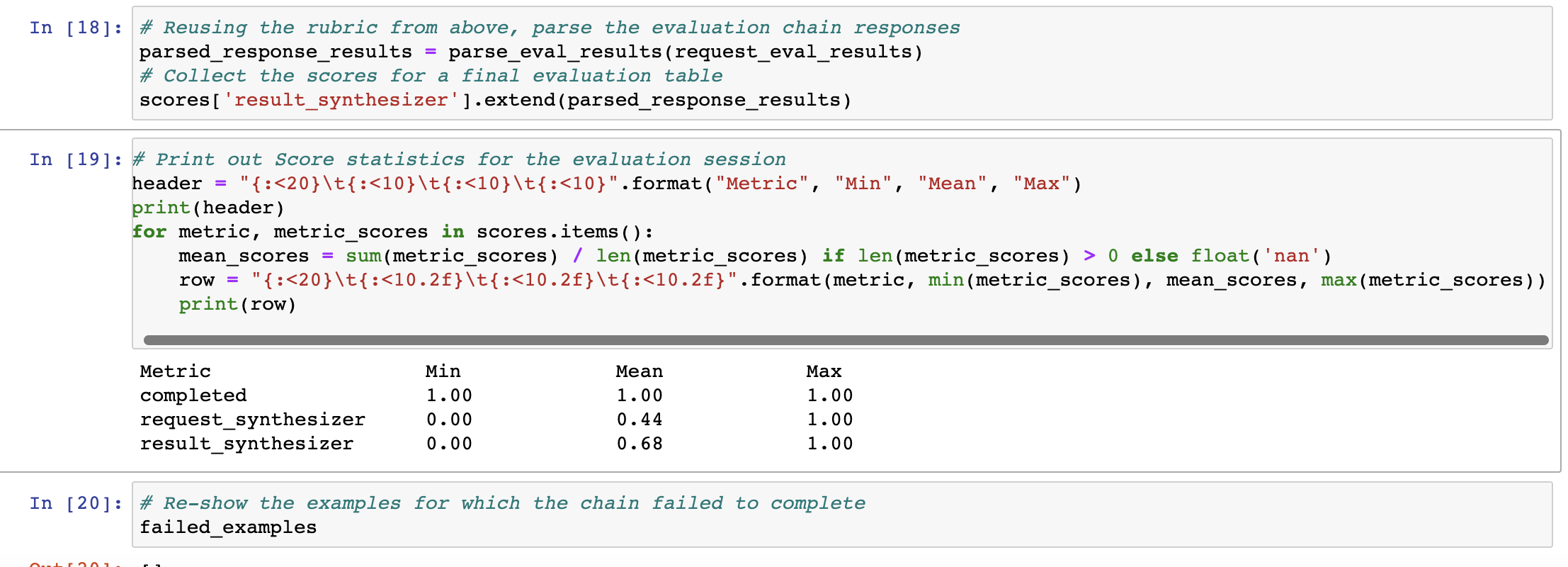doc
{kind=link}
parent
bd780a8223
commit
f8e4048cd8
@ -0,0 +1,563 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "692f3256",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Evaluating an OpenAPI Chain\n",
|
||||
"\n",
|
||||
"This notebook goes over ways to semantically evaluate an OpenAPI Chain, which calls an endpoint defined by the OpenAPI specification using purely natural language."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "a457106d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.tools import OpenAPISpec, APIOperation\n",
|
||||
"from langchain.chains import OpenAPIEndpointChain, LLMChain\n",
|
||||
"from langchain.requests import Requests\n",
|
||||
"from langchain.llms import OpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2c3b0954",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Load the API Chain\n",
|
||||
"\n",
|
||||
"Load a wrapper of the spec (so we can work with it more easily). You can load from a url or from a local file."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "794142ba",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Attempting to load an OpenAPI 3.0.1 spec. This may result in degraded performance. Convert your OpenAPI spec to 3.1.* spec for better support.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Load and parse the OpenAPI Spec\n",
|
||||
"spec = OpenAPISpec.from_url(\"https://www.klarna.com/us/shopping/public/openai/v0/api-docs/\")\n",
|
||||
"# Load a single endpoint operation\n",
|
||||
"operation = APIOperation.from_openapi_spec(spec, '/public/openai/v0/products', \"get\")\n",
|
||||
"verbose = False\n",
|
||||
"# Select any LangChain LLM\n",
|
||||
"llm = OpenAI()\n",
|
||||
"# Create the endpoint chain\n",
|
||||
"api_chain = OpenAPIEndpointChain.from_api_operation(\n",
|
||||
" operation, \n",
|
||||
" llm, \n",
|
||||
" requests=Requests(), \n",
|
||||
" verbose=verbose,\n",
|
||||
" return_intermediate_steps=True # Return request and response text\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6c05ba5b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### *Optional*: Generate Input Questions and Request Ground Truth Queries"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "a0c0cb7e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# import re\n",
|
||||
"# from langchain.prompts import PromptTemplate\n",
|
||||
"\n",
|
||||
"# template = \"\"\"Below is a service description:\n",
|
||||
"\n",
|
||||
"# {spec}\n",
|
||||
"\n",
|
||||
"# Imagine you're a new user trying to use {operation} through a search bar. What are 10 different things you want to request?\n",
|
||||
"# Wants/Questions:\n",
|
||||
"# 1. \"\"\"\n",
|
||||
"\n",
|
||||
"# prompt = PromptTemplate.from_template(template)\n",
|
||||
"\n",
|
||||
"# generation_chain = LLMChain(llm=llm, prompt=prompt)\n",
|
||||
"\n",
|
||||
"# questions_ = generation_chain.run(spec=operation.to_typescript(), operation=operation.operation_id).split('\\n')\n",
|
||||
"# # Strip preceding numeric bullets\n",
|
||||
"# questions = [re.sub(r'^\\d+\\. ', '', q).strip() for q in questions_]\n",
|
||||
"# questions"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "f3d767ef",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# ground_truths = [\n",
|
||||
"# {\"q\": ...} # What are the best queries for each input?\n",
|
||||
"# ]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "81098a05",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Run the API Chain\n",
|
||||
"\n",
|
||||
"The two simplest questions a user of the API Chain are:\n",
|
||||
"- Did the chain succesfully access the endpoint?\n",
|
||||
"- Did the action accomplish the correct result?\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "64bc7ed9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from collections import defaultdict\n",
|
||||
"# Collect metrics to report at completion\n",
|
||||
"scores = defaultdict(list)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "dfd2d09f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"questions = [\n",
|
||||
" 'What iPhone models are available?',\n",
|
||||
" 'Are there any budget laptops?',\n",
|
||||
" 'Show me the cheapest gaming PC.',\n",
|
||||
" 'Are there any tablets under $400?',\n",
|
||||
" 'What are the best headphones?',\n",
|
||||
" 'What are the top rated laptops?',\n",
|
||||
" 'I want to buy some shoes. I like Adidas and Nike.',\n",
|
||||
" 'I want to buy a new skirt',\n",
|
||||
" 'My company is asking me to get a professional Deskopt PC - money is no object.',\n",
|
||||
" 'What are the best budget cameras?'\n",
|
||||
"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "00511f7a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"## Run the the API chain itself\n",
|
||||
"chain_outputs = []\n",
|
||||
"failed_examples = []\n",
|
||||
"for question in questions:\n",
|
||||
" try:\n",
|
||||
" chain_outputs.append(api_chain(question))\n",
|
||||
" scores[\"completed\"].append(1.0)\n",
|
||||
" except Exception as e:\n",
|
||||
" failed_examples.append({'q': question, 'error': e})\n",
|
||||
" scores[\"completed\"].append(0.0)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "f3c9729f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[]"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# If the chain failed to run, show the failing examples\n",
|
||||
"failed_examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "914e7587",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['Currently, Apple iPhone 14 Pro Max 256GB, Apple iPhone 12 128GB, Apple iPhone 13 128GB, Apple iPhone 14 Pro 128GB, Apple iPhone 14 Pro 256GB, Apple iPhone 14 Pro Max 128GB, Apple iPhone 13 Pro Max 128GB, Apple iPhone 14 128GB, Apple iPhone 12 Pro 512GB, and Apple iPhone 12 mini 64GB models are available.',\n",
|
||||
" 'Yes, there are budget laptops available from the API response. For example, the HP 14-dq0055dx is priced at $199.99 and the HP 15-dw0083wm is priced at $244.99.',\n",
|
||||
" 'The Alarco Gaming PC (X_BLACK_GTX750) is the cheapest gaming PC listed at $499.99. You can find more information at this link: https://www.klarna.com/us/shopping/pl/cl223/3203154750/Desktop-Computers/Alarco-Gaming-PC-%28X_BLACK_GTX750%29/?utm_source=openai&ref-site=openai_plugin',\n",
|
||||
" 'Yes, there are several tablets under $400. You can find Apple iPad 10.2\" 32GB (2019) at $249.99, Samsung Galaxy Tab A8 10.5 SM-X200 32GB at $178.90, Samsung Galaxy Tab A7 Lite 8.7 SM-T220 32GB at $119.99, and Amazon Fire HD 8\" 32GB (10th Generation) at $44.99.',\n",
|
||||
" 'It depends on your needs and budget. The API response contains a list of headphones from Apple, Bose and Beats that range in price from $69.99 to $409.00. The headphones come with a variety of features, such as active noise cancelling and wireless connections, so you can find the perfect pair for your needs.',\n",
|
||||
" 'The top rated laptops from the API_RESPONSE are the Apple MacBook Air (2020) M1 OC 7C GPU 8GB 256GB SSD 13\", Apple MacBook Air (2022) M2 OC 8C GPU 8GB 256GB SSD 13.6\", Apple MacBook Pro (2020) M1 OC 8C GPU 8GB 256GB SSD 13\", and Apple MacBook Pro (2022) M2 OC 10C GPU 8GB 256GB SSD 13.3\".',\n",
|
||||
" \"It looks like you're interested in buying shoes from Nike and Adidas. From the API response, I can see that there are several Nike and UGG shoes available. You can click on the provided links to learn more and purchase the shoes if you're interested.\",\n",
|
||||
" 'I have found several skirts for you to choose from in the API response. Please click on the links to view more information about the product and available sizes.',\n",
|
||||
" 'Based on the API response, you should consider getting the CyberPowerPC Gamer Master Gaming Desktop as it features a powerful AMD Ryzen 5 processor and 16GB of DDR4 RAM, along with an Nvidia GeForce RTX 3060 graphics card and a 500GB SSD. It is also released in 2022 and comes with Windows 10 Home.',\n",
|
||||
" 'Based on the API response, the best budget cameras available are the DJI Mini 2 Dog Camera ($448.50), Insta360 Sphere with Landing Pad ($429.99), DJI FPV Gimbal Camera ($121.06), Parrot Camera & Body ($36.19), and the DJI FPV Air Unit ($179.00).']"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"answers = [res['output'] for res in chain_outputs]\n",
|
||||
"answers"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "484f0587",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Evaluate the requests chain\n",
|
||||
"\n",
|
||||
"The API Chain has two main components:\n",
|
||||
"1. Translate the user query to an API request\n",
|
||||
"2. Translate the API response to a natural language response\n",
|
||||
"\n",
|
||||
"Here, we construct an evaluation chain to grade the request synthesizer against selected human queries "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "3ea5afd7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"\n",
|
||||
"# Define ground truth labels\n",
|
||||
"truth_queries = [\n",
|
||||
" {\"q\": \"iPhone\"},\n",
|
||||
" {\"q\": \"laptop\", \"max_price\": 300},\n",
|
||||
" {\"q\": \"tablet\"},\n",
|
||||
" {\"q\": \"headphone\"},\n",
|
||||
" {\"q\": \"laptop\", \"max_price\": 400},\n",
|
||||
" {\"q\": \"shoe\"},\n",
|
||||
" {\"q\": \"skirt\"},\n",
|
||||
" {\"q\": \"professional desktop PC\", \"max_price\": 10000},\n",
|
||||
" {\"q\": \"camera\", \"max_price\": 300},\n",
|
||||
"]\n",
|
||||
"truth_queries = [json.dumps(q) for q in truth_queries]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "e055f24b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Collect the API queries generated by the chain\n",
|
||||
"predicted_queries = [output[\"intermediate_steps\"][\"request_args\"] for output in chain_outputs]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "7d4f2b88",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"\n",
|
||||
"template = \"\"\"You are trying to answer the following question by querying an API:\n",
|
||||
"\n",
|
||||
"> Question: {question}\n",
|
||||
"\n",
|
||||
"The query you know you should be executing against the API is:\n",
|
||||
"\n",
|
||||
"> Query: {truth_query}\n",
|
||||
"\n",
|
||||
"Is the following predicted query semantically the same (eg likely to produce the same answer)?\n",
|
||||
"\n",
|
||||
"> Predicted Query: {predict_query}\n",
|
||||
"\n",
|
||||
"Please give the Predicted Query a grade of either an A, B, C, D, or F, along with an explanation of why. End the evaluation with 'Final Grade: <the letter>'\n",
|
||||
"\n",
|
||||
"> Explanation: Let's think step by step.\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = PromptTemplate.from_template(template)\n",
|
||||
"\n",
|
||||
"eval_chain = LLMChain(llm=llm, prompt=prompt, verbose=verbose)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "8cc1b1db",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[' \\nThe original query is asking for all iPhone models, so the \"size\" parameter is not necessary. The same goes for the min_price and max_price parameters, since these are not relevant to the question being asked. \\nTherefore, the predicted query is not semantically the same as the original query and is not likely to produce the same answer. \\nFinal Grade: F',\n",
|
||||
" ' The query has the same keyword of \"laptops,\" which is semantically the same as the original query, so that\\'s a plus. However, the maximum price is 500, which is more than double the original maximum price of 300. This means that the predicted query is likely to yield more results than the original query, which may or may not include budget laptops. For this reason, I would give the predicted query a Grade B. Final Grade: B',\n",
|
||||
" \" The first part of the query - 'gaming PC' - is semantically the same as the original query, so that's an A. However, the next parts of the query - the size, min_price, and max_price - are not related to the original query and do not provide any useful information, so these get a D. Final Grade: D\",\n",
|
||||
" ' The first part of the query, \"q\": \"tablet\", is asking the API to look for tablets. The second part, \"size\": 10, is asking the API to return 10 results. The third part, \"min_price\": 0, is asking the API to return results with a minimum price of 0, and the fourth part, \"max_price\": 400, is asking the API to return results with a maximum price of 400. All of these parts of the query are relevant to the original question, so this query is semantically the same as the original. \\n\\nFinal Grade: A',\n",
|
||||
" ' The original query is asking for laptops and the max price is 400. The predicted query is asking for headphones and the min and max prices are 0 and 1000 respectively. The predicted query is off topic and could give a range of results that are not necessarily the best headphones. Therefore, the predicted query is not semantically the same and is not likely to produce the same answer as the original query. Final Grade: F',\n",
|
||||
" ' The original query was simply \"shoe,\" which is very broad and unlikely to give accurate results. The predicted query is looking for laptops, specifying a size of 5, and a price range of $0-$9999. While this query is a bit more specific than the original query, it still fails to provide any information about the laptops. It is missing a rating system or any other criteria to determine which laptops are the \"top rated.\" Therefore, I would give the predicted query a grade of D as it is more specific than the original, but still fails to provide all the necessary information to accurately answer the question. Final Grade: D',\n",
|
||||
" ' The original question asked for shoes and specified two brands, Adidas and Nike. The predicted query is asking for shoes, but it is also asking for a size and a minimum/maximum price range. While these parameters might help narrow down the results returned, they do not answer the original question. Therefore, the predicted query is not semantically the same as the original query. Final Grade: F',\n",
|
||||
" ' The original query was for a professional desktop PC with a maximum price of $10,000. The predicted query is for a skirt with a size of 10 and a minimum and maximum price of $0 and $500, respectively. The two queries are not semantically the same as they are asking for different items with different specifications. Final Grade: F',\n",
|
||||
" ' The original query was asking for a \"camera\" with a maximum price of $300. The predicted query is asking for a \"deskopt pc\" with a minimum price of $0 and no maximum price, as well as a size of 10. The two queries are not semantically the same, as the original query is asking for specific information about a camera, whereas the predicted query is asking for the same type of product but with different parameters. As such, I would give this query a grade of D. Final Grade: D']"
|
||||
]
|
||||
},
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"request_eval_results = []\n",
|
||||
"for question, predict_query, truth_query in list(zip(questions, predicted_queries, truth_queries)):\n",
|
||||
" eval_output = eval_chain.run(\n",
|
||||
" question=question,\n",
|
||||
" truth_query=truth_query,\n",
|
||||
" predict_query=predict_query,\n",
|
||||
" )\n",
|
||||
" request_eval_results.append(eval_output)\n",
|
||||
"request_eval_results"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "0d76f8ba",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import re\n",
|
||||
"from typing import List\n",
|
||||
"# Parse the evaluation chain responses into a rubric\n",
|
||||
"def parse_eval_results(results: List[str]) -> List[float]:\n",
|
||||
" rubric = {\n",
|
||||
" \"A\": 1.0,\n",
|
||||
" \"B\": 0.75,\n",
|
||||
" \"C\": 0.5,\n",
|
||||
" \"D\": 0.25,\n",
|
||||
" \"F\": 0\n",
|
||||
" }\n",
|
||||
" return [rubric[re.search(r'Final Grade: (\\w+)', res).group(1)] for res in results]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"parsed_results = parse_eval_results(request_eval_results)\n",
|
||||
"# Collect the scores for a final evaluation table\n",
|
||||
"scores['request_synthesizer'].extend(parsed_results)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6f3ee8ea",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Evaluate the Response Chain\n",
|
||||
"\n",
|
||||
"The second component translated the structured API response to a natural language response.\n",
|
||||
"Evaluate this against the user's original question."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"id": "8b97847c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"\n",
|
||||
"template = \"\"\"You are trying to answer the following question by querying an API:\n",
|
||||
"\n",
|
||||
"> Question: {question}\n",
|
||||
"\n",
|
||||
"The API returned a response of:\n",
|
||||
"\n",
|
||||
"> API result: {api_response}\n",
|
||||
"\n",
|
||||
"Your response to the user: {answer}\n",
|
||||
"\n",
|
||||
"Please evaluate the accuracy and utility of your response to the user's original question, conditioned on the information available.\n",
|
||||
"Give a letter grade of either an A, B, C, D, or F, along with an explanation of why. End the evaluation with 'Final Grade: <the letter>'\n",
|
||||
"\n",
|
||||
"> Explanation: Let's think step by step.\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = PromptTemplate.from_template(template)\n",
|
||||
"\n",
|
||||
"eval_chain = LLMChain(llm=llm, prompt=prompt, verbose=verbose)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "642852ce",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Extract the API responses from the chain\n",
|
||||
"api_responses = [output[\"intermediate_steps\"][\"response_text\"] for output in chain_outputs]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "08a5eb4f",
|
||||
"metadata": {
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[' \\nThe original query is asking for all iPhone models, so the \"size\" parameter is not necessary. The same goes for the min_price and max_price parameters, since these are not relevant to the question being asked. \\nTherefore, the predicted query is not semantically the same as the original query and is not likely to produce the same answer. \\nFinal Grade: F',\n",
|
||||
" ' The query has the same keyword of \"laptops,\" which is semantically the same as the original query, so that\\'s a plus. However, the maximum price is 500, which is more than double the original maximum price of 300. This means that the predicted query is likely to yield more results than the original query, which may or may not include budget laptops. For this reason, I would give the predicted query a Grade B. Final Grade: B',\n",
|
||||
" \" The first part of the query - 'gaming PC' - is semantically the same as the original query, so that's an A. However, the next parts of the query - the size, min_price, and max_price - are not related to the original query and do not provide any useful information, so these get a D. Final Grade: D\",\n",
|
||||
" ' The first part of the query, \"q\": \"tablet\", is asking the API to look for tablets. The second part, \"size\": 10, is asking the API to return 10 results. The third part, \"min_price\": 0, is asking the API to return results with a minimum price of 0, and the fourth part, \"max_price\": 400, is asking the API to return results with a maximum price of 400. All of these parts of the query are relevant to the original question, so this query is semantically the same as the original. \\n\\nFinal Grade: A',\n",
|
||||
" ' The original query is asking for laptops and the max price is 400. The predicted query is asking for headphones and the min and max prices are 0 and 1000 respectively. The predicted query is off topic and could give a range of results that are not necessarily the best headphones. Therefore, the predicted query is not semantically the same and is not likely to produce the same answer as the original query. Final Grade: F',\n",
|
||||
" ' The original query was simply \"shoe,\" which is very broad and unlikely to give accurate results. The predicted query is looking for laptops, specifying a size of 5, and a price range of $0-$9999. While this query is a bit more specific than the original query, it still fails to provide any information about the laptops. It is missing a rating system or any other criteria to determine which laptops are the \"top rated.\" Therefore, I would give the predicted query a grade of D as it is more specific than the original, but still fails to provide all the necessary information to accurately answer the question. Final Grade: D',\n",
|
||||
" ' The original question asked for shoes and specified two brands, Adidas and Nike. The predicted query is asking for shoes, but it is also asking for a size and a minimum/maximum price range. While these parameters might help narrow down the results returned, they do not answer the original question. Therefore, the predicted query is not semantically the same as the original query. Final Grade: F',\n",
|
||||
" ' The original query was for a professional desktop PC with a maximum price of $10,000. The predicted query is for a skirt with a size of 10 and a minimum and maximum price of $0 and $500, respectively. The two queries are not semantically the same as they are asking for different items with different specifications. Final Grade: F',\n",
|
||||
" ' The original query was asking for a \"camera\" with a maximum price of $300. The predicted query is asking for a \"deskopt pc\" with a minimum price of $0 and no maximum price, as well as a size of 10. The two queries are not semantically the same, as the original query is asking for specific information about a camera, whereas the predicted query is asking for the same type of product but with different parameters. As such, I would give this query a grade of D. Final Grade: D',\n",
|
||||
" ' The user asked for an answer to the question \"What iPhone models are available?\" The API provided a response containing a list of 10 iPhone models. The response accurately provides the user with the models that are currently available. Therefore, the answer provided is complete, accurate, and useful.\\n\\nFinal Grade: A',\n",
|
||||
" \" Does the response answer the user's question? Yes, the response provides a list of budget laptops and their prices. Is the information provided accurate? Yes, the information provided is accurate and matches the API response. Is the response useful? Yes, the response provides the user with a list of budget laptops and their prices.\\nFinal Grade: A\",\n",
|
||||
" ' The question was \"Show me the cheapest gaming PC.\" The API returned a result of the Alarco Gaming PC (X_BLACK_GTX750) at a price of $499.99. The response to the user accurately answered their question by citing the name of the cheapest gaming PC and its price. The response also included a link to the product page for more information. Therefore, the response meets the criteria of an A grade. Final Grade: A',\n",
|
||||
" ' First, the answer to the user\\'s question is \"Yes,\" which is accurate. Second, the API results provided are relevant to the user\\'s question, as all products are tablets and all are under $400. Finally, the response provides four specific examples of tablets under $400, which provides helpful detail to the user. Overall, this response is accurate and provides useful information to the user. Final Grade: A',\n",
|
||||
" \" First, the response accurately answers the user's question by providing a list of headphones and their features. Second, it also provides a range of prices and explains that it depends on the user's needs and budget. The response is comprehensive and provides enough information to the user to make an informed decision.\\n\\nFinal Grade: A\",\n",
|
||||
" ' The user asked for the top rated laptops, and the API response gave us a list of 5 laptops. The response provided all the relevant information about each laptop, such as the specs and price. This response is accurate and provides the necessary information to help the user make an informed decision. Final Grade: A',\n",
|
||||
" ' The user asked for shoes from Adidas and Nike, and the API response provided links to shoes from both brands, so the accuracy of the response is good. The response also provides helpful information such as product name, price, and attributes, which makes the response useful. Therefore, I would give this response a grade of A.\\n\\nFinal Grade: A',\n",
|
||||
" ' The API response was relevant and provided detailed information about the products. The response is accurate and provides useful information. The response also provides links to the products, which is very helpful for the user. All these factors give this response an A. Final Grade: A',\n",
|
||||
" \" The user asked for a professional Desktop PC with no budget restrictions. The API response provided several options from different brands, with varying features. The CyberPowerPC Gamer Master Gaming Desktop in particular offers impressive specs, such as an AMD Ryzen 5 processor, 16GB of DDR4 RAM, an Nvidia GeForce RTX 3060 graphics card and a 500GB SSD, as well as being released in 2022 and coming with Windows 10 Home. Therefore, this option should meet the user's requirements and provides the best value for money.\\n\\nFinal Grade: A\",\n",
|
||||
" ' First, the API returned the information asked for. The response contains the names, URLs, and prices of five budget cameras. Then, the response was properly interpreted by the user, and all the information in the response was relayed accurately. As a result, this response fully answers the original question of what are the best budget cameras, so the accuracy of the response is high. In addition, the response is useful to the user, as it provides an accurate list of the best budget cameras in one place. Final Grade: A.']"
|
||||
]
|
||||
},
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Run the grader chain\n",
|
||||
"response_eval_results = []\n",
|
||||
"for question, api_response, answer in list(zip(questions, api_responses, answers)):\n",
|
||||
" request_eval_results.append(eval_chain.run(question=question, api_response=api_response, answer=answer))\n",
|
||||
"request_eval_results"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "a144aa9d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Reusing the rubric from above, parse the evaluation chain responses\n",
|
||||
"parsed_response_results = parse_eval_results(request_eval_results)\n",
|
||||
"# Collect the scores for a final evaluation table\n",
|
||||
"scores['result_synthesizer'].extend(parsed_response_results)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "e95042bc",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Metric \tMin \tMean \tMax \n",
|
||||
"completed \t1.00 \t1.00 \t1.00 \n",
|
||||
"request_synthesizer \t0.00 \t0.28 \t1.00 \n",
|
||||
"result_synthesizer \t0.00 \t0.66 \t1.00 \n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Print out Score statistics for the evaluation session\n",
|
||||
"header = \"{:<20}\\t{:<10}\\t{:<10}\\t{:<10}\".format(\"Metric\", \"Min\", \"Mean\", \"Max\")\n",
|
||||
"print(header)\n",
|
||||
"for metric, metric_scores in scores.items():\n",
|
||||
" mean_scores = sum(metric_scores) / len(metric_scores) if len(metric_scores) > 0 else float('nan')\n",
|
||||
" row = \"{:<20}\\t{:<10.2f}\\t{:<10.2f}\\t{:<10.2f}\".format(metric, min(metric_scores), mean_scores, max(metric_scores))\n",
|
||||
" print(row)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"id": "03fe96af",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[]"
|
||||
]
|
||||
},
|
||||
"execution_count": 20,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Re-show the examples for which the chain failed to complete\n",
|
||||
"failed_examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "0ee43877",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
Loading…
Reference in New Issue