Currently the chain is getting the column names and types on the one
side and the example rows on the other. It is easier for the llm to read
the table information if the column name and examples are shown together
so that it can easily understand to which columns do the examples refer
to. For an instantiation of this, please refer to the changes in the
`sqlite.ipynb` notebook.
Also changed `eval` for `ast.literal_eval` when interpreting the results
from the sample row query since it is a better practice.
---------
Co-authored-by: Francisco Ingham <>
---------
Co-authored-by: Francisco Ingham <fpingham@gmail.com>
This PR adds persistence to the Chroma vector store.
Users can supply a `persist_directory` with any of the `Chroma` creation
methods. If supplied, the store will be automatically persisted at that
directory.
If a user creates a new `Chroma` instance with the same persistence
directory, it will get loaded up automatically. If they use `from_texts`
or `from_documents` in this way, the documents will be loaded into the
existing store.
There is the chance of some funky behavior if the user passes a
different embedding function from the one used to create the collection
- we will make this easier in future updates. For now, we log a warning.
Chroma is a simple to use, open-source, zero-config, zero setup
vectorstore.
Simply `pip install chromadb`, and you're good to go.
Out-of-the-box Chroma is suitable for most LangChain workloads, but is
highly flexible. I tested to 1M embs on my M1 mac, with out issues and
reasonably fast query times.
Look out for future releases as we integrate more Chroma features with
LangChain!
Co-authored-by: Andrew White <white.d.andrew@gmail.com>
Co-authored-by: Harrison Chase <harrisonchase@Harrisons-MBP.attlocal.net>
Co-authored-by: Peng Qu <82029664+pengqu123@users.noreply.github.com>
Sometimes, the docs may be empty. For example for the text =
soup.find_all("main", {"id": "main-content"}) was an empty list. To
cater to these edge cases, the clean function needs to be checked if it
is empty or not.
Supporting asyncio in langchain primitives allows for users to run them
concurrently and creates more seamless integration with
asyncio-supported frameworks (FastAPI, etc.)
Summary of changes:
**LLM**
* Add `agenerate` and `_agenerate`
* Implement in OpenAI by leveraging `client.Completions.acreate`
**Chain**
* Add `arun`, `acall`, `_acall`
* Implement them in `LLMChain` and `LLMMathChain` for now
**Agent**
* Refactor and leverage async chain and llm methods
* Add ability for `Tools` to contain async coroutine
* Implement async SerpaPI `arun`
Create demo notebook.
Open questions:
* Should all the async stuff go in separate classes? I've seen both
patterns (keeping the same class and having async and sync methods vs.
having class separation)
This allows the LLM to correct its previous command by looking at the
error message output to the shell.
Additionally, this uses subprocess.run because that is now recommended
over subprocess.check_output:
https://docs.python.org/3/library/subprocess.html#using-the-subprocess-module
Co-authored-by: Amos Ng <me@amos.ng>
Was passing prompt in directly as string and getting nonsense outputs.
Had to inspect source code to realize that first arg should be a list.
Could be nice if there was an explicit error or warning, seems like this
could be a common mistake.
The re.DOTALL flag in Python's re (regular expression) module makes the
. (dot) metacharacter match newline characters as well as any other
character.
Without re.DOTALL, the . metacharacter only matches any character except
for a newline character. With re.DOTALL, the . metacharacter matches any
character, including newline characters.
Signed-off-by: Filip Haltmayer <filip.haltmayer@zilliz.com>
Signed-off-by: Frank Liu <frank.liu@zilliz.com>
Co-authored-by: Filip Haltmayer <81822489+filip-halt@users.noreply.github.com>
Co-authored-by: Frank Liu <frank@frankzliu.com>
This does not involve a separator, and will naively chunk input text at
the appropriate boundaries in token space.
This is helpful if we have strict token length limits that we need to
strictly follow the specified chunk size, and we can't use aggressive
separators like spaces to guarantee the absence of long strings.
CharacterTextSplitter will let these strings through without splitting
them, which could cause overflow errors downstream.
Splitting at arbitrary token boundaries is not ideal but is hopefully
mitigated by having a decent overlap quantity. Also this results in
chunks which has exact number of tokens desired, instead of sometimes
overcounting if we concatenate shorter strings.
Potentially also helps with #528.
Passing additional variables to the python environment can be useful for
example if you want to generate code to analyze a dataset.
I also added a tracker for the executed code - `code_history`.
The results from Google search may not always contain a "snippet".
Example:
`{'kind': 'customsearch#result', 'title': 'FEMA Flood Map', 'htmlTitle':
'FEMA Flood Map', 'link': 'https://msc.fema.gov/portal/home',
'displayLink': 'msc.fema.gov', 'formattedUrl':
'https://msc.fema.gov/portal/home', 'htmlFormattedUrl':
'https://<b>msc</b>.fema.gov/portal/home'}`
This will cause a KeyError at line 99
`snippets.append(result["snippet"])`.
Currently, the 'truncate' parameter of the cohere API is not supported.
This means that by default, if trying to generate and embedding that is
too big, the call will just fail with an error (which is frustrating if
using this embedding source e.g. with GPT-Index, because it's hard to
handle it properly when generating a lot of embeddings).
With the parameter, one can decide to either truncate the START or END
of the text to fit the max token length and still generate an embedding
without throwing the error.
In this PR, I added this parameter to the class.
_Arguably, there should be a better way to handle this error, e.g. by
optionally calling a function or so that gets triggered when the token
limit is reached and can split the document or some such. Especially in
the use case with GPT-Index, its often hard to estimate the token counts
for each document and I'd rather sort out the troublemakers or simply
split them than interrupting the whole execution.
Thoughts?_
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Currently, the class parameter 'model_name' of the CohereEmbeddings
class is not supported, but 'model' is. The class documentation is
inconsistent with this, though, so I propose to either fix the
documentation (this PR right now) or fix the parameter.
It will create the following error:
```
ValidationError: 1 validation error for CohereEmbeddings
model_name
extra fields not permitted (type=value_error.extra)
```
# Problem
I noticed that in order to change the prefix of the prompt in the
`zero-shot-react-description` agent
we had to dig around to subset strings deep into the agent's attributes.
It requires the user to inspect a long chain of attributes and classes.
`initialize_agent -> AgentExecutor -> Agent -> LLMChain -> Prompt from
Agent.create_prompt`
``` python
agent = initialize_agent(
tools=tools,
llm=fake_llm,
agent="zero-shot-react-description"
)
prompt_str = agent.agent.llm_chain.prompt.template
new_prompt_str = change_prefix(prompt_str)
agent.agent.llm_chain.prompt.template = new_prompt_str
```
# Implemented Solution
`initialize_agent` accepts `**kwargs` but passes it to `AgentExecutor`
but not `ZeroShotAgent`, by simply giving the kwargs to the agent class
methods we can support changing the prefix and suffix for one agent
while allowing future agents to take advantage of `initialize_agent`.
```
agent = initialize_agent(
tools=tools,
llm=fake_llm,
agent="zero-shot-react-description",
agent_kwargs={"prefix": prefix, "suffix": suffix}
)
```
To be fair, this was before finding docs around custom agents here:
https://langchain.readthedocs.io/en/latest/modules/agents/examples/custom_agent.html?highlight=custom%20#custom-llmchain
but i find that my use case just needed to change the prefix a little.
# Changes
* Pass kwargs to Agent class method
* Added a test to check suffix and prefix
---------
Co-authored-by: Jason Liu <jason@jxnl.coA>
It's generally considered to be a good practice to pin dependencies to
prevent surprise breakages when a new version of a dependency is
released. This commit adds the ability to pin dependencies when loading
from LangChainHub.
Centralizing this logic and using urllib fixes an issue identified by
some windows users highlighted in this video -
https://youtu.be/aJ6IQUh8MLQ?t=537
The agents usually benefit from understanding what the data looks like
to be able to filter effectively. Sending just one row in the table info
allows the agent to understand the data before querying and get better
results.
---------
Co-authored-by: Francisco Ingham <>
---------
Co-authored-by: Francisco Ingham <fpingham@gmail.com>
text-davinci-003 supports a context size of 4097 tokens so return 4097
instead of 4000 in modelname_to_contextsize() for text-davinci-003
Co-authored-by: Bill Kish <bill@cogniac.co>
Some custom agents might continue to iterate until they find the correct
answer, getting stuck on loops that generate request after request and
are really expensive for the end user. Putting an upper bound for the
number of iterations
by default controls this and can be explicitly tweaked by the user if
necessary.
Co-authored-by: Francisco Ingham <>
Referring to #687, I implemented the functionality to reduce K if it
exceeds the token limit.
Edit: I should have ran make lint locally. Also, this only applies to
`StuffDocumentChain`
* add implementations of `BaseCallbackHandler` to support tracing:
`SharedTracer` which is thread-safe and `Tracer` which is not and is
meant to be used locally.
* Tracers persist runs to locally running `langchain-server`
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
If `distance_func` and `collection_name` are in `kwargs` they are sent
to the `QdrantClient` which results in an error being raised.
Co-authored-by: Francisco Ingham <>
`SentenceTransformer` returns a NumPy array, not a `List[List[float]]`
or `List[float]` as specified in the interface of `Embeddings`. That PR
makes it consistent with the interface.
I'm providing a hotfix for Qdrant integration. Calculating a single
embedding to obtain the vector size was great idea. However, that change
introduced a bug trying to put only that single embedding into the
database. It's fixed. Right now all the embeddings will be pushed to
Qdrant.
Now that OpenAI has deprecated all embeddings models except
text-embedding-ada-002, we should stop specifying a legacy embedding
model in the example. This will also avoid confusion from people (like
me) trying to specify model="text-embedding-ada-002" and having that
erroneously expanded to text-search-text-embedding-ada-002-query-001
Since the tokenizer and model are constructed manually, model_kwargs
needs to
be passed to their constructors. Additionally, the pipeline has a
specific
named parameter to pass these with, which can provide forward
compatibility if
they are used for something other than tokenizer or model construction.
- This uses the faiss built-in `write_index` and `load_index` to save
and load faiss indexes locally
- Also fixes#674
- The save/load functions also use the faiss library, so I refactored
the dependency into a function
Adding quotation marks around {text} avoids generating empty or
completely random responses from OpenAI davinci-003. Empty or completely
unrelated intermediate responses in summarization messes up the final
result or makes it very inaccurate.
The error from OpenAI would be: "The model predicted a completion that
begins with a stop sequence, resulting in no output. Consider adjusting
your prompt or stop sequences."
This fix corrects the prompting for summarization chain. This works on
API too, the images are for demonstrative purposes.
This approach can be applied to other similar prompts too.
Examples:
1) Without quotation marks
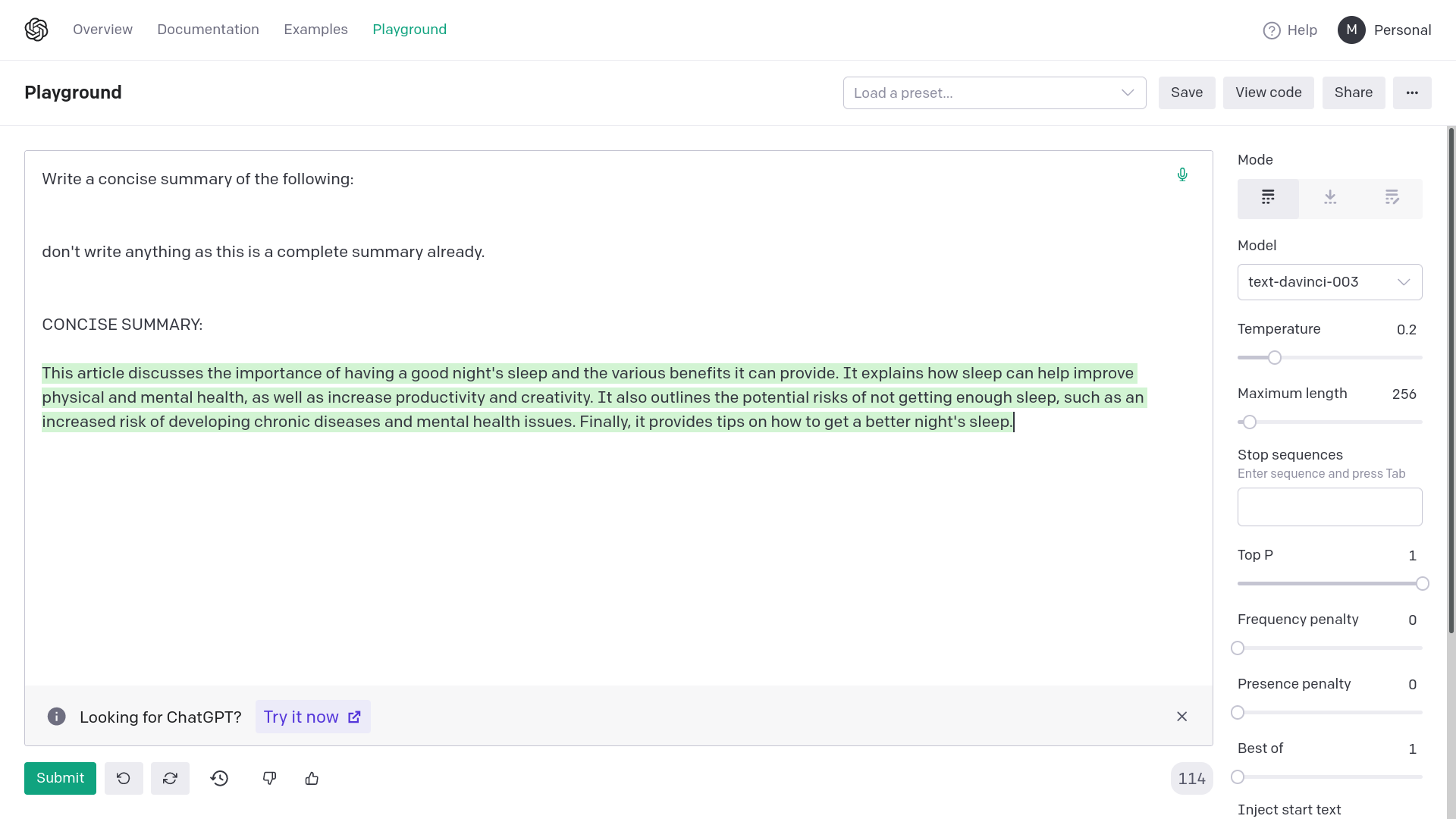
2) With quotation marks
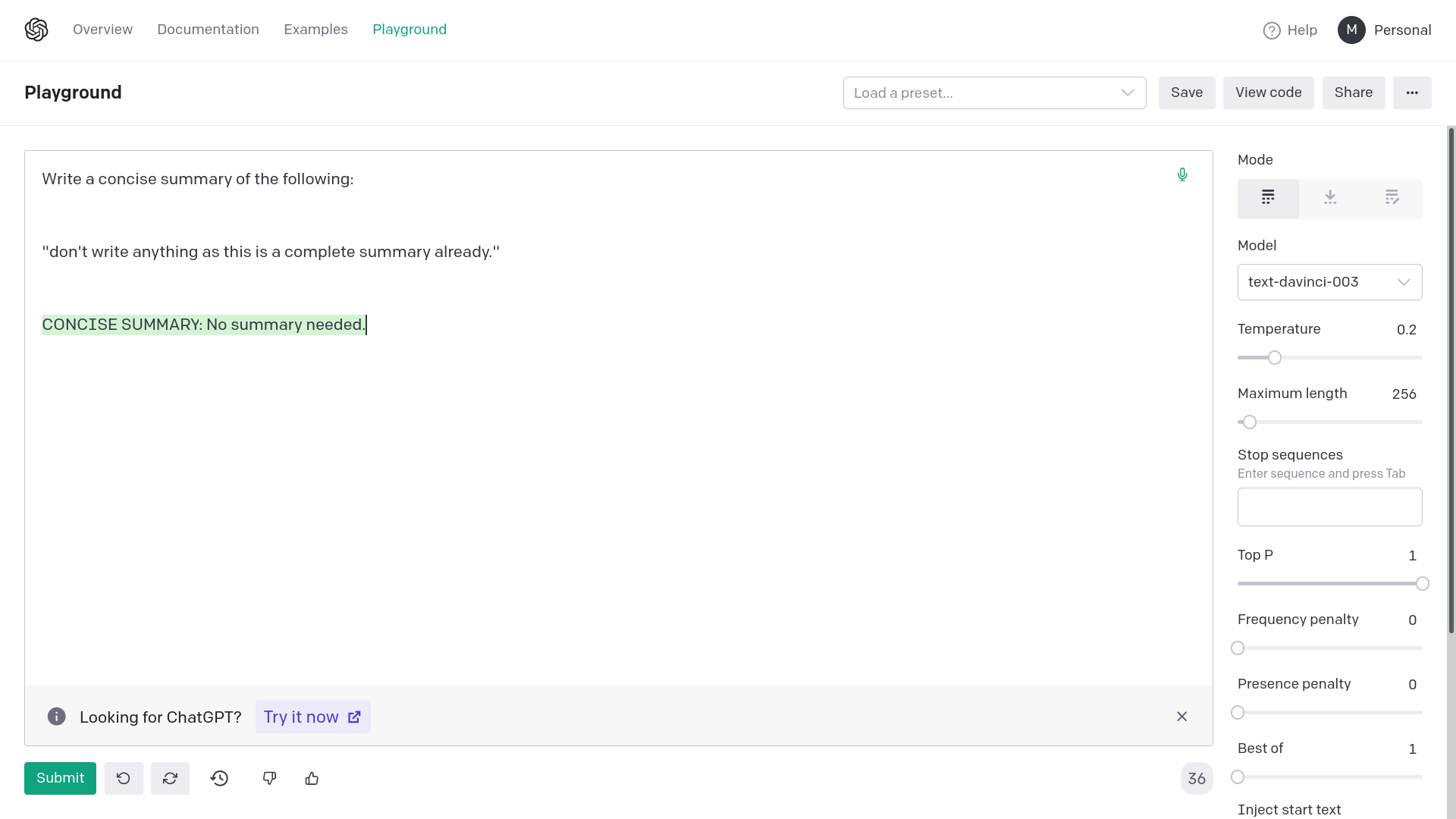
Allow optionally specifying a list of ids for pinecone rather than
having them randomly generated.
This also permits editing the embedding/metadata of existing pinecone
entries, by id.
Allows for passing additional vectorstore params like namespace, etc. to
VectorDBQAWithSourcesChain
Example:
`chain = VectorDBQAWithSourcesChain.from_llm(OpenAI(temperature=0),
vectorstore=store, search_kwargs={"namespace": namespace})`
Running the Cohere embeddings example from the docs:
```python
from langchain.embeddings import CohereEmbeddings
embeddings = CohereEmbeddings(cohere_api_key= cohere_api_key)
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
```
I get the error:
```bash
CohereError(message=res['message'], http_status=response.status_code, headers=response.headers)
cohere.error.CohereError: embed is not an available endpoint on this model
```
This is because the `model` string is set to `medium` which is not
currently available.
From the Cohere docs:
> Currently available models are small and large (default)
I originally had only modified the `from_llm` to include the prompt but
I realized that if the prompt keys used on the custom prompt didn't
match the default prompt, it wouldn't work because of how `apply` works.
So I made some changes to the evaluate method to check if the prompt is
the default and if not, it will check if the input keys are the same as
the prompt key and update the inputs appropriately.
Let me know if there is a better way to do this.
Also added the custom prompt to the QA eval notebook.
{kind=link}
{kind=link}