**Description:** Batch update of alt text and title attributes for images in `md` & `mdx` files across the repo using [alttexter](https://github.com/jonathanalgar/alttexter)/[alttexter-ghclient](https://github.com/jonathanalgar/alttexter-ghclient) (built using LangChain/LangSmith). **Limitation:** cannot update `ipynb` files because of [this issue](https://github.com/langchain-ai/langchain/pull/15357#issuecomment-1885037250). Can revisit when Docusaurus is bumped to v3. I checked all the generated alt texts and titles and didn't find any technical inaccuracies. That's not to say they're _perfect_, but a lot better than what's there currently. [Deployed](https://langchain-819yf1tbk-langchain.vercel.app/docs/modules/model_io/) image example: 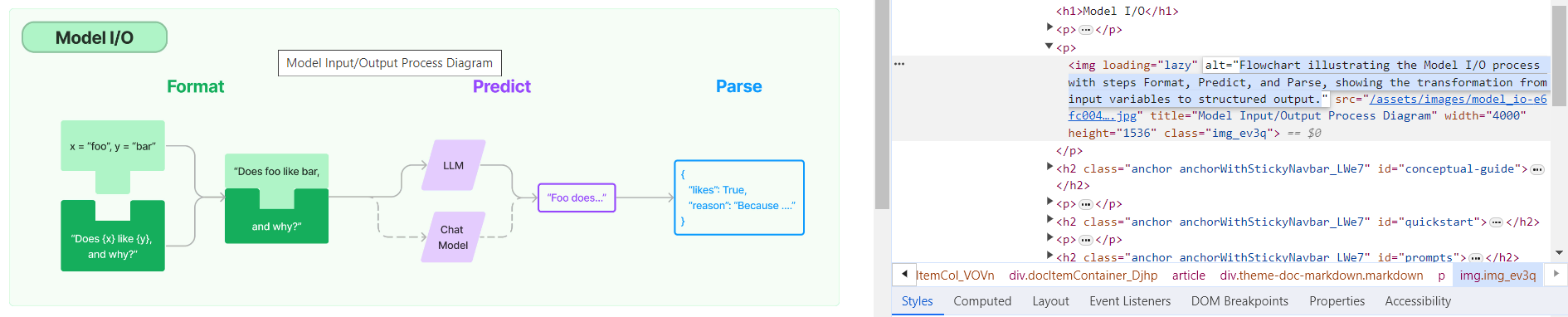 You can see LangSmith traces for all the calls out to the LLM in the PRs merged into this one: * https://github.com/jonathanalgar/langchain/pull/6 * https://github.com/jonathanalgar/langchain/pull/4 * https://github.com/jonathanalgar/langchain/pull/3 I didn't add the following files to the PR as the images already have OK alt texts: *27dca2d92f/docs/docs/integrations/providers/argilla.mdx (L3)*27dca2d92f/docs/docs/integrations/providers/apify.mdx (L11)--------- Co-authored-by: github-actions <github-actions@github.com>
4.2 KiB
rag-multi-modal-local
Visual search is a famililar application to many with iPhones or Android devices. It allows user to serch photos using natural language.
With the release of open source, multi-modal LLMs it's possible to build this kind of application for yourself for your own private photo collection.
This template demonstrates how to perform private visual search and question-answering over a collection of your photos.
It uses OpenCLIP embeddings to embed all of the photos and stores them in Chroma.
Given a question, relevat photos are retrieved and passed to an open source multi-modal LLM of your choice for answer synthesis.
Input
Supply a set of photos in the /docs directory.
By default, this template has a toy collection of 3 food pictures.
Example questions to ask can be:
What kind of soft serve did I have?
In practice, a larger corpus of images can be tested.
To create an index of the images, run:
poetry install
python ingest.py
Storage
This template will use OpenCLIP multi-modal embeddings to embed the images.
You can select different embedding model options (see results here).
The first time you run the app, it will automatically download the multimodal embedding model.
By default, LangChain will use an embedding model with moderate performance but lower memory requirments, ViT-H-14.
You can choose alternative OpenCLIPEmbeddings models in rag_chroma_multi_modal/ingest.py:
vectorstore_mmembd = Chroma(
collection_name="multi-modal-rag",
persist_directory=str(re_vectorstore_path),
embedding_function=OpenCLIPEmbeddings(
model_name="ViT-H-14", checkpoint="laion2b_s32b_b79k"
),
)
LLM
This template will use Ollama.
Download the latest version of Ollama: https://ollama.ai/
Pull the an open source multi-modal LLM: e.g., https://ollama.ai/library/bakllava
ollama pull bakllava
The app is by default configured for bakllava. But you can change this in chain.py and ingest.py for different downloaded models.
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package rag-chroma-multi-modal
If you want to add this to an existing project, you can just run:
langchain app add rag-chroma-multi-modal
And add the following code to your server.py file:
from rag_chroma_multi_modal import chain as rag_chroma_multi_modal_chain
add_routes(app, rag_chroma_multi_modal_chain, path="/rag-chroma-multi-modal")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. LangSmith is currently in private beta, you can sign up here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you are inside this directory, then you can spin up a LangServe instance directly by:
langchain serve
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/rag-chroma-multi-modal/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/rag-chroma-multi-modal")