mirror of https://github.com/hwchase17/langchain
Batch update of alt text and title attributes for images in md/mdx files across repo (#15357)
**Description:** Batch update of alt text and title attributes for images in `md` & `mdx` files across the repo using [alttexter](https://github.com/jonathanalgar/alttexter)/[alttexter-ghclient](https://github.com/jonathanalgar/alttexter-ghclient) (built using LangChain/LangSmith). **Limitation:** cannot update `ipynb` files because of [this issue](https://github.com/langchain-ai/langchain/pull/15357#issuecomment-1885037250). Can revisit when Docusaurus is bumped to v3. I checked all the generated alt texts and titles and didn't find any technical inaccuracies. That's not to say they're _perfect_, but a lot better than what's there currently. [Deployed](https://langchain-819yf1tbk-langchain.vercel.app/docs/modules/model_io/) image example: 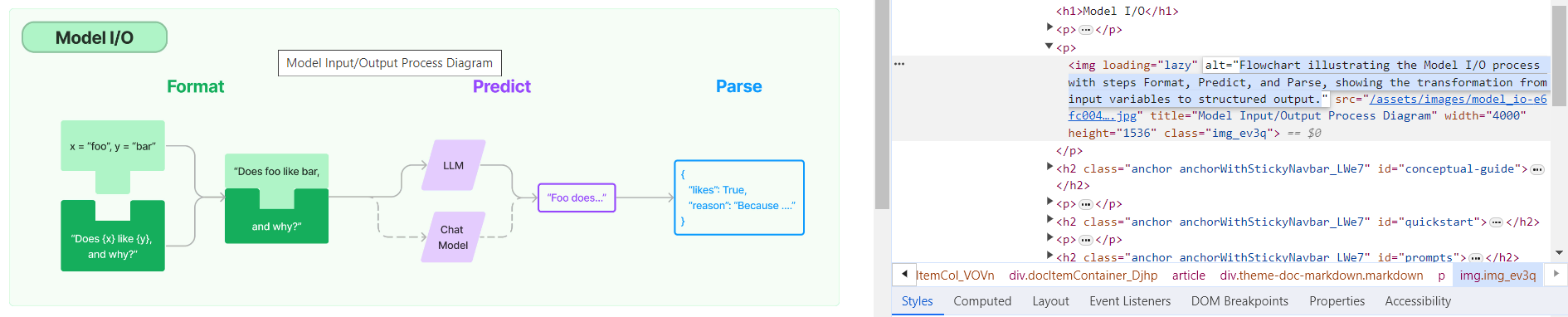 You can see LangSmith traces for all the calls out to the LLM in the PRs merged into this one: * https://github.com/jonathanalgar/langchain/pull/6 * https://github.com/jonathanalgar/langchain/pull/4 * https://github.com/jonathanalgar/langchain/pull/3 I didn't add the following files to the PR as the images already have OK alt texts: *pull/15971/head^227dca2d92f/docs/docs/integrations/providers/argilla.mdx (L3)*27dca2d92f/docs/docs/integrations/providers/apify.mdx (L11)--------- Co-authored-by: github-actions <github-actions@github.com>
parent
efe6cfafe2
commit
a74f3a4979
Loading…
Reference in New Issue