mirror of
https://github.com/hwchase17/langchain
synced 2024-11-02 09:40:22 +00:00
**Description:** Batch update of alt text and title attributes for images in `md` & `mdx` files across the repo using [alttexter](https://github.com/jonathanalgar/alttexter)/[alttexter-ghclient](https://github.com/jonathanalgar/alttexter-ghclient) (built using LangChain/LangSmith). **Limitation:** cannot update `ipynb` files because of [this issue](https://github.com/langchain-ai/langchain/pull/15357#issuecomment-1885037250). Can revisit when Docusaurus is bumped to v3. I checked all the generated alt texts and titles and didn't find any technical inaccuracies. That's not to say they're _perfect_, but a lot better than what's there currently. [Deployed](https://langchain-819yf1tbk-langchain.vercel.app/docs/modules/model_io/) image example: 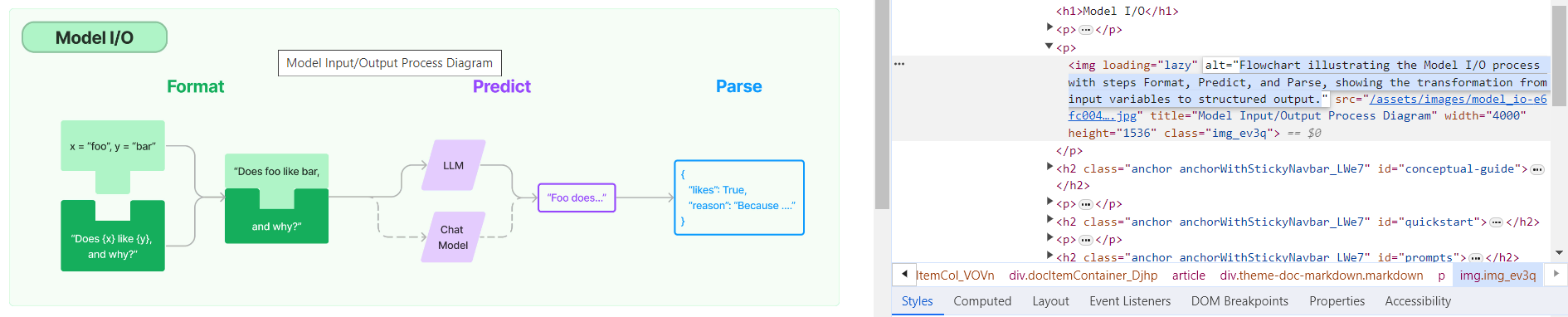 You can see LangSmith traces for all the calls out to the LLM in the PRs merged into this one: * https://github.com/jonathanalgar/langchain/pull/6 * https://github.com/jonathanalgar/langchain/pull/4 * https://github.com/jonathanalgar/langchain/pull/3 I didn't add the following files to the PR as the images already have OK alt texts: *27dca2d92f/docs/docs/integrations/providers/argilla.mdx (L3)*27dca2d92f/docs/docs/integrations/providers/apify.mdx (L11)--------- Co-authored-by: github-actions <github-actions@github.com>
179 lines
5.6 KiB
Markdown
179 lines
5.6 KiB
Markdown
# mongo-parent-document-retrieval
|
|
|
|
This template performs RAG using MongoDB and OpenAI.
|
|
It does a more advanced form of RAG called Parent-Document Retrieval.
|
|
|
|
In this form of retrieval, a large document is first split into medium sized chunks.
|
|
From there, those medium size chunks are split into small chunks.
|
|
Embeddings are created for the small chunks.
|
|
When a query comes in, an embedding is created for that query and compared to the small chunks.
|
|
But rather than passing the small chunks directly to the LLM for generation, the medium-sized chunks
|
|
from whence the smaller chunks came are passed.
|
|
This helps enable finer-grained search, but then passing of larger context (which can be useful during generation).
|
|
|
|
## Environment Setup
|
|
|
|
You should export two environment variables, one being your MongoDB URI, the other being your OpenAI API KEY.
|
|
If you do not have a MongoDB URI, see the `Setup Mongo` section at the bottom for instructions on how to do so.
|
|
|
|
```shell
|
|
export MONGO_URI=...
|
|
export OPENAI_API_KEY=...
|
|
```
|
|
|
|
## Usage
|
|
|
|
To use this package, you should first have the LangChain CLI installed:
|
|
|
|
```shell
|
|
pip install -U langchain-cli
|
|
```
|
|
|
|
To create a new LangChain project and install this as the only package, you can do:
|
|
|
|
```shell
|
|
langchain app new my-app --package mongo-parent-document-retrieval
|
|
```
|
|
|
|
If you want to add this to an existing project, you can just run:
|
|
|
|
```shell
|
|
langchain app add mongo-parent-document-retrieval
|
|
```
|
|
|
|
And add the following code to your `server.py` file:
|
|
```python
|
|
from mongo_parent_document_retrieval import chain as mongo_parent_document_retrieval_chain
|
|
|
|
add_routes(app, mongo_parent_document_retrieval_chain, path="/mongo-parent-document-retrieval")
|
|
```
|
|
|
|
(Optional) Let's now configure LangSmith.
|
|
LangSmith will help us trace, monitor and debug LangChain applications.
|
|
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
|
If you don't have access, you can skip this section
|
|
|
|
|
|
```shell
|
|
export LANGCHAIN_TRACING_V2=true
|
|
export LANGCHAIN_API_KEY=<your-api-key>
|
|
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
|
```
|
|
|
|
If you DO NOT already have a Mongo Search Index you want to connect to, see `MongoDB Setup` section below before proceeding.
|
|
Note that because Parent Document Retrieval uses a different indexing strategy, it's likely you will want to run this new setup.
|
|
|
|
If you DO have a MongoDB Search index you want to connect to, edit the connection details in `mongo_parent_document_retrieval/chain.py`
|
|
|
|
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
|
|
|
```shell
|
|
langchain serve
|
|
```
|
|
|
|
This will start the FastAPI app with a server is running locally at
|
|
[http://localhost:8000](http://localhost:8000)
|
|
|
|
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
|
We can access the playground at [http://127.0.0.1:8000/mongo-parent-document-retrieval/playground](http://127.0.0.1:8000/mongo-parent-document-retrieval/playground)
|
|
|
|
We can access the template from code with:
|
|
|
|
```python
|
|
from langserve.client import RemoteRunnable
|
|
|
|
runnable = RemoteRunnable("http://localhost:8000/mongo-parent-document-retrieval")
|
|
```
|
|
|
|
For additional context, please refer to [this notebook](https://colab.research.google.com/drive/1cr2HBAHyBmwKUerJq2if0JaNhy-hIq7I#scrollTo=TZp7_CBfxTOB).
|
|
|
|
|
|
## MongoDB Setup
|
|
|
|
Use this step if you need to setup your MongoDB account and ingest data.
|
|
We will first follow the standard MongoDB Atlas setup instructions [here](https://www.mongodb.com/docs/atlas/getting-started/).
|
|
|
|
1. Create an account (if not already done)
|
|
2. Create a new project (if not already done)
|
|
3. Locate your MongoDB URI.
|
|
|
|
This can be done by going to the deployement overview page and connecting to you database
|
|
|
|

|
|
|
|
We then look at the drivers available
|
|
|
|

|
|
|
|
Among which we will see our URI listed
|
|
|
|

|
|
|
|
Let's then set that as an environment variable locally:
|
|
|
|
```shell
|
|
export MONGO_URI=...
|
|
```
|
|
|
|
4. Let's also set an environment variable for OpenAI (which we will use as an LLM)
|
|
|
|
```shell
|
|
export OPENAI_API_KEY=...
|
|
```
|
|
|
|
5. Let's now ingest some data! We can do that by moving into this directory and running the code in `ingest.py`, eg:
|
|
|
|
```shell
|
|
python ingest.py
|
|
```
|
|
|
|
Note that you can (and should!) change this to ingest data of your choice
|
|
|
|
6. We now need to set up a vector index on our data.
|
|
|
|
We can first connect to the cluster where our database lives
|
|
|
|

|
|
|
|
We can then navigate to where all our collections are listed
|
|
|
|

|
|
|
|
We can then find the collection we want and look at the search indexes for that collection
|
|
|
|

|
|
|
|
That should likely be empty, and we want to create a new one:
|
|
|
|

|
|
|
|
We will use the JSON editor to create it
|
|
|
|

|
|
|
|
And we will paste the following JSON in:
|
|
|
|
```text
|
|
{
|
|
"mappings": {
|
|
"dynamic": true,
|
|
"fields": {
|
|
"doc_level": [
|
|
{
|
|
"type": "token"
|
|
}
|
|
],
|
|
"embedding": {
|
|
"dimensions": 1536,
|
|
"similarity": "cosine",
|
|
"type": "knnVector"
|
|
}
|
|
}
|
|
}
|
|
}
|
|
```
|
|

|
|
|
|
From there, hit "Next" and then "Create Search Index". It will take a little bit but you should then have an index over your data!
|
|
|