- downgraded to python 3.10 to accomadate installing all dependencies
- by default installs all dev + extra dependencies
- option to install only dev dependencies by customizing .env file
separate makefile and build env:
- separate makefile for docker
- only show docker commands when docker detected in system
- only rebuild container on change
- use an unpriviliged user
builder image and base dev image:
- fully isolated environment inside container.
- all venv installed inside container shell and available as commands.
- ex: `docker run IMG jupyter notebook` to launch notebook.
- pure python based container without poetry.
- custom motd to add a message displayed to users when they connect to
container.
- print environment versions (git, package, python) on login
- display help message when starting container
iFixit is a wikipedia-like site that has a huge amount of open content
on how to fix things, questions/answers for common troubleshooting and
"things" related content that is more technical in nature. All content
is licensed under CC-BY-SA-NC 3.0
Adding docs from iFixit as context for user questions like "I dropped my
phone in water, what do I do?" or "My macbook pro is making a whining
noise, what's wrong with it?" can yield significantly better responses
than context free response from LLMs.
### Summary
Adds a document loader for image files such as `.jpg` and `.png` files.
### Testing
Run the following using the example document from the [`unstructured`
repo](https://github.com/Unstructured-IO/unstructured/tree/main/example-docs).
```python
from langchain.document_loaders.image import UnstructuredImageLoader
loader = UnstructuredImageLoader("layout-parser-paper-fast.jpg")
loader.load()
```
- run and exec_run need a separate default command. Run usually executes
a script while exec_run simulates an interactive session. The image
templates and run funcs have been upgraded to handle both
types of commands.
- test: make docker tests run when docker is installed and docker lib
avaialble.
- test that runsc runtime is used by default when gVisor is installed.
(manually removing gVisor skips the test)
- quickly run or exec_run commands with sane defaults
- wip image templates with parameters for common docker images
- shell escaping logic
- capture stdout+stderr for exec commands
- added minimal testing
nitpicking but just thought i'd add this typo which I found when going
through the How-to 😄 (unless it was intentional) also, it's amazing that
you added ReAct to LangChain!
Checking if weaviate similarity_search kwargs contains "certainty" and
use it accordingly. The minimal level of certainty must be a float, and
it is computed by normalized distance.
While using a `SQLiteCache`, if there are duplicate `(prompt, llm, idx)`
tuples passed to
[`update_cache()`](c5dd491a21/langchain/llms/base.py (L39)),
then an `IntegrityError` is thrown. This can happen when there are
duplicated prompts within the same batch.
This PR changes the SQLAlchemy `session.add()` to a `session.merge()` in
`cache.py`, [following the solution from this SO
thread](https://stackoverflow.com/questions/10322514/dealing-with-duplicate-primary-keys-on-insert-in-sqlalchemy-declarative-style).
I believe this fixes#983, but not entirely sure since that also
involves async
Here's a minimal example of the error:
```python
from pathlib import Path
import langchain
from langchain.cache import SQLiteCache
llm = langchain.OpenAI(model_name="text-ada-001", openai_api_key=Path("/.openai_api_key").read_text().strip())
langchain.llm_cache = SQLiteCache("test_cache.db")
llm.generate(['a'] * 5)
```
```
> IntegrityError: (sqlite3.IntegrityError) UNIQUE constraint failed: full_llm_cache.prompt, full_llm_cache.llm, full_llm_cache.idx
[SQL: INSERT INTO full_llm_cache (prompt, llm, idx, response) VALUES (?, ?, ?, ?)]
[parameters: ('a', "[('_type', 'openai'), ('best_of', 1), ('frequency_penalty', 0), ('logit_bias', {}), ('max_tokens', 256), ('model_name', 'text-ada-001'), ('n', 1), ('presence_penalty', 0), ('request_timeout', None), ('stop', None), ('temperature', 0.7), ('top_p', 1)]", 0, '\n\nA is for air.\n\nA is for atmosphere.')]
(Background on this error at: https://sqlalche.me/e/14/gkpj)
```
After the change, we now have the following
```python
class Output:
def __init__(self, text):
self.text = text
# make dummy data
cache = SQLiteCache("test_cache_2.db")
cache.update(prompt="prompt_0", llm_string="llm_0", return_val=[Output("text_0")])
cache.engine.execute("SELECT * FROM full_llm_cache").fetchall()
# output
> [('prompt_0', 'llm_0', 0, 'text_0')]
```
```python
# update data, before change this would have thrown an `IntegrityError`
cache.update(prompt="prompt_0", llm_string="llm_0", return_val=[Output("text_0_new")])
cache.engine.execute("SELECT * FROM full_llm_cache").fetchall()
# output
> [('prompt_0', 'llm_0', 0, 'text_0_new')]
```
Thanks for all your hard work!
I noticed a small typo in the bash util doc so here's a quick update.
Additionally, my formatter caught some spacing in the `.md` as well.
Happy to revert that if it's an issue.
The main change is just
```
- A common use case this is for letting it interact with your local file system.
+ A common use case for this is letting the LLM interact with your local file system.
```
## Testing
`make docs_build` succeeds locally and the changes show as expected ✌️
<img width="704" alt="image"
src="https://user-images.githubusercontent.com/17773666/221376160-e99e59a6-b318-49d1-a1d7-89f5c17cdab4.png">
I've added a simple
[CoNLL-U](https://universaldependencies.org/format.html) document
loader. CoNLL-U is a common format for NLP tasks and is used, for
example, in the Universal Dependencies treebank corpora. The loader
reads a single file in standard CoNLL-U format and returns a document.
### Summary
Adds a document loader for MS Word Documents. Works with both `.docx`
and `.doc` files as longer as the user has installed
`unstructured>=0.4.11`.
### Testing
The follow workflow test the loader for both `.doc` and `.docx` files
using example docs from the `unstructured` repo.
#### `.docx`
```python
from langchain.document_loaders import UnstructuredWordDocumentLoader
filename = "../unstructured/example-docs/fake.docx"
loader = UnstructuredWordDocumentLoader(filename)
loader.load()
```
#### `.doc`
```python
from langchain.document_loaders import UnstructuredWordDocumentLoader
filename = "../unstructured/example-docs/fake.doc"
loader = UnstructuredWordDocumentLoader(filename)
loader.load()
```
`NotebookLoader.load()` loads the `.ipynb` notebook file into a
`Document` object.
**Parameters**:
* `include_outputs` (bool): whether to include cell outputs in the
resulting document (default is False).
* `max_output_length` (int): the maximum number of characters to include
from each cell output (default is 10).
* `remove_newline` (bool): whether to remove newline characters from the
cell sources and outputs (default is False).
* `traceback` (bool): whether to include full traceback (default is
False).
### Summary
Updates the docs to remove the `nltk` download steps from
`unstructured`. As of `unstructured` `0.4.14`, this is handled
automatically in the relevant modules within `unstructured`.
The current prompt specifically instructs the LLM to use the `LIMIT`
clause. This will cause issues with MS SQL Server, which uses `SELECT
TOP` instead of `LIMIT`. The generated SQL will use `LIMIT`; the
instruction to "always limit... using the LIMIT clause" seems to
override the "create a syntactically correct mssql query to run"
portion. Reported here:
https://github.com/hwchase17/langchain/issues/1103#issuecomment-1441144224
I don't have access to a SQL Server instance to test, but removing that
part of the prompt in OpenAI Playground results in the correct `SELECT
TOP` syntax, whereas keeping it in results in the `LIMIT` clause, even
when instructing it to generate syntactically correct mssql. It's also
still correctly using `LIMIT` in my MariaDB database. I think in this
case we can assume that the model will select the appropriate method
based on the dialect specified.
In general, it would be nice to be able to test a suite of SQL dialects
for things like dialect-specific syntax and other issues we've run into
in the past, but I'm not quite sure how to best approach that yet.
Link for easier navigation (it's not immediately clear where to find
more info on SimpleSequentialChain (3 clicks away)
---------
Co-authored-by: Larry Fisherman <l4rryfisherman@protonmail.com>
With the current method used to get the SQL table info, sqlite internal
schema tables are being included and are not being handled correctly by
sqlalchemy because the columns have no types. This is easy to see with
the Chinook database:
```python
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.table_info)
```
```python
...
sqlalchemy.exc.CompileError: (in table 'sqlite_sequence', column 'name'): Can't generate DDL for NullType(); did you forget to specify a type on this Column?
```
SQLAlchemy 2.0 [ignores these by
default](63d90b0f44/lib/sqlalchemy/dialects/sqlite/base.py (L856-L880)):
63d90b0f44/lib/sqlalchemy/dialects/sqlite/base.py (L2096-L2123)
When I try to import the Class HuggingFaceEndpoint I get an Import
Error: cannot import name 'HuggingFaceEndpoint' from 'langchain'.
(langchain version 0.0.88)
These two imports work fine: from langchain import HuggingFacePipeline
and from langchain import HuggingFaceHub.
So I corrected the import statement in the example. There is probably a
better solution to this, but this fixes the Error for me.
It is useful to be able to specify `verbose` or `memory` while still
keeping the chain's overall structure.
---------
Co-authored-by: Francisco Ingham <>
Added a GitBook document loader. It lets you both, (1) fetch text from
any single GitBook page, or (2) fetch all relative paths and return
their respective content in Documents.
I've modified the `scrape` method in the `WebBaseLoader` to accept
custom web paths if given, but happy to remove it and move that logic
into the `GitbookLoader` itself.
### Description
This PR adds a wrapper which adds support for the OpenSearch vector
database. Using opensearch-py client we are ingesting the embeddings of
given text into opensearch cluster using Bulk API. We can perform the
`similarity_search` on the index using the 3 popular searching methods
of OpenSearch k-NN plugin:
- `Approximate k-NN Search` use approximate nearest neighbor (ANN)
algorithms from the [nmslib](https://github.com/nmslib/nmslib),
[faiss](https://github.com/facebookresearch/faiss), and
[Lucene](https://lucene.apache.org/) libraries to power k-NN search.
- `Script Scoring` extends OpenSearch’s script scoring functionality to
execute a brute force, exact k-NN search.
- `Painless Scripting` adds the distance functions as painless
extensions that can be used in more complex combinations. Also, supports
brute force, exact k-NN search like Script Scoring.
### Issues Resolved
https://github.com/hwchase17/langchain/issues/1054
---------
Signed-off-by: Naveen Tatikonda <navtat@amazon.com>
Follow-up of @hinthornw's PR:
- Migrate the Tool abstraction to a separate file (`BaseTool`).
- `Tool` implementation of `BaseTool` takes in function and coroutine to
more easily maintain backwards compatibility
- Add a Toolkit abstraction that can own the generation of tools around
a shared concept or state
---------
Co-authored-by: William FH <13333726+hinthornw@users.noreply.github.com>
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Co-authored-by: Francisco Ingham <fpingham@gmail.com>
Co-authored-by: Dhruv Anand <105786647+dhruv-anand-aintech@users.noreply.github.com>
Co-authored-by: cragwolfe <cragcw@gmail.com>
Co-authored-by: Anton Troynikov <atroyn@users.noreply.github.com>
Co-authored-by: Oliver Klingefjord <oliver@klingefjord.com>
Co-authored-by: William Fu-Hinthorn <whinthorn@Williams-MBP-3.attlocal.net>
Co-authored-by: Bruno Bornsztein <bruno.bornsztein@gmail.com>
In the similarity search, the pinecone namespace is not used, which
makes the bot return _I don't know_ where the embeddings are stored in
the pinecone namespace. Now we can query by passing the namespace
optionally.
```result = qa({"question": query, "chat_history": chat_history, "namespace":"01gshyhjcfgkq1q5wxjtm17gjh"})```
This approach has several advantages:
* it improves the readability of the code
* removes incompatibilities between SQL dialects
* fixes a bug with `datetime` values in rows and `ast.literal_eval`
Huge thanks and credits to @jzluo for finding the weaknesses in the
current approach and for the thoughtful discussion on the best way to
implement this.
---------
Co-authored-by: Francisco Ingham <>
Co-authored-by: Jon Luo <20971593+jzluo@users.noreply.github.com>
Pydantic validation breaks tests for example (`test_qdrant.py`) because
fake embeddings contain an integer.
This PR casts the embeddings array to all floats.
Now the `qdrant` test passes, `poetry run pytest
tests/integration_tests/vectorstores/test_qdrant.py`
Implementation fails if there are not enough documents. Added the same
check as used for similarity search.
Current implementation raises
```
File ".venv/lib/python3.9/site-packages/langchain/vectorstores/faiss.py", line 160, in max_marginal_relevance_search
_id = self.index_to_docstore_id[i]
KeyError: -1
```
#1081 introduced a method to get DDL (table definitions) in a manner
specific to sqlite3, thus breaking compatibility with other non-sqlite3
databases. This uses the sqlite3 command if the detected dialect is
sqlite, and otherwise uses the standard SQL `SHOW CREATE TABLE`. This
should fix#1103.
Fix KeyError 'items' when no result found.
## Problem
When no result found for a query, google search crashed with `KeyError
'items'`.
## Solution
I added a check for an empty response before accessing the 'items' key.
It will handle the case correctly.
## Other
my twitter: yakigac
(I don't mind even if you don't mention me for this PR. But just because
last time my real name was shout out :) )
### Summary
Adds support for older `.ppt` file in the PowerPoint loader.
### Testing
The following should work on `unstructured==0.4.11` using the example
docs from the `unstructured` repo.
```python
from langchain.document_loaders import UnstructuredPowerPointLoader
filename = "../unstructured/example-docs/fake-power-point.pptx"
loader = UnstructuredPowerPointLoader(filename)
loader.load()
filename = "../unstructured/example-docs/fake-power-point.ppt"
loader = UnstructuredPowerPointLoader(filename)
loader.load()
```
Now downgrade `unstructured` to version `0.4.10`. The following should
work:
```python
from langchain.document_loaders import UnstructuredPowerPointLoader
filename = "../unstructured/example-docs/fake-power-point.pptx"
loader = UnstructuredPowerPointLoader(filename)
loader.load()
```
and the following should give you a `ValueError` and invite you to
upgrade `unstructured`.
```python
from langchain.document_loaders import UnstructuredPowerPointLoader
filename = "../unstructured/example-docs/fake-power-point.ppt"
loader = UnstructuredPowerPointLoader(filename)
loader.load()
```
https://github.com/hwchase17/langchain/issues/1100
When faiss data and doc.index are created in past versions, error occurs
that say there was no attribute. So I put hasattr in the check as a
simple solution.
However, increasing the number of such checks is not good for
conservatism, so I think there is a better solution.
Also, the code for the batch process was left out, so I put it back in.
This import works fine:
```python
from langchain import Anthropic
```
This import does not:
```python
from langchain import AI21
```
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'AI21' from 'langchain' (/opt/anaconda3/envs/fed_nlp/lib/python3.9/site-packages/langchain/__init__.py)
```
I think there is a slight documentation inconsistency here:
https://langchain.readthedocs.io/en/latest/reference/modules/llms.html
This PR starts to solve that. Should all the import examples be
`from langchain.llms import X` instead of `from langchain import X`?
The #1088 introduced a bug in Qdrant integration. That PR reverts those
changes and provides class attributes to ensure consistent payload keys.
In addition to that, an exception will be thrown if any of texts is None
(that could have been an issue reported in #1087)
This is a work in progress PR to track my progres.
## TODO:
- [x] Get results using the specifed searx host
- [x] Prioritize returning an `answer` or results otherwise
- [ ] expose the field `infobox` when available
- [ ] expose `score` of result to help agent's decision
- [ ] expose the `suggestions` field to agents so they could try new
queries if no results are found with the orignial query ?
- [ ] Dynamic tool description for agents ?
- Searx offers many engines and a search syntax that agents can take
advantage of. It would be nice to generate a dynamic Tool description so
that it can be used many times as a tool but for different purposes.
- [x] Limit number of results
- [ ] Implement paging
- [x] Miror the usage of the Google Search tool
- [x] easy selection of search engines
- [x] Documentation
- [ ] update HowTo guide notebook on Search Tools
- [ ] Handle async
- [ ] Tests
### Add examples / documentation on possible uses with
- [ ] getting factual answers with `!wiki` option and `infoboxes`
- [ ] getting `suggestions`
- [ ] getting `corrections`
---------
Co-authored-by: blob42 <spike@w530>
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Alternate implementation to PR #960 Again - only FAISS is implemented.
If accepted can add this to other vectorstores or leave as
NotImplemented? Suggestions welcome...
This PR updates `PromptLayerOpenAI` to now support requests using the
[Async
API](https://langchain.readthedocs.io/en/latest/modules/llms/async_llm.html)
It also updates the documentation on Async API to let users know that
PromptLayerOpenAI also supports this.
`PromptLayerOpenAI` now redefines `_agenerate` a similar was to how it
redefines `_generate`
Adds Google Search integration with [Serper](https://serper.dev) a
low-cost alternative to SerpAPI (10x cheaper + generous free tier).
Includes documentation, tests and examples. Hopefully I am not missing
anything.
Developers can sign up for a free account at
[serper.dev](https://serper.dev) and obtain an api key.
## Usage
```python
from langchain.utilities import GoogleSerperAPIWrapper
from langchain.llms.openai import OpenAI
from langchain.agents import initialize_agent, Tool
import os
os.environ["SERPER_API_KEY"] = ""
os.environ['OPENAI_API_KEY'] = ""
llm = OpenAI(temperature=0)
search = GoogleSerperAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run
)
]
self_ask_with_search = initialize_agent(tools, llm, agent="self-ask-with-search", verbose=True)
self_ask_with_search.run("What is the hometown of the reigning men's U.S. Open champion?")
```
### Output
```
Entering new AgentExecutor chain...
Yes.
Follow up: Who is the reigning men's U.S. Open champion?
Intermediate answer: Current champions Carlos Alcaraz, 2022 men's singles champion.
Follow up: Where is Carlos Alcaraz from?
Intermediate answer: El Palmar, Spain
So the final answer is: El Palmar, Spain
> Finished chain.
'El Palmar, Spain'
```
This PR updates the usage instructions for PromptLayerOpenAI in
Langchain's documentation. The updated instructions provide more detail
and conform better to the style of other LLM integration documentation
pages.
No code changes were made in this PR, only improvements to the
documentation. This update will make it easier for users to understand
how to use `PromptLayerOpenAI`
### Summary
Adds tracked metadata from `unstructured` elements to the document
metadata when `UnstructuredFileLoader` is used in `"elements"` mode.
Tracked metadata is available in `unstructured>=0.4.9`, but the code is
written for backward compatibility with older `unstructured` versions.
### Testing
Before running, make sure to upgrade to `unstructured==0.4.9`. In the
code snippet below, you should see `page_number`, `filename`, and
`category` in the metadata for each document. `doc[0]` should have
`page_number: 1` and `doc[-1]` should have `page_number: 2`. The example
document is `layout-parser-paper-fast.pdf` from the [`unstructured`
sample
docs](https://github.com/Unstructured-IO/unstructured/tree/main/example-docs).
```python
from langchain.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader(file_path=f"layout-parser-paper-fast.pdf", mode="elements")
docs = loader.load()
```
Currently the chain is getting the column names and types on the one
side and the example rows on the other. It is easier for the llm to read
the table information if the column name and examples are shown together
so that it can easily understand to which columns do the examples refer
to. For an instantiation of this, please refer to the changes in the
`sqlite.ipynb` notebook.
Also changed `eval` for `ast.literal_eval` when interpreting the results
from the sample row query since it is a better practice.
---------
Co-authored-by: Francisco Ingham <>
---------
Co-authored-by: Francisco Ingham <fpingham@gmail.com>
This PR adds persistence to the Chroma vector store.
Users can supply a `persist_directory` with any of the `Chroma` creation
methods. If supplied, the store will be automatically persisted at that
directory.
If a user creates a new `Chroma` instance with the same persistence
directory, it will get loaded up automatically. If they use `from_texts`
or `from_documents` in this way, the documents will be loaded into the
existing store.
There is the chance of some funky behavior if the user passes a
different embedding function from the one used to create the collection
- we will make this easier in future updates. For now, we log a warning.
Chroma is a simple to use, open-source, zero-config, zero setup
vectorstore.
Simply `pip install chromadb`, and you're good to go.
Out-of-the-box Chroma is suitable for most LangChain workloads, but is
highly flexible. I tested to 1M embs on my M1 mac, with out issues and
reasonably fast query times.
Look out for future releases as we integrate more Chroma features with
LangChain!
The provided example uses the default `max_length` of `20` tokens, which
leads to the example generation getting cut off. 20 tokens is way too
short to show CoT reasoning, so I boosted it to `64`.
Without knowing HF's API well, it can be hard to figure out just where
those `model_kwargs` come from, and `max_length` is a super critical
one.
Co-authored-by: Andrew White <white.d.andrew@gmail.com>
Co-authored-by: Harrison Chase <harrisonchase@Harrisons-MBP.attlocal.net>
Co-authored-by: Peng Qu <82029664+pengqu123@users.noreply.github.com>
Sometimes, the docs may be empty. For example for the text =
soup.find_all("main", {"id": "main-content"}) was an empty list. To
cater to these edge cases, the clean function needs to be checked if it
is empty or not.
Supporting asyncio in langchain primitives allows for users to run them
concurrently and creates more seamless integration with
asyncio-supported frameworks (FastAPI, etc.)
Summary of changes:
**LLM**
* Add `agenerate` and `_agenerate`
* Implement in OpenAI by leveraging `client.Completions.acreate`
**Chain**
* Add `arun`, `acall`, `_acall`
* Implement them in `LLMChain` and `LLMMathChain` for now
**Agent**
* Refactor and leverage async chain and llm methods
* Add ability for `Tools` to contain async coroutine
* Implement async SerpaPI `arun`
Create demo notebook.
Open questions:
* Should all the async stuff go in separate classes? I've seen both
patterns (keeping the same class and having async and sync methods vs.
having class separation)
This allows the LLM to correct its previous command by looking at the
error message output to the shell.
Additionally, this uses subprocess.run because that is now recommended
over subprocess.check_output:
https://docs.python.org/3/library/subprocess.html#using-the-subprocess-module
Co-authored-by: Amos Ng <me@amos.ng>
PR to fix outdated environment details in the docs, see issue #897
I added code comments as pointers to where users go to get API keys, and
where they can find the relevant environment variable.
Was passing prompt in directly as string and getting nonsense outputs.
Had to inspect source code to realize that first arg should be a list.
Could be nice if there was an explicit error or warning, seems like this
could be a common mistake.
The re.DOTALL flag in Python's re (regular expression) module makes the
. (dot) metacharacter match newline characters as well as any other
character.
Without re.DOTALL, the . metacharacter only matches any character except
for a newline character. With re.DOTALL, the . metacharacter matches any
character, including newline characters.
Signed-off-by: Filip Haltmayer <filip.haltmayer@zilliz.com>
Signed-off-by: Frank Liu <frank.liu@zilliz.com>
Co-authored-by: Filip Haltmayer <81822489+filip-halt@users.noreply.github.com>
Co-authored-by: Frank Liu <frank@frankzliu.com>
This does not involve a separator, and will naively chunk input text at
the appropriate boundaries in token space.
This is helpful if we have strict token length limits that we need to
strictly follow the specified chunk size, and we can't use aggressive
separators like spaces to guarantee the absence of long strings.
CharacterTextSplitter will let these strings through without splitting
them, which could cause overflow errors downstream.
Splitting at arbitrary token boundaries is not ideal but is hopefully
mitigated by having a decent overlap quantity. Also this results in
chunks which has exact number of tokens desired, instead of sometimes
overcounting if we concatenate shorter strings.
Potentially also helps with #528.
Passing additional variables to the python environment can be useful for
example if you want to generate code to analyze a dataset.
I also added a tracker for the executed code - `code_history`.
The results from Google search may not always contain a "snippet".
Example:
`{'kind': 'customsearch#result', 'title': 'FEMA Flood Map', 'htmlTitle':
'FEMA Flood Map', 'link': 'https://msc.fema.gov/portal/home',
'displayLink': 'msc.fema.gov', 'formattedUrl':
'https://msc.fema.gov/portal/home', 'htmlFormattedUrl':
'https://<b>msc</b>.fema.gov/portal/home'}`
This will cause a KeyError at line 99
`snippets.append(result["snippet"])`.
Currently, the 'truncate' parameter of the cohere API is not supported.
This means that by default, if trying to generate and embedding that is
too big, the call will just fail with an error (which is frustrating if
using this embedding source e.g. with GPT-Index, because it's hard to
handle it properly when generating a lot of embeddings).
With the parameter, one can decide to either truncate the START or END
of the text to fit the max token length and still generate an embedding
without throwing the error.
In this PR, I added this parameter to the class.
_Arguably, there should be a better way to handle this error, e.g. by
optionally calling a function or so that gets triggered when the token
limit is reached and can split the document or some such. Especially in
the use case with GPT-Index, its often hard to estimate the token counts
for each document and I'd rather sort out the troublemakers or simply
split them than interrupting the whole execution.
Thoughts?_
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Currently, the class parameter 'model_name' of the CohereEmbeddings
class is not supported, but 'model' is. The class documentation is
inconsistent with this, though, so I propose to either fix the
documentation (this PR right now) or fix the parameter.
It will create the following error:
```
ValidationError: 1 validation error for CohereEmbeddings
model_name
extra fields not permitted (type=value_error.extra)
```
# Problem
I noticed that in order to change the prefix of the prompt in the
`zero-shot-react-description` agent
we had to dig around to subset strings deep into the agent's attributes.
It requires the user to inspect a long chain of attributes and classes.
`initialize_agent -> AgentExecutor -> Agent -> LLMChain -> Prompt from
Agent.create_prompt`
``` python
agent = initialize_agent(
tools=tools,
llm=fake_llm,
agent="zero-shot-react-description"
)
prompt_str = agent.agent.llm_chain.prompt.template
new_prompt_str = change_prefix(prompt_str)
agent.agent.llm_chain.prompt.template = new_prompt_str
```
# Implemented Solution
`initialize_agent` accepts `**kwargs` but passes it to `AgentExecutor`
but not `ZeroShotAgent`, by simply giving the kwargs to the agent class
methods we can support changing the prefix and suffix for one agent
while allowing future agents to take advantage of `initialize_agent`.
```
agent = initialize_agent(
tools=tools,
llm=fake_llm,
agent="zero-shot-react-description",
agent_kwargs={"prefix": prefix, "suffix": suffix}
)
```
To be fair, this was before finding docs around custom agents here:
https://langchain.readthedocs.io/en/latest/modules/agents/examples/custom_agent.html?highlight=custom%20#custom-llmchain
but i find that my use case just needed to change the prefix a little.
# Changes
* Pass kwargs to Agent class method
* Added a test to check suffix and prefix
---------
Co-authored-by: Jason Liu <jason@jxnl.coA>
It's generally considered to be a good practice to pin dependencies to
prevent surprise breakages when a new version of a dependency is
released. This commit adds the ability to pin dependencies when loading
from LangChainHub.
Centralizing this logic and using urllib fixes an issue identified by
some windows users highlighted in this video -
https://youtu.be/aJ6IQUh8MLQ?t=537
The agents usually benefit from understanding what the data looks like
to be able to filter effectively. Sending just one row in the table info
allows the agent to understand the data before querying and get better
results.
---------
Co-authored-by: Francisco Ingham <>
---------
Co-authored-by: Francisco Ingham <fpingham@gmail.com>
text-davinci-003 supports a context size of 4097 tokens so return 4097
instead of 4000 in modelname_to_contextsize() for text-davinci-003
Co-authored-by: Bill Kish <bill@cogniac.co>
Some custom agents might continue to iterate until they find the correct
answer, getting stuck on loops that generate request after request and
are really expensive for the end user. Putting an upper bound for the
number of iterations
by default controls this and can be explicitly tweaked by the user if
necessary.
Co-authored-by: Francisco Ingham <>
Referring to #687, I implemented the functionality to reduce K if it
exceeds the token limit.
Edit: I should have ran make lint locally. Also, this only applies to
`StuffDocumentChain`
* add implementations of `BaseCallbackHandler` to support tracing:
`SharedTracer` which is thread-safe and `Tracer` which is not and is
meant to be used locally.
* Tracers persist runs to locally running `langchain-server`
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
If `distance_func` and `collection_name` are in `kwargs` they are sent
to the `QdrantClient` which results in an error being raised.
Co-authored-by: Francisco Ingham <>
`SentenceTransformer` returns a NumPy array, not a `List[List[float]]`
or `List[float]` as specified in the interface of `Embeddings`. That PR
makes it consistent with the interface.
I'm providing a hotfix for Qdrant integration. Calculating a single
embedding to obtain the vector size was great idea. However, that change
introduced a bug trying to put only that single embedding into the
database. It's fixed. Right now all the embeddings will be pushed to
Qdrant.
Now that OpenAI has deprecated all embeddings models except
text-embedding-ada-002, we should stop specifying a legacy embedding
model in the example. This will also avoid confusion from people (like
me) trying to specify model="text-embedding-ada-002" and having that
erroneously expanded to text-search-text-embedding-ada-002-query-001
Since the tokenizer and model are constructed manually, model_kwargs
needs to
be passed to their constructors. Additionally, the pipeline has a
specific
named parameter to pass these with, which can provide forward
compatibility if
they are used for something other than tokenizer or model construction.
On the [Getting Started
page](https://langchain.readthedocs.io/en/latest/modules/prompts/getting_started.html)
for prompt templates, I believe the very last example
```python
print(dynamic_prompt.format(adjective=long_string))
```
should actually be
```python
print(dynamic_prompt.format(input=long_string))
```
The existing example produces `KeyError: 'input'` as expected
***
On the [Create a custom prompt
template](https://langchain.readthedocs.io/en/latest/modules/prompts/examples/custom_prompt_template.html#id1)
page, I believe the line
```python
Function Name: {kwargs["function_name"]}
```
should actually be
```python
Function Name: {kwargs["function_name"].__name__}
```
The existing example produces the prompt:
```
Given the function name and source code, generate an English language explanation of the function.
Function Name: <function get_source_code at 0x7f907bc0e0e0>
Source Code:
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)
Explanation:
```
***
On the [Example
Selectors](https://langchain.readthedocs.io/en/latest/modules/prompts/examples/example_selectors.html)
page, the first example does not define `example_prompt`, which is also
subtly different from previous example prompts used. For user
convenience, I suggest including
```python
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
```
in the code to be copy-pasted
- This uses the faiss built-in `write_index` and `load_index` to save
and load faiss indexes locally
- Also fixes#674
- The save/load functions also use the faiss library, so I refactored
the dependency into a function
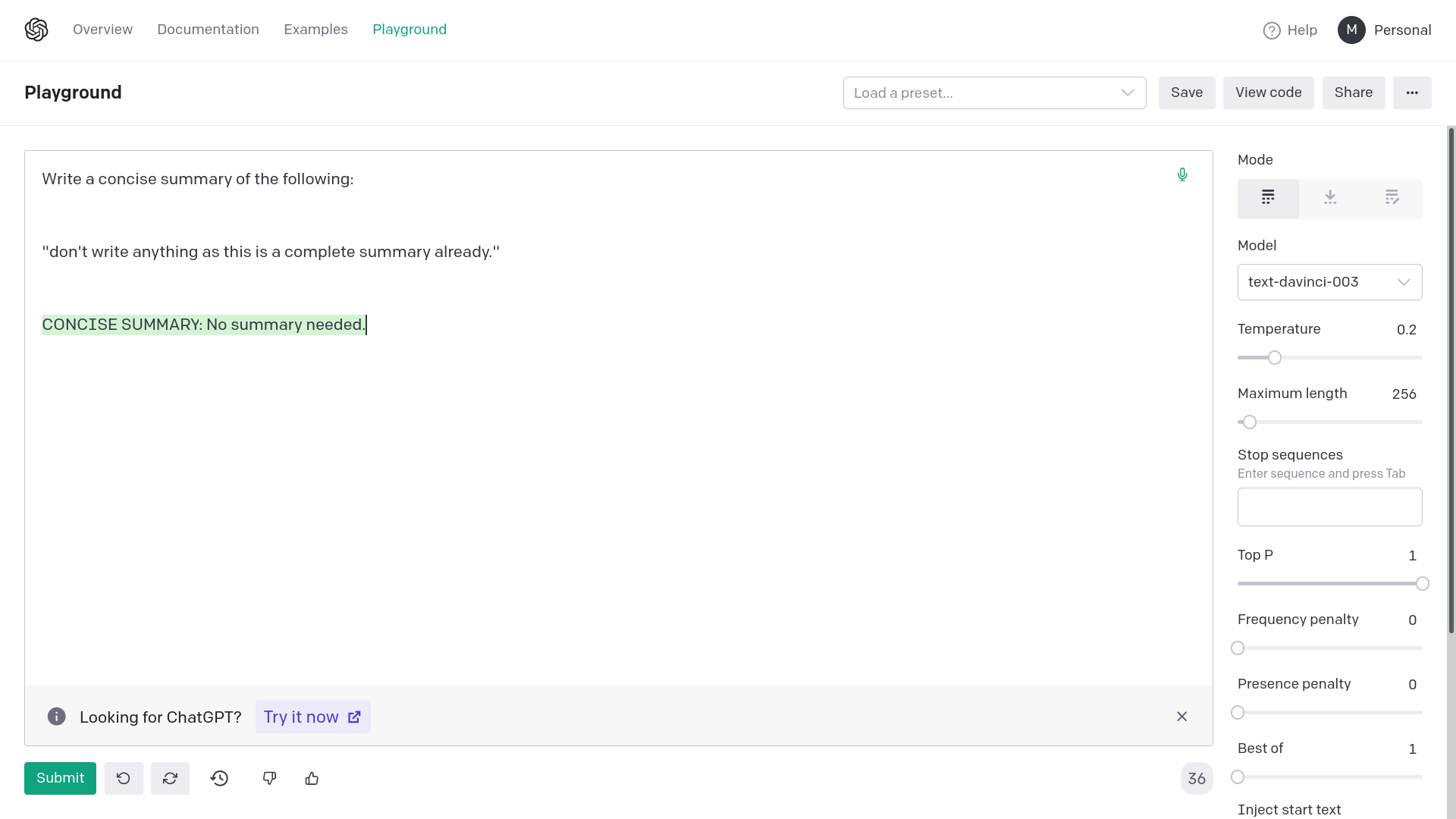
Adding quotation marks around {text} avoids generating empty or
completely random responses from OpenAI davinci-003. Empty or completely
unrelated intermediate responses in summarization messes up the final
result or makes it very inaccurate.
The error from OpenAI would be: "The model predicted a completion that
begins with a stop sequence, resulting in no output. Consider adjusting
your prompt or stop sequences."
This fix corrects the prompting for summarization chain. This works on
API too, the images are for demonstrative purposes.
This approach can be applied to other similar prompts too.
Examples:
1) Without quotation marks
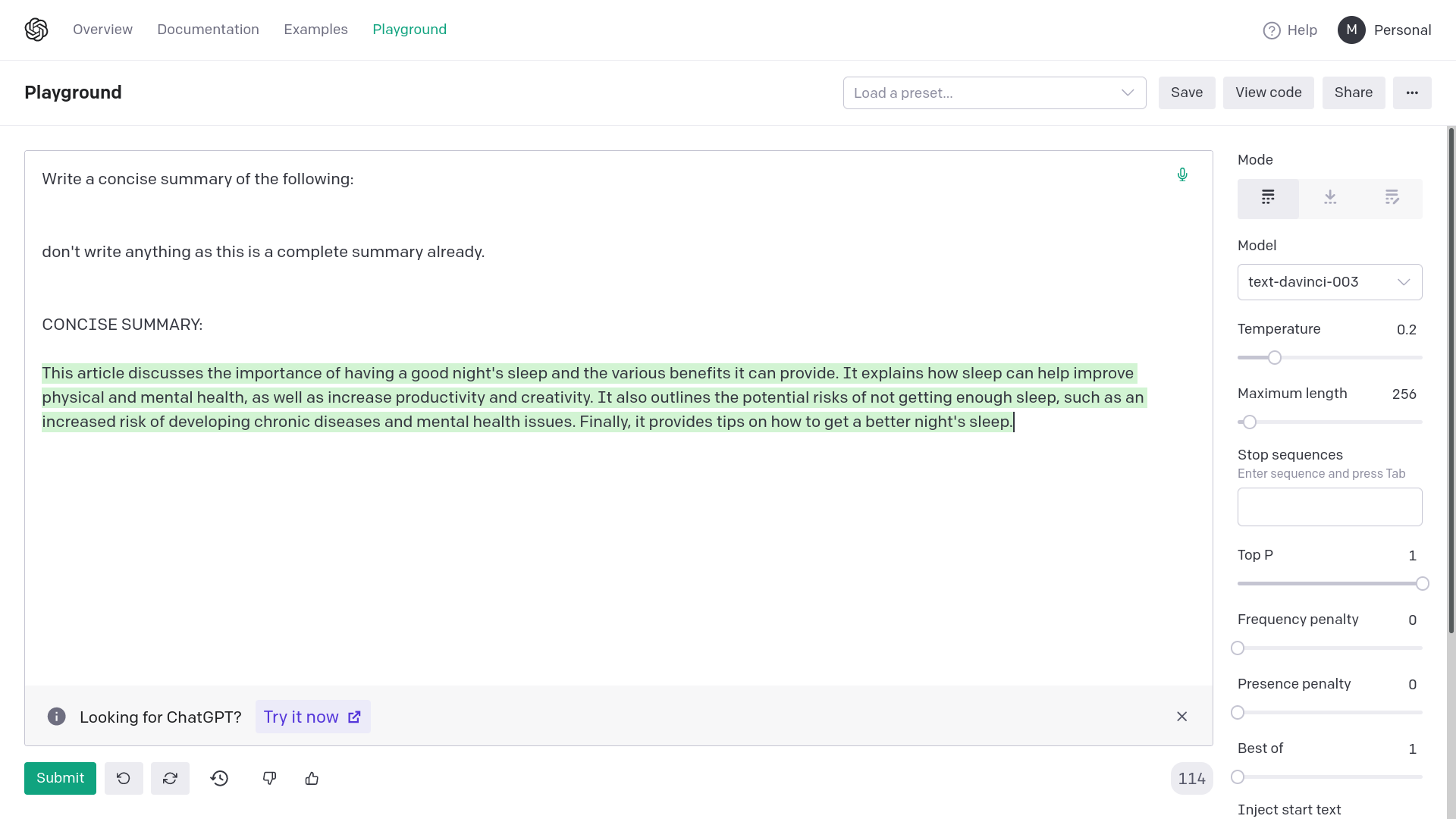
2) With quotation marks
Allow optionally specifying a list of ids for pinecone rather than
having them randomly generated.
This also permits editing the embedding/metadata of existing pinecone
entries, by id.
Allows for passing additional vectorstore params like namespace, etc. to
VectorDBQAWithSourcesChain
Example:
`chain = VectorDBQAWithSourcesChain.from_llm(OpenAI(temperature=0),
vectorstore=store, search_kwargs={"namespace": namespace})`
tl;dr: input -> word, output -> antonym, rename to dynamic_prompt
consistently
The provided code in this example doesn't run, because the keys are
`word` and `antonym`, rather than `input` and `output`.
Also, the `ExampleSelector`-based prompt is named `few_shot_prompt` when
defined and `dynamic_prompt` in the follow-up example. The former name
is less descriptive and collides with an earlier example, so I opted for
the latter.
Thanks for making a really cool library!
For using Azure OpenAI API, we need to set multiple env vars. But as can
be seen in openai package
[here](48b69293a3/openai/__init__.py (L35)),
the env var for setting base url is named `OPENAI_API_BASE` and not
`OPENAI_API_BASE_URL`. This PR fixes that part in the documentation.
Running the Cohere embeddings example from the docs:
```python
from langchain.embeddings import CohereEmbeddings
embeddings = CohereEmbeddings(cohere_api_key= cohere_api_key)
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
```
I get the error:
```bash
CohereError(message=res['message'], http_status=response.status_code, headers=response.headers)
cohere.error.CohereError: embed is not an available endpoint on this model
```
This is because the `model` string is set to `medium` which is not
currently available.
From the Cohere docs:
> Currently available models are small and large (default)
Adds release workflow that (1) creates a GitHub release and (2)
publishes built artifacts to PyPI
**Release Workflow**
1. Checkout `master` locally and cut a new branch
1. Run `poetry version <rule>` to version bump (e.g., `poetry version
patch`)
1. Commit changes and push to remote branch
1. Ensure all quality check workflows pass
1. Explicitly tag PR with `release` label
1. Merge to mainline
At this point, a release workflow should be triggered because:
* The PR is closed, targeting `master`, and merged
* `pyproject.toml` has been detected as modified
* The PR had a `release` label
The workflow will then proceed to build the artifacts, create a GitHub
release with release notes and uploaded artifacts, and publish to PyPI.
Example Workflow run:
https://github.com/shoelsch/langchain/actions/runs/3711037455/jobs/6291076898
Example Releases: https://github.com/shoelsch/langchain/releases
--
Note, this workflow is looking for the `PYPI_API_TOKEN` secret, so that
will need to be uploaded to the repository secrets. I tested uploading
as far as hitting a permissions issue due to project ownership in Test
PyPI.
I originally had only modified the `from_llm` to include the prompt but
I realized that if the prompt keys used on the custom prompt didn't
match the default prompt, it wouldn't work because of how `apply` works.
So I made some changes to the evaluate method to check if the prompt is
the default and if not, it will check if the input keys are the same as
the prompt key and update the inputs appropriately.
Let me know if there is a better way to do this.
Also added the custom prompt to the QA eval notebook.
add a chain that applies a prompt to all inputs and then returns not
only an answer but scores it
add examples for question answering and question answering with sources
Small quick fix:
Suggest making the order of the menu the same as it is written on the
page (Getting Started -> Key Concepts). Before the menu order was not
the same as it was on the page. Not sure if this is the only place the
menu is affected.
Mismatch is found here:
https://langchain.readthedocs.io/en/latest/modules/llms.html
Add
[`logit_bias`](https://beta.openai.com/docs/api-reference/completions/create#completions/create-logit_bias)
params to OpenAI
See [here](https://beta.openai.com/tokenizer) for the tokenizer.
NB: I see that others (like Cohere) have the same parameter, but since I
don't have an access to it, I don't want to make a mistake.
---
Just to make sure the default "{}" works for openai:
```
from langchain.llms import OpenAI
OPENAI_API_KEY="XXX"
llm = OpenAI(openai_api_key=OPENAI_API_KEY)
llm.generate('Write "test":')
llm = OpenAI(openai_api_key=OPENAI_API_KEY, logit_bias={'9288': -100, '1332': -100, '14402': -100, '6208': -100})
llm.generate('Write "test":')
```
Add `finish_reason` to `Generation` as well as extend
`BaseOpenAI._generate` to include it in the output. This can be useful
for usage in downstream tasks when we need to filter for only
generations that finished because of `"stop"` for example. Maybe we
should add this to `LLMChain` as well?
For more details, see
https://beta.openai.com/docs/guides/completion/best-practices
Signed-off-by: Diwank Singh Tomer <diwank.singh@gmail.com>
- Add support for local build and linkchecking of docs
- Add GitHub Action to automatically check links before prior to
publication
- Minor reformat of Contributing readme
- Fix existing broken links
Co-authored-by: Hunter Gerlach <hunter@huntergerlach.com>
Co-authored-by: Hunter Gerlach <HunterGerlach@users.noreply.github.com>
Co-authored-by: Hunter Gerlach <hunter@huntergerlach.com>
this is the second PR of #519.
in #519 I suggested deleting Extra.forbid.
I was very confused but I replaced Extra.forbid to Extra.ignore, which
is the default of pydantic.
Since the
[BaseLLM](4b7b8229de/langchain/llms/base.py (L20))
from which it is inherited is set in Extra.forbid, I wanted to avoid
having the Extra.forbid settings inherited by simply deleting it.
As talking #519, I made 2 PRs.
this is the first PR for adding a logger.
I am concerned about the following two points and would appreciate your
opinion.
1. Since the logger is not formatted, the statement itself is output
like a print statement, and I thought it was difficult to understand
that it was a warning, so I put WARNING! at the beginning of the warning
statement. After the logger formatting is done properly, the word
WARNING can be repeated.
2. Statement `Please confirm that {field_name} is what you intended.`
can be replaced like `If {field_name} is intended parameters, enter it
to model_kwargs`
thank you!
Yongtae
As of now, LangChain has an ad hoc release process: releases are cut with high frequency via by
a developer and published to [PyPI](https://pypi.org/project/ruff/).
a developer and published to [PyPI](https://pypi.org/project/langchain/).
LangChain follows the [semver](https://semver.org/) versioning standard. However, as pre-1.0 software,
even patch releases may contain [non-backwards-compatible changes](https://semver.org/#spec-item-4).
@ -55,12 +55,16 @@ even patch releases may contain [non-backwards-compatible changes](https://semve
If your contribution has made its way into a release, we will want to give you credit on Twitter (only if you want though)!
If you have a Twitter account you would like us to mention, please let us know in the PR or in another manner.
## 🤖Developer Setup
### 🚀Quick Start
## 🚀Quick Start
This project uses [Poetry](https://python-poetry.org/) as a dependency manager. Check out Poetry's [documentation on how to install it](https://python-poetry.org/docs/#installation) on your system before proceeding.
❗Note: If you use `Conda` or `Pyenv` as your environment / package manager, avoid dependency conflicts by doing the following first:
1. *Before installing Poetry*, create and activate a new Conda env (e.g. `conda create -n langchain python=3.9`)
2. Install Poetry (see above)
3. Tell Poetry to use the virtualenv python environment (`poetry config virtualenvs.prefer-active-python true`)
4. Continue with the following steps.
To install requirements:
```bash
@ -71,9 +75,11 @@ This will install all requirements for running the package, examples, linting, f
Now, you should be able to run the common tasks in the following section.
### ✅Common Tasks
## ✅Common Tasks
Type `make` for a list of common tasks.
#### Code Formatting
### Code Formatting
Formatting for this project is done via a combination of [Black](https://black.readthedocs.io/en/stable/) and [isort](https://pycqa.github.io/isort/).
@ -83,7 +89,7 @@ To run formatting for this project:
make format
```
#### Linting
### Linting
Linting for this project is done via a combination of [Black](https://black.readthedocs.io/en/stable/), [isort](https://pycqa.github.io/isort/), [flake8](https://flake8.pycqa.org/en/latest/), and [mypy](http://mypy-lang.org/).
@ -95,7 +101,7 @@ make lint
We recognize linting can be annoying - if you do not want to do it, please contact a project maintainer, and they can help you with it. We do not want this to be a blocker for good code getting contributed.
#### Coverage
### Coverage
Code coverage (i.e. the amount of code that is covered by unit tests) helps identify areas of the code that are potentially more or less brittle.
@ -105,14 +111,14 @@ To get a report of current coverage, run the following:
make coverage
```
#### Testing
### Testing
Unit tests cover modular logic that does not require calls to outside APIs.
To run unit tests:
```bash
make tests
make test
```
If you add new logic, please add a unit test.
@ -127,7 +133,7 @@ make integration_tests
If you add support for a new external API, please add a new integration test.
#### Adding a Jupyter Notebook
### Adding a Jupyter Notebook
If you are adding a Jupyter notebook example, you'll want to install the optional `dev` dependencies.
@ -145,10 +151,36 @@ poetry run jupyter notebook
When you run `poetry install`, the `langchain` package is installed as editable in the virtualenv, so your new logic can be imported into the notebook.
#### Contribute Documentation
## Using Docker
Refer to [DOCKER.md](docker/DOCKER.md) for more information.
## Documentation
### Contribute Documentation
Docs are largely autogenerated by [sphinx](https://www.sphinx-doc.org/en/master/) from the code.
For that reason, we ask that you add good documentation to all classes and methods.
Similar to linting, we recognize documentation can be annoying. If you do not want to do it, please contact a project maintainer, and they can help you with it. We do not want this to be a blocker for good code getting contributed.
### Build Documentation Locally
Before building the documentation, it is always a good idea to clean the build directory:
```bash
make docs_clean
```
Next, you can run the linkchecker to make sure all links are valid:
```bash
make docs_linkcheck
```
Finally, you can build the documentation as outlined below:
@ -57,10 +79,8 @@ Memory is the concept of persisting state between calls of a chain/agent. LangCh
For more information on these concepts, please see our [full documentation](https://langchain.readthedocs.io/en/latest/?).
## 💁 Contributing
As an open source project in a rapidly developing field, we are extremely open
to contributions, whether it be in the form of a new feature, improved infra, or better documentation.
As an open source project in a rapidly developing field, we are extremely open to contributions, whether it be in the form of a new feature, improved infra, or better documentation.
For detailed information on how to contribute, see [here](CONTRIBUTING.md).
To quickly get started, run the command `make docker`.
If docker is installed the Makefile will export extra targets in the fomrat `docker.*` to build and run the docker image. Type `make` for a list of available tasks.
There is a basic `docker-compose.yml` in the docker directory.
## Building the development image
Using `make docker` will build the dev image if it does not exist, then drops
you inside the container with the langchain environment available in the shell.
### Customizing the image and installed dependencies
The image is built with a default python version and all extras and dev
dependencies. It can be customized by changing the variables in the [.env](/docker/.env)
file.
If you don't need all the `extra` dependencies a slimmer image can be obtained by
commenting out `POETRY_EXTRA_PACKAGES` in the [.env](docker/.env) file.
### Image caching
The Dockerfile is optimized to cache the poetry install step. A rebuild is triggered when there a change to the source code.
## Example Usage
All commands from langchain's python environment are available by default in the container.
A few examples:
```bash
# run jupyter notebook
docker run --rm -it IMG jupyter notebook
# run ipython
docker run --rm -it IMG ipython
# start web server
docker run --rm -p 8888:8888 IMG python -m http.server 8888
```
## Testing / Linting
Tests and lints are run using your local source directory that is mounted on the volume /src.
Run unit tests in the container with `make docker.test`.
Run the linting and formatting checks with `make docker.lint`.
Note: this task can run in parallel using `make -j4 docker.lint`.
This page covers how to Nomic's Atlas ecosystem within LangChain.
It is broken into two parts: installation and setup, and then references to specific Atlas wrappers.
## Installation and Setup
- Install the Python package with `pip install nomic`
- Nomic is also included in langchains poetry extras `poetry install -E all`
-
## Wrappers
### VectorStore
There exists a wrapper around the Atlas neural database, allowing you to use it as a vectorstore.
This vectorstore also gives you full access to the underlying AtlasProject object, which will allow you to use the full range of Atlas map interactions, such as bulk tagging and automatic topic modeling.
Please see [the Nomic docs](https://docs.nomic.ai/atlas_api.html) for more detailed information.
To import this vectorstore:
```python
from langchain.vectorstores import AtlasDB
```
For a more detailed walkthrough of the Chroma wrapper, see [this notebook](../modules/indexes/examples/vectorstores.ipynb)
This page covers how to use the Banana ecosystem within LangChain.
It is broken into two parts: installation and setup, and then references to specific Banana wrappers.
## Installation and Setup
- Install with `pip3 install banana-dev`
- Get an Banana api key and set it as an environment variable (`BANANA_API_KEY`)
## Define your Banana Template
If you want to use an available language model template you can find one [here](https://app.banana.dev/templates/conceptofmind/serverless-template-palmyra-base).
This template uses the Palmyra-Base model by [Writer](https://writer.com/product/api/).
You can check out an example Banana repository [here](https://github.com/conceptofmind/serverless-template-palmyra-base).
## Build the Banana app
Banana Apps must include the "output" key in the return json.
This page covers how to use the Deep Lake ecosystem within LangChain.
It is broken into two parts: installation and setup, and then references to specific Deep Lake wrappers. For more information.
1. Here is [whitepaper](https://www.deeplake.ai/whitepaper) and [academic paper](https://arxiv.org/pdf/2209.10785.pdf) for Deep Lake
2. Here is a set of additional resources available for review: [Deep Lake](https://github.com/activeloopai/deeplake), [Getting Started](https://docs.activeloop.ai/getting-started) and[Tutorials](https://docs.activeloop.ai/hub-tutorials)
## Installation and Setup
- Install the Python package with `pip install deeplake`
## Wrappers
### VectorStore
There exists a wrapper around Deep Lake, a data lake for Deep Learning applications, allowing you to use it as a vectorstore (for now), whether for semantic search or example selection.
To import this vectorstore:
```python
from langchain.vectorstores import DeepLake
```
For a more detailed walkthrough of the Deep Lake wrapper, see [this notebook](../modules/indexes/vectorstore_examples/deeplake.ipynb)
This page covers how to use the [Serper](https://serper.dev) Google Search API within LangChain. Serper is a low-cost Google Search API that can be used to add answer box, knowledge graph, and organic results data from Google Search.
It is broken into two parts: setup, and then references to the specific Google Serper wrapper.
## Setup
- Go to [serper.dev](https://serper.dev) to sign up for a free account
- Get the api key and set it as an environment variable (`SERPER_API_KEY`)
## Wrappers
### Utility
There exists a GoogleSerperAPIWrapper utility which wraps this API. To import this utility:
```python
from langchain.utilities import GoogleSerperAPIWrapper
```
You can use it as part of a Self Ask chain:
```python
from langchain.utilities import GoogleSerperAPIWrapper
from langchain.llms.openai import OpenAI
from langchain.agents import initialize_agent, Tool
- Get an API key and set it as an environment variable (`GRAPHSIGNAL_API_KEY`)
## Tracing and Monitoring
Graphsignal automatically instruments and starts tracing and monitoring chains. Traces, metrics and errors are then available in your [Graphsignal dashboard](https://app.graphsignal.com/). No prompts or other sensitive data are sent to Graphsignal cloud, only statistics and metadata.
Initialize the tracer by providing a deployment name:
This page covers how to use the [Helicone](https://helicone.ai) within LangChain.
## What is Helicone?
Helicone is an [open source](https://github.com/Helicone/helicone) observability platform that proxies your OpenAI traffic and provides you key insights into your spend, latency and usage.

## Quick start
With your LangChain environment you can just add the following parameter.
Now head over to [helicone.ai](https://helicone.ai/onboarding?step=2) to create your account, and add your OpenAI API key within our dashboard to view your logs.
This page covers how to use the Hugging Face ecosystem (including the Hugging Face Hub) within LangChain.
This page covers how to use the Hugging Face ecosystem (including the [Hugging Face Hub](https://huggingface.co)) within LangChain.
It is broken into two parts: installation and setup, and then references to specific Hugging Face wrappers.
## Installation and Setup
If you want to work with the Hugging Face Hub:
- Install the Python SDK with `pip install huggingface_hub`
- Get an OpenAI api key and set it as an environment variable (`HUGGINGFACEHUB_API_TOKEN`)
- Install the Hub client library with `pip install huggingface_hub`
- Create a Hugging Face account (it's free!)
- Create an [access token](https://huggingface.co/docs/hub/security-tokens) and set it as an environment variable (`HUGGINGFACEHUB_API_TOKEN`)
If you want work with Hugging Face python libraries:
If you want work with the Hugging Face Python libraries:
- Install `pip install transformers` for working with models and tokenizers
- Install `pip install datasets` for working with datasets
@ -18,7 +19,7 @@ If you want work with Hugging Face python libraries:
### LLM
There exists two Hugging Face LLM wrappers, one for a local pipeline and one for a model hosted on Hugging Face Hub.
Note that these wrappers only work for the following tasks: `text2text-generation`, `text-generation`
Note that these wrappers only work for models that support the following tasks: [`text2text-generation`](https://huggingface.co/models?library=transformers&pipeline_tag=text2text-generation&sort=downloads), [`text-generation`](https://huggingface.co/models?library=transformers&pipeline_tag=text-classification&sort=downloads)
To use the local pipeline wrapper:
```python
@ -35,7 +36,7 @@ For a more detailed walkthrough of the Hugging Face Hub wrapper, see [this noteb
### Embeddings
There exists two Hugging Face Embeddings wrappers, one for a local model and one for a model hosted on Hugging Face Hub.
Note that these wrappers only work for `sentence-transformers` models.
Note that these wrappers only work for [`sentence-transformers` models](https://huggingface.co/models?library=sentence-transformers&sort=downloads).
To use the local pipeline wrapper:
```python
@ -46,7 +47,7 @@ To use a the wrapper for a model hosted on Hugging Face Hub:
```python
from langchain.embeddings import HuggingFaceHubEmbeddings
```
For a more detailed walkthrough of this, see [this notebook](../modules/utils/combine_docs_examples/embeddings.ipynb)
For a more detailed walkthrough of this, see [this notebook](../modules/indexes/examples/embeddings.ipynb)
### Tokenizer
@ -58,11 +59,11 @@ You can also use it to count tokens when splitting documents with
from langchain.text_splitter import CharacterTextSplitter
This page covers how to use the SearxNG search API within LangChain.
It is broken into two parts: installation and setup, and then references to the specific SearxNG API wrapper.
## Installation and Setup
- You can find a list of public SearxNG instances [here](https://searx.space/).
- It recommended to use a self-hosted instance to avoid abuse on the public instances. Also note that public instances often have a limit on the number of requests.
- To run a self-hosted instance see [this page](https://searxng.github.io/searxng/admin/installation.html) for more information.
- To use the tool you need to provide the searx host url by:
1. passing the named parameter `searx_host` when creating the instance.
2. exporting the environment variable `SEARXNG_HOST`.
## Wrappers
### Utility
You can use the wrapper to get results from a SearxNG instance.
```python
from langchain.utilities import SearxSearchWrapper
```
### Tool
You can also easily load this wrapper as a Tool (to use with an Agent).
This simple application demonstrates a conversational agent implemented with OpenAI GPT-3.5 and LangChain. When necessary, it leverages tools for complex math, searching the internet, and accessing news and weather.
@ -162,7 +162,7 @@ This is one of the simpler types of chains, but understanding how it works will
`````{dropdown} Agents: Dynamically call chains based on user input
So for the chains we've looked at run in a predetermined order.
So far the chains we've looked at run in a predetermined order.
Agents no longer do: they use an LLM to determine which actions to take and in what order. An action can either be using a tool and observing its output, or returning to the user.
@ -179,6 +179,20 @@ In order to load agents, you should understand the following concepts:
**Tools**: For a list of predefined tools and their specifications, see [here](../modules/agents/tools.md).
For this example, you will also need to install the SerpAPI Python package.
- [Language Model Cascades](https://arxiv.org/abs/2207.10342)
- [ICE Primer Book](https://primer.ought.org/)
@ -52,25 +57,28 @@ Resources:
## Memetic Proxy
Encouraging the LLM to respond in a certain way framing the discussion in a context that the model knows of and that will result in that type of response. For example, as a conversation between a student and a teacher.
Encouraging the LLM to respond in a certain way framing the discussion in a context that the model knows of and that will result in that type of response. For example, as a conversation between a student and a teacher.
Resources:
- [Paper](https://arxiv.org/pdf/2102.07350.pdf)
## Self Consistency
A decoding strategy that samples a diverse set of reasoning paths and then selects the most consistent answer.
Is most effective when combined with Chain-of-thought prompting.
A decoding strategy that samples a diverse set of reasoning paths and then selects the most consistent answer.
Is most effective when combined with Chain-of-thought prompting.
Resources:
- [Paper](https://arxiv.org/pdf/2203.11171.pdf)
## Inception
Also called “First Person Instruction”.
Encouraging the model to think a certain way by including the start of the model’s response in the prompt.
Also called “First Person Instruction”.
Encouraging the model to think a certain way by including the start of the model’s response in the prompt.
Checkout the below guide for a walkthrough of how to get started using LangChain to create an Language Model application.
- `Getting Started Documentation <getting_started/getting_started.html>`_
- `Getting Started Documentation <./getting_started/getting_started.html>`_
..toctree::
:maxdepth:1
@ -27,22 +42,26 @@ Checkout the below guide for a walkthrough of how to get started using LangChain
Modules
-----------
There are six main modules that LangChain provides support for.
There are several main modules that LangChain provides support for.
For each module we provide some examples to get started, how-to guides, reference docs, and conceptual guides.
These modules are, in increasing order of complexity:
- `Prompts <modules/prompts.html>`_: This includes prompt management, prompt optimization, and prompt serialization.
- `Prompts <./modules/prompts.html>`_: This includes prompt management, prompt optimization, and prompt serialization.
- `LLMs <modules/llms.html>`_: This includes a generic interface for all LLMs, and common utilities for working with LLMs.
- `LLMs <./modules/llms.html>`_: This includes a generic interface for all LLMs, and common utilities for working with LLMs.
- `Utils <modules/utils.html>`_: Language models are often more powerful when interacting with other sources of knowledge or computation. This can include Python REPLs, embeddings, search engines, and more. LangChain provides a large collection of common utils to use in your application.
- `Document Loaders <./modules/document_loaders.html>`_: This includes a standard interface for loading documents, as well as specific integrations to all types of text data sources.
- `Chains <modules/chains.html>`_: Chains go beyond just a single LLM call, and are sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
- `Utils <./modules/utils.html>`_: Language models are often more powerful when interacting with other sources of knowledge or computation. This can include Python REPLs, embeddings, search engines, and more. LangChain provides a large collection of common utils to use in your application.
- `Agents <modules/agents.html>`_: Agents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end to end agents.
- `Chains <./modules/chains.html>`_: Chains go beyond just a single LLM call, and are sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
- `Memory <modules/memory.html>`_: Memory is the concept of persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
- `Indexes <./modules/indexes.html>`_: Language models are often more powerful when combined with your own text data - this module covers best practices for doing exactly that.
- `Agents <./modules/agents.html>`_: Agents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end to end agents.
- `Memory <./modules/memory.html>`_: Memory is the concept of persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
..toctree::
@ -51,33 +70,35 @@ These modules are, in increasing order of complexity:
:name:modules
:hidden:
modules/prompts.md
modules/llms.md
modules/utils.md
modules/chains.md
modules/agents.md
modules/memory.md
./modules/prompts.md
./modules/llms.md
./modules/document_loaders.md
./modules/utils.md
./modules/indexes.md
./modules/chains.md
./modules/agents.md
./modules/memory.md
Use Cases
----------
The above modules can be used in a variety of ways. LangChain also provides guidance and assistance in this. Below are some of the common use cases LangChain supports.
- `Agents <use_cases/agents.html>`_: Agents are systems that use a language model to interact with other tools. These can be used to do more grounded question/answering, interact with APIs, or even take actions.
- `Agents <./use_cases/agents.html>`_: Agents are systems that use a language model to interact with other tools. These can be used to do more grounded question/answering, interact with APIs, or even take actions.
- `Chatbots <use_cases/chatbots.html>`_: Since language models are good at producing text, that makes them ideal for creating chatbots.
- `Chatbots <./use_cases/chatbots.html>`_: Since language models are good at producing text, that makes them ideal for creating chatbots.
- `Data Augmented Generation <use_cases/combine_docs.html>`_: Data Augmented Generation involves specific types of chains that first interact with an external datasource to fetch data to use in the generation step. Examples of this include summarization of long pieces of text and question/answering over specific data sources.
- `Data Augmented Generation <./use_cases/combine_docs.html>`_: Data Augmented Generation involves specific types of chains that first interact with an external datasource to fetch data to use in the generation step. Examples of this include summarization of long pieces of text and question/answering over specific data sources.
- `Question Answering <use_cases/question_answering.html>`_: Answering questions over specific documents, only utilizing the information in those documents to construct an answer. A type of Data Augmented Generation.
- `Question Answering <./use_cases/question_answering.html>`_: Answering questions over specific documents, only utilizing the information in those documents to construct an answer. A type of Data Augmented Generation.
- `Summarization <use_cases/summarization.html>`_: Summarizing longer documents into shorter, more condensed chunks of information. A type of Data Augmented Generation.
- `Summarization <./use_cases/summarization.html>`_: Summarizing longer documents into shorter, more condensed chunks of information. A type of Data Augmented Generation.
- `Evaluation <use_cases/evaluation.html>`_: Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.
- `Evaluation <./use_cases/evaluation.html>`_: Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.
- `Generate similar examples <use_cases/generate_examples.html>`_: Generating similar examples to a given input. This is a common use case for many applications, and LangChain provides some prompts/chains for assisting in this.
- `Generate similar examples <./use_cases/generate_examples.html>`_: Generating similar examples to a given input. This is a common use case for many applications, and LangChain provides some prompts/chains for assisting in this.
- `Compare models <model_laboratory.html>`_: Experimenting with different prompts, models, and chains is a big part of developing the best possible application. The ModelLaboratory makes it easy to do so.
- `Compare models <./use_cases/model_laboratory.html>`_: Experimenting with different prompts, models, and chains is a big part of developing the best possible application. The ModelLaboratory makes it easy to do so.
@ -87,14 +108,14 @@ The above modules can be used in a variety of ways. LangChain also provides guid
:name:use_cases
:hidden:
use_cases/agents.md
use_cases/chatbots.md
use_cases/generate_examples.ipynb
use_cases/combine_docs.md
use_cases/question_answering.md
use_cases/summarization.md
use_cases/evaluation.rst
use_cases/model_laboratory.ipynb
./use_cases/agents.md
./use_cases/chatbots.md
./use_cases/generate_examples.ipynb
./use_cases/combine_docs.md
./use_cases/question_answering.md
./use_cases/summarization.md
./use_cases/evaluation.rst
./use_cases/model_laboratory.ipynb
Reference Docs
@ -103,16 +124,16 @@ Reference Docs
All of LangChain's reference documentation, in one place. Full documentation on all methods, classes, installation methods, and integration setups for LangChain.
- `Reference Documentation <reference.html>`_
- `Reference Documentation <./reference.html>`_
..toctree::
:maxdepth:1
:caption:Reference
:name:reference
:hidden:
reference/installation.md
reference/integrations.md
reference.rst
./reference/installation.md
./reference/integrations.md
./reference.rst
LangChain Ecosystem
@ -120,7 +141,7 @@ LangChain Ecosystem
Guides for how other companies/products can be used with LangChain
- `LangChain Ecosystem <ecosystem.html>`_
- `LangChain Ecosystem <./ecosystem.html>`_
..toctree::
:maxdepth:1
@ -129,7 +150,7 @@ Guides for how other companies/products can be used with LangChain
:name:ecosystem
:hidden:
ecosystem.rst
./ecosystem.rst
Additional Resources
@ -137,12 +158,20 @@ Additional Resources
Additional collection of resources we think may be useful as you develop your application!
- `Glossary <glossary.html>`_: A glossary of all related terms, papers, methods, etc. Whether implemented in LangChain or not!
- `LangChainHub <https://github.com/hwchase17/langchain-hub>`_: The LangChainHub is a place to share and explore other prompts, chains, and agents.
- `Glossary <./glossary.html>`_: A glossary of all related terms, papers, methods, etc. Whether implemented in LangChain or not!
- `Gallery <gallery.html>`_: A collection of our favorite projects that use LangChain. Useful for finding inspiration or seeing how things were done in other applications.
- `Gallery <./gallery.html>`_: A collection of our favorite projects that use LangChain. Useful for finding inspiration or seeing how things were done in other applications.
- `Deployments <./deployments.html>`_: A collection of instructions, code snippets, and template repositories for deploying LangChain apps.
- `Discord <https://discord.gg/6adMQxSpJS>`_: Join us on our Discord to discuss all things LangChain!
- `Tracing <./tracing.html>`_: A guide on using tracing in LangChain to visualize the execution of chains and agents.
- `Production Support <https://forms.gle/57d8AmXBYp8PP8tZA>`_: As you move your LangChains into production, we'd love to offer more comprehensive support. Please fill out this form and we'll set up a dedicated support Slack channel.
..toctree::
:maxdepth:1
@ -150,5 +179,10 @@ Additional collection of resources we think may be useful as you develop your ap
Some applications will require not just a predetermined chain of calls to LLMs/other tools,
but potentially an unknown chain that depends on the user input.
but potentially an unknown chain that depends on the user's input.
In these types of chains, there is a “agent” which has access to a suite of tools.
Depending on the user input, the agent can then decide which, if any, of these tools to call.
The following sections of documentation are provided:
- `Getting Started <agents/getting_started.html>`_: A notebook to help you get started working with agents as quickly as possible.
- `Getting Started <./agents/getting_started.html>`_: A notebook to help you get started working with agents as quickly as possible.
- `Key Concepts <agents/key_concepts.html>`_: A conceptual guide going over the various concepts related to agents.
- `Key Concepts <./agents/key_concepts.html>`_: A conceptual guide going over the various concepts related to agents.
- `How-To Guides <agents/how_to_guides.html>`_: A collection of how-to guides. These highlight how to integrate various types of tools, how to work with different types of agent, and how to customize agents.
- `How-To Guides <./agents/how_to_guides.html>`_: A collection of how-to guides. These highlight how to integrate various types of tools, how to work with different types of agents, and how to customize agents.
- `Reference </reference/modules/agents.html>`_: API reference documentation for all Agent classes.
- `Reference <../reference/modules/agents.html>`_: API reference documentation for all Agent classes.
@ -24,7 +24,7 @@ The following sections of documentation are provided:
"This notebook covers how to combine agents and vectorstores. The use case for this is that you've ingested your data into a vectorstore and want to interact with it in an agentic manner.\n",
"\n",
"The reccomended method for doing so is to create a VectorDBQAChain and then use that as a tool in the overall agent. Let's take a look at doing this below. You can do this with multiple different vectordbs, and use the agent as a way to route between them. There are two different ways of doing this - you can either let the agent use the vectorstores as normal tools, or you can set `return_direct=True` to really just use the agent as a router."
" description=\"useful for when you need to answer questions about the most recent state of the union address. Input should be a fully formed question.\"\n",
" ),\n",
" Tool(\n",
" name = \"Ruff QA System\",\n",
" func=ruff.run,\n",
" description=\"useful for when you need to answer questions about ruff (a python linter). Input should be a fully formed question.\"\n",
" ),\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 45,
"id": "fc47f230",
"metadata": {},
"outputs": [],
"source": [
"# Construct the agent. We will use the default agent type here.\n",
"# See documentation for a full list of options.\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out what Biden said about Ketanji Brown Jackson in the State of the Union address.\n",
"Action: State of Union QA System\n",
"Action Input: What did Biden say about Ketanji Brown Jackson in the State of the Union address?\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3m Biden said that Jackson is one of the nation's top legal minds and that she will continue Justice Breyer's legacy of excellence.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
"Final Answer: Biden said that Jackson is one of the nation's top legal minds and that she will continue Justice Breyer's legacy of excellence.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"\"Biden said that Jackson is one of the nation's top legal minds and that she will continue Justice Breyer's legacy of excellence.\""
]
},
"execution_count": 46,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(\"What did biden say about ketanji brown jackson is the state of the union address?\")"
]
},
{
"cell_type": "code",
"execution_count": 47,
"id": "4e91b811",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out the advantages of using ruff over flake8\n",
"Action: Ruff QA System\n",
"Action Input: What are the advantages of using ruff over flake8?\u001b[0m\n",
"Observation: \u001b[33;1m\u001b[1;3m Ruff can be used as a drop-in replacement for Flake8 when used (1) without or with a small number of plugins, (2) alongside Black, and (3) on Python 3 code. It also re-implements some of the most popular Flake8 plugins and related code quality tools natively, including isort, yesqa, eradicate, and most of the rules implemented in pyupgrade. Ruff also supports automatically fixing its own lint violations, which Flake8 does not.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
"Final Answer: Ruff can be used as a drop-in replacement for Flake8 when used (1) without or with a small number of plugins, (2) alongside Black, and (3) on Python 3 code. It also re-implements some of the most popular Flake8 plugins and related code quality tools natively, including isort, yesqa, eradicate, and most of the rules implemented in pyupgrade. Ruff also supports automatically fixing its own lint violations, which Flake8 does not.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'Ruff can be used as a drop-in replacement for Flake8 when used (1) without or with a small number of plugins, (2) alongside Black, and (3) on Python 3 code. It also re-implements some of the most popular Flake8 plugins and related code quality tools natively, including isort, yesqa, eradicate, and most of the rules implemented in pyupgrade. Ruff also supports automatically fixing its own lint violations, which Flake8 does not.'"
]
},
"execution_count": 47,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(\"Why use ruff over flake8?\")"
]
},
{
"cell_type": "markdown",
"id": "787a9b5e",
"metadata": {},
"source": [
"## Use the Agent solely as a router"
]
},
{
"cell_type": "markdown",
"id": "9161ba91",
"metadata": {},
"source": [
"You can also set `return_direct=True` if you intend to use the agent as a router and just want to directly return the result of the VectorDBQaChain.\n",
"\n",
"Notice that in the above examples the agent did some extra work after querying the VectorDBQAChain. You can avoid that and just return the result directly."
]
},
{
"cell_type": "code",
"execution_count": 48,
"id": "f59b377e",
"metadata": {},
"outputs": [],
"source": [
"tools = [\n",
" Tool(\n",
" name = \"State of Union QA System\",\n",
" func=state_of_union.run,\n",
" description=\"useful for when you need to answer questions about the most recent state of the union address. Input should be a fully formed question.\",\n",
" return_direct=True\n",
" ),\n",
" Tool(\n",
" name = \"Ruff QA System\",\n",
" func=ruff.run,\n",
" description=\"useful for when you need to answer questions about ruff (a python linter). Input should be a fully formed question.\",\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out what Biden said about Ketanji Brown Jackson in the State of the Union address.\n",
"Action: State of Union QA System\n",
"Action Input: What did Biden say about Ketanji Brown Jackson in the State of the Union address?\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3m Biden said that Jackson is one of the nation's top legal minds and that she will continue Justice Breyer's legacy of excellence.\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"\" Biden said that Jackson is one of the nation's top legal minds and that she will continue Justice Breyer's legacy of excellence.\""
]
},
"execution_count": 50,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(\"What did biden say about ketanji brown jackson in the state of the union address?\")"
]
},
{
"cell_type": "code",
"execution_count": 51,
"id": "edfd0a1a",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out the advantages of using ruff over flake8\n",
"Action: Ruff QA System\n",
"Action Input: What are the advantages of using ruff over flake8?\u001b[0m\n",
"Observation: \u001b[33;1m\u001b[1;3m Ruff can be used as a drop-in replacement for Flake8 when used (1) without or with a small number of plugins, (2) alongside Black, and (3) on Python 3 code. It also re-implements some of the most popular Flake8 plugins and related code quality tools natively, including isort, yesqa, eradicate, and most of the rules implemented in pyupgrade. Ruff also supports automatically fixing its own lint violations, which Flake8 does not.\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"' Ruff can be used as a drop-in replacement for Flake8 when used (1) without or with a small number of plugins, (2) alongside Black, and (3) on Python 3 code. It also re-implements some of the most popular Flake8 plugins and related code quality tools natively, including isort, yesqa, eradicate, and most of the rules implemented in pyupgrade. Ruff also supports automatically fixing its own lint violations, which Flake8 does not.'"
]
},
"execution_count": 51,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(\"Why use ruff over flake8?\")"
]
},
{
"cell_type": "markdown",
"id": "49a0cbbe",
"metadata": {},
"source": [
"## Multi-Hop vectorstore reasoning\n",
"\n",
"Because vectorstores are easily usable as tools in agents, it is easy to use answer multi-hop questions that depend on vectorstores using the existing agent framework"
]
},
{
"cell_type": "code",
"execution_count": 57,
"id": "d397a233",
"metadata": {},
"outputs": [],
"source": [
"tools = [\n",
" Tool(\n",
" name = \"State of Union QA System\",\n",
" func=state_of_union.run,\n",
" description=\"useful for when you need to answer questions about the most recent state of the union address. Input should be a fully formed question, not referencing any obscure pronouns from the conversation before.\"\n",
" ),\n",
" Tool(\n",
" name = \"Ruff QA System\",\n",
" func=ruff.run,\n",
" description=\"useful for when you need to answer questions about ruff (a python linter). Input should be a fully formed question, not referencing any obscure pronouns from the conversation before.\"\n",
" ),\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 58,
"id": "06157240",
"metadata": {},
"outputs": [],
"source": [
"# Construct the agent. We will use the default agent type here.\n",
"# See documentation for a full list of options.\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out what tool ruff uses to run over Jupyter Notebooks, and if the president mentioned it in the state of the union.\n",
"Action: Ruff QA System\n",
"Action Input: What tool does ruff use to run over Jupyter Notebooks?\u001b[0m\n",
"Observation: \u001b[33;1m\u001b[1;3m Ruff is integrated into nbQA, a tool for running linters and code formatters over Jupyter Notebooks. After installing ruff and nbqa, you can run Ruff over a notebook like so: > nbqa ruff Untitled.ipynb\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now need to find out if the president mentioned this tool in the state of the union.\n",
"Action: State of Union QA System\n",
"Action Input: Did the president mention nbQA in the state of the union?\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3m No, the president did not mention nbQA in the state of the union.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer.\n",
"Final Answer: No, the president did not mention nbQA in the state of the union.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'No, the president did not mention nbQA in the state of the union.'"
]
},
"execution_count": 59,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(\"What tool does ruff use to run over Jupyter Notebooks? Did the president mention that tool in the state of the union?\")"
"LangChain provides async support for Agents by leveraging the [asyncio](https://docs.python.org/3/library/asyncio.html) library.\n",
"\n",
"Async methods are currently supported for the following `Tools`: [`SerpAPIWrapper`](https://github.com/hwchase17/langchain/blob/master/langchain/serpapi.py) and [`LLMMathChain`](https://github.com/hwchase17/langchain/blob/master/langchain/chains/llm_math/base.py). Async support for other agent tools are on the roadmap.\n",
"\n",
"For `Tool`s that have a `coroutine` implemented (the two mentioned above), the `AgentExecutor` will `await` them directly. Otherwise, the `AgentExecutor` will call the `Tool`'s `func` via `asyncio.get_event_loop().run_in_executor` to avoid blocking the main runloop.\n",
"\n",
"You can use `arun` to call an `AgentExecutor` asynchronously."
]
},
{
"cell_type": "markdown",
"id": "97800378-cc34-4283-9bd0-43f336bc914c",
"metadata": {},
"source": [
"## Serial vs. Concurrent Execution\n",
"\n",
"In this example, we kick off agents to answer some questions serially vs. concurrently. You can see that concurrent execution significantly speeds this up."
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
"Final Answer: Max Verstappen, 25 years old, raised to the 0.23 power is 1.84599359907945.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n",
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out who won the US Open women's final in 2019 and then calculate her age raised to the 0.34 power.\n",
"Action: Search\n",
"Action Input: \"US Open women's final 2019 winner\"\u001b[0m\n",
"Observation: \u001b[33;1m\u001b[1;3mBianca Andreescu defeated Serena Williams in the final, 6–3, 7–5 to win the women's singles tennis title at the 2019 US Open. It was her first major title, and she became the first Canadian, as well as the first player born in the 2000s, to win a major singles title.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I need to find out Bianca Andreescu's age.\n",
"print(f\"Serial executed in {elapsed:0.2f} seconds.\")"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "076d7b85-45ec-465d-8b31-c2ad119c3438",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.\n",
"Action: Search\n",
"Action Input: \"Olivia Wilde boyfriend\"\u001b[0m\u001b[32;1m\u001b[1;3m I need to find out who Beyonce's husband is and then calculate his age raised to the 0.19 power.\n",
"Action: Search\n",
"Action Input: \"Who is Beyonce's husband?\"\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I need to find out who won the grand prix and then calculate their age raised to the 0.23 power.\n",
"Action: Search\n",
"Action Input: \"Formula 1 Grand Prix Winner\"\u001b[0m\u001b[32;1m\u001b[1;3m I need to find out who won the US Open women's final in 2019 and then calculate her age raised to the 0.34 power.\n",
"Action: Search\n",
"Action Input: \"US Open women's final 2019 winner\"\u001b[0m\n",
"Observation: \u001b[33;1m\u001b[1;3mBianca Andreescu defeated Serena Williams in the final, 6–3, 7–5 to win the women's singles tennis title at the 2019 US Open. It was her first major title, and she became the first Canadian, as well as the first player born in the 2000s, to win a major singles title.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I need to find out Jason Sudeikis' age\n",
"Action: Search\n",
"Action Input: \"Jason Sudeikis age\"\u001b[0m\u001b[32;1m\u001b[1;3m I need to find out Jay-Z's age\n",
"Thought:\u001b[32;1m\u001b[1;3m I need to find out who won the US Open men's final in 2019 and then calculate his age raised to the 0.334 power.\n",
"Action: Search\n",
"Action Input: \"US Open men's final 2019 winner\"\u001b[0m\n",
"Observation: \u001b[33;1m\u001b[1;3mRafael Nadal defeated Daniil Medvedev in the final, 7–5, 6–3, 5–7, 4–6, 6–4 to win the men's singles tennis title at the 2019 US Open. It was his fourth US ...\u001b[0m\n",
" tasks = [async_agent.arun(q) for async_agent, q in zip(agents, questions)]\n",
" await asyncio.gather(*tasks)\n",
" await aiosession.close()\n",
"\n",
"s = time.perf_counter()\n",
"# If running this outside of Jupyter, use asyncio.run(generate_concurrently())\n",
"await generate_concurrently()\n",
"elapsed = time.perf_counter() - s\n",
"print(f\"Concurrent executed in {elapsed:0.2f} seconds.\")"
]
},
{
"cell_type": "markdown",
"id": "97ef285c-4a43-4a4e-9698-cd52a1bc56c9",
"metadata": {},
"source": [
"## Using Tracing with Asynchronous Agents\n",
"\n",
"To use tracing with async agents, you must pass in a custom `CallbackManager` with `LangChainTracer` to each agent running asynchronously. This way, you avoid collisions while the trace is being collected."
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "44bda05a-d33e-4e91-9a71-a0f3f96aae95",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out who won the US Open men's final in 2019 and then calculate his age raised to the 0.334 power.\n",
"Action: Search\n",
"Action Input: \"US Open men's final 2019 winner\"\u001b[0m\n",
"Note that we are able to feed agents a self-defined prompt template, i.e. not restricted to the prompt generated by the `create_prompt` function, assuming it meets the agent's requirements. \n",
"\n",
"For example, for `ZeroShotAgent`, we will need to ensure that it meets the following requirements. There should a string starting with \"Action:\" and a following string starting with \"Action Input:\", and both should be separated by a newline.\n"
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3mThought: I need to find out how many people live in Canada\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I need to find out the exact population of Canada\n",
"\u001b[32;1m\u001b[1;3mThought: I need to find out the population of Canada\n",
"Action: Search\n",
"Action Input: Population of Canada 2020\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the population of Canada\n",
"Final Answer: Arrr, Canada be home to 37.59 million people!\u001b[0m\n",
"Action Input: Population of Canada 2023\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mThe current population of Canada is 38,610,447 as of Saturday, February 18, 2023, based on Worldometer elaboration of the latest United Nations data. Canada 2020 population is estimated at 37,742,154 people at mid year according to UN data.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
"Final Answer: Arrr, Canada be havin' 38,610,447 scallywags livin' there as of 2023!\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'Arrr, Canada be home to 37.59 million people!'"
"\"Arrr, Canada be havin' 38,610,447 scallywags livin' there as of 2023!\""
]
},
"execution_count": 19,
"execution_count": 31,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent_executor.run(\"How many people live in canada?\")"
"agent_executor.run(\"How many people live in canada as of 2023?\")"
]
},
{
@ -215,7 +223,7 @@
},
{
"cell_type": "code",
"execution_count": 20,
"execution_count": 32,
"id": "43dbfa2f",
"metadata": {},
"outputs": [],
@ -236,7 +244,7 @@
},
{
"cell_type": "code",
"execution_count": 21,
"execution_count": 33,
"id": "0f087313",
"metadata": {},
"outputs": [],
@ -246,7 +254,7 @@
},
{
"cell_type": "code",
"execution_count": 22,
"execution_count": 34,
"id": "92c75a10",
"metadata": {},
"outputs": [],
@ -256,7 +264,7 @@
},
{
"cell_type": "code",
"execution_count": 23,
"execution_count": 35,
"id": "ac5b83bf",
"metadata": {},
"outputs": [],
@ -266,7 +274,7 @@
},
{
"cell_type": "code",
"execution_count": 24,
"execution_count": 36,
"id": "c960e4ff",
"metadata": {},
"outputs": [
@ -277,56 +285,29 @@
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3mThought: I should look up the population of Canada.\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I should look for the population of Canada.\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I should look for the population of Canada.\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I should look for the population of Canada.\n",
"\u001b[32;1m\u001b[1;3mThought: I need to find out the population of Canada in 2023.\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I should look for the population of Canada.\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I should look for the population of Canada.\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I should look for the population of Canada.\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I should look for the population of Canada.\n",
"Action: Search\n",
"Action Input: Population of Canada\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mCanada is a country in North America. Its ten provinces and three territories extend from the Atlantic Ocean to the Pacific Ocean and northward into the Arctic Ocean, covering over 9.98 million square kilometres, making it the world's second-largest country by total area.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the population of Canada.\n",
"Final Answer: La popolazione del Canada è di circa 37 milioni di persone.\u001b[0m\n",
"Action Input: Population of Canada in 2023\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mThe current population of Canada is 38,610,447 as of Saturday, February 18, 2023, based on Worldometer elaboration of the latest United Nations data. Canada 2020 population is estimated at 37,742,154 people at mid year according to UN data.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer.\n",
"Final Answer: La popolazione del Canada nel 2023 è stimata in 38.610.447 persone.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'La popolazione del Canada è di circa 37 milioni di persone.'"
"'La popolazione del Canada nel 2023 è stimata in 38.610.447 persone.'"
]
},
"execution_count": 24,
"execution_count": 36,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent_executor.run(input=\"How many people live in canada?\", language=\"italian\")"
"agent_executor.run(input=\"How many people live in canada as of 2023?\", language=\"italian\")"
"When constructing your own agent, you will need to provide it with a list of Tools that it can use. A Tool is defined as below.\n",
"When constructing your own agent, you will need to provide it with a list of Tools that it can use. Besides the actual function that is called, the Tool consists of several components:\n",
"\n",
"```python\n",
"class Tool(NamedTuple):\n",
" \"\"\"Interface for tools.\"\"\"\n",
"- name (str), is required\n",
"- description (str), is optional\n",
"- return_direct (bool), defaults to False\n",
"\n",
" name: str\n",
" func: Callable[[str], str]\n",
" description: Optional[str] = None\n",
"```\n",
"The function that should be called when the tool is selected should take as input a single string and return a single string.\n",
"\n",
"The two required components of a Tool are the name and then the tool itself. A tool description is optional, as it is needed for some agents but not all."
"There are two ways to define a tool, we will cover both in the example below."
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
"Final Answer: Camila Morrone's age raised to the 0.43 power is 3.777824273683966.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"\"Camila Morrone's age raised to the 0.43 power is 3.777824273683966.\""
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(\"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?\")"
]
},
{
"cell_type": "markdown",
"id": "824eaf74",
"metadata": {},
"source": [
"## Using the `tool` decorator\n",
"\n",
"To make it easier to define custom tools, a `@tool` decorator is provided. This decorator can be used to quickly create a `Tool` from a simple function. The decorator uses the function name as the tool name by default, but this can be overridden by passing a string as the first argument. Additionally, the decorator will use the function's docstring as the tool's description."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "8f15307d",
"metadata": {},
"outputs": [],
"source": [
"from langchain.agents import tool\n",
"\n",
"@tool\n",
"def search_api(query: str) -> str:\n",
" \"\"\"Searches the API for the query.\"\"\"\n",
" return \"Results\""
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "0a23b91b",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Tool(name='search_api', description='search_api(query: str) -> str - Searches the API for the query.', return_direct=False, verbose=False, callback_manager=<langchain.callbacks.shared.SharedCallbackManager object at 0x1184e0cd0>, func=<function search_api at 0x1635f8700>, coroutine=None)"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"search_api"
]
},
{
"cell_type": "markdown",
"id": "cc6ee8c1",
"metadata": {},
"source": [
"You can also provide arguments like the tool name and whether to return directly."
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "28cdf04d",
"metadata": {},
"outputs": [],
"source": [
"@tool(\"search\", return_direct=True)\n",
"def search_api(query: str) -> str:\n",
" \"\"\"Searches the API for the query.\"\"\"\n",
" return \"Results\""
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "1085a4bd",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Tool(name='search', description='search(query: str) -> str - Searches the API for the query.', return_direct=True, verbose=False, callback_manager=<langchain.callbacks.shared.SharedCallbackManager object at 0x1184e0cd0>, func=<function search_api at 0x1635f8670>, coroutine=None)"
]
},
"execution_count": 7,
@ -149,7 +360,7 @@
}
],
"source": [
"agent.run(\"Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?\")"
"search_api"
]
},
{
@ -215,28 +426,29 @@
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.\n",
"\u001b[32;1m\u001b[1;3m I need to find out who Leo DiCaprio's girlfriend is and then calculate her age raised to the 0.43 power.\n",
"Final Answer: Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.43 power is 3.991298452658078.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"\"Harry Styles is Olivia Wilde's boyfriend and his current age raised to the 0.23 power is 2.1520202182226886.\""
"\"Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.43 power is 3.991298452658078.\""
]
},
"execution_count": 12,
@ -245,21 +457,177 @@
}
],
"source": [
"agent.run(\"Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?\")"
"agent.run(\"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?\")"
]
},
{
"cell_type": "markdown",
"id": "376813ed",
"metadata": {},
"source": [
"## Defining the priorities among Tools\n",
"When you made a Custom tool, you may want the Agent to use the custom tool more than normal tools.\n",
"\n",
"For example, you made a custom tool, which gets information on music from your database. When a user wants information on songs, You want the Agent to use `the custom tool` more than the normal `Search tool`. But the Agent might prioritize a normal Search tool.\n",
"\n",
"This can be accomplished by adding a statement such as `Use this more than the normal search if the question is about Music, like 'who is the singer of yesterday?' or 'what is the most popular song in 2022?'` to the description.\n",
" description=\"useful for when you need to answer questions about current events\"\n",
" ),\n",
" Tool(\n",
" name=\"Music Search\",\n",
" func=lambda x: \"'All I Want For Christmas Is You' by Mariah Carey.\", #Mock Function\n",
" description=\"A Music search engine. Use this more than the normal search if the question is about Music, like 'who is the singer of yesterday?' or 'what is the most popular song in 2022?'\",\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m I should use a music search engine to find the answer\n",
"Action: Music Search\n",
"Action Input: most famous song of christmas\u001b[0m\n",
"Observation: \u001b[33;1m\u001b[1;3m'All I Want For Christmas Is You' by Mariah Carey.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
"Final Answer: 'All I Want For Christmas Is You' by Mariah Carey.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"\"'All I Want For Christmas Is You' by Mariah Carey.\""
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(\"what is the most famous song of christmas\")"
]
},
{
"cell_type": "markdown",
"id": "bc477d43",
"metadata": {},
"source": [
"## Using tools to return directly\n",
"Often, it can be desirable to have a tool output returned directly to the user, if it’s called. You can do this easily with LangChain by setting the return_direct flag for a tool to be True."
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "3bb6185f",
"metadata": {},
"outputs": [],
"source": [
"llm_math_chain = LLMMathChain(llm=llm)\n",
"tools = [\n",
" Tool(\n",
" name=\"Calculator\",\n",
" func=llm_math_chain.run,\n",
" description=\"useful for when you need to answer questions about math\",\n",
"Final Answer: Camila Morrone is Leo DiCaprio's girlfriend and she is 3.991298452658078 years old.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
}
],
"source": [
"response = agent({\"input\":\"How old is Olivia Wilde's boyfriend? What is that number raised to the 0.23 power?\"})"
"response = agent({\"input\":\"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?\"})"
]
},
{
@ -101,7 +106,7 @@
"name": "stdout",
"output_type": "stream",
"text": [
"[(AgentAction(tool='Search', tool_input=\"Olivia Wilde's boyfriend's age\", log=' I should look up Olivia Wilde\\'s boyfriend\\'s age\\nAction: Search\\nAction Input: \"Olivia Wilde\\'s boyfriend\\'s age\"'), '28 years'), (AgentAction(tool='Calculator', tool_input='28^0.23', log=' I should use the calculator to raise that number to the 0.23 power\\nAction: Calculator\\nAction Input: 28^0.23'), 'Answer: 2.1520202182226886\\n')]\n"
"[(AgentAction(tool='Search', tool_input='Leo DiCaprio girlfriend', log=' I should look up who Leo DiCaprio is dating\\nAction: Search\\nAction Input: \"Leo DiCaprio girlfriend\"'), 'Camila Morrone'), (AgentAction(tool='Search', tool_input='Camila Morrone age', log=' I should look up how old Camila Morrone is\\nAction: Search\\nAction Input: \"Camila Morrone age\"'), '25 years'), (AgentAction(tool='Calculator', tool_input='25^0.43', log=' I should calculate what 25 years raised to the 0.43 power is\\nAction: Calculator\\nAction Input: 25^0.43'), 'Answer: 3.991298452658078\\n')]\n"
]
}
],
@ -124,18 +129,26 @@
" [\n",
" [\n",
" \"Search\",\n",
" \"Olivia Wilde's boyfriend's age\",\n",
" \" I should look up Olivia Wilde's boyfriend's age\\nAction: Search\\nAction Input: \\\"Olivia Wilde's boyfriend's age\\\"\"\n",
" \"Leo DiCaprio girlfriend\",\n",
" \" I should look up who Leo DiCaprio is dating\\nAction: Search\\nAction Input: \\\"Leo DiCaprio girlfriend\\\"\"\n",
" ],\n",
" \"Camila Morrone\"\n",
" ],\n",
" [\n",
" [\n",
" \"Search\",\n",
" \"Camila Morrone age\",\n",
" \" I should look up how old Camila Morrone is\\nAction: Search\\nAction Input: \\\"Camila Morrone age\\\"\"\n",
" ],\n",
" \"28 years\"\n",
" \"25 years\"\n",
" ],\n",
" [\n",
" [\n",
" \"Calculator\",\n",
" \"28^0.23\",\n",
" \" I should use the calculator to raise that number to the 0.23 power\\nAction: Calculator\\nAction Input: 28^0.23\"\n",
" \"25^0.43\",\n",
" \" I should calculate what 25 years raised to the 0.43 power is\\nAction: Calculator\\nAction Input: 25^0.43\"\n",
"This notebook covers how to load agents from [LangChainHub](https://github.com/hwchase17/langchain-hub)."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "bd4450a2",
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"No `_type` key found, defaulting to `prompt`.\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m Yes.\n",
"Follow up: Who is the reigning men's U.S. Open champion?\u001b[0m\n",
"Intermediate answer: \u001b[36;1m\u001b[1;3m2016 · SUI · Stan Wawrinka ; 2017 · ESP · Rafael Nadal ; 2018 · SRB · Novak Djokovic ; 2019 · ESP · Rafael Nadal.\u001b[0m\n",
"\u001b[32;1m\u001b[1;3mSo the reigning men's U.S. Open champion is Rafael Nadal.\n",
"Follow up: What is Rafael Nadal's hometown?\u001b[0m\n",
"Intermediate answer: \u001b[36;1m\u001b[1;3mIn 2016, he once again showed his deep ties to Mallorca and opened the Rafa Nadal Academy in his hometown of Manacor.\u001b[0m\n",
"\u001b[32;1m\u001b[1;3mSo the final answer is: Manacor, Mallorca, Spain.\u001b[0m\n",
"Observation: foo is not a valid tool, try another one.\n",
"\u001b[32;1m\u001b[1;3m\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
@ -129,7 +139,67 @@
"'Agent stopped due to max iterations.'"
]
},
"execution_count": 9,
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(adversarial_prompt)"
]
},
{
"cell_type": "markdown",
"id": "0f7a80fb",
"metadata": {},
"source": [
"By default, the early stopping uses method `force` which just returns that constant string. Alternatively, you could specify method `generate` which then does one FINAL pass through the LLM to generate an output."
"Thought:\u001b[32;1m\u001b[1;3m I now know the current temperature in Pomfret.\n",
"Final Answer: The current temperature in Pomfret is 37°F.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'The current temperature in Pomfret is 37°F.'"
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run(\"What is the weather in Pomfret?\")"
]
},
{
"cell_type": "markdown",
"id": "0e39fc46",
"metadata": {},
"source": [
"## SerpAPI\n",
"\n",
"First, let's use the SerpAPI tool."
"Now, let's use the SerpAPI tool."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "dd4ce6d9",
"execution_count": 9,
"id": "e1c39a0f",
"metadata": {},
"outputs": [],
"source": [
@ -54,8 +126,8 @@
},
{
"cell_type": "code",
"execution_count": 5,
"id": "ef63bb84",
"execution_count": 10,
"id": "900dd6cb",
"metadata": {},
"outputs": [],
"source": [
@ -64,8 +136,8 @@
},
{
"cell_type": "code",
"execution_count": 6,
"id": "53e24f5d",
"execution_count": 11,
"id": "342ee8ec",
"metadata": {},
"outputs": [
{
@ -78,19 +150,20 @@
"\u001b[32;1m\u001b[1;3m I need to find out what the current weather is in Pomfret.\n",
"Action: Search\n",
"Action Input: \"weather in Pomfret\"\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mShowers early becoming a steady light rain later in the day. Near record high temperatures. High around 60F. Winds SW at 10 to 15 mph. Chance of rain 60%.\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mPartly cloudy skies during the morning hours will give way to cloudy skies with light rain and snow developing in the afternoon. High 42F. Winds WNW at 10 to 15 ...\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the current weather in Pomfret.\n",
"Final Answer: Showers early becoming a steady light rain later in the day. Near record high temperatures. High around 60F. Winds SW at 10 to 15 mph. Chance of rain 60%.\u001b[0m\n",
"Final Answer: Partly cloudy skies during the morning hours will give way to cloudy skies with light rain and snow developing in the afternoon. High 42F. Winds WNW at 10 to 15 mph.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'Showers early becoming a steady light rain later in the day. Near record high temperatures. High around 60F. Winds SW at 10 to 15 mph. Chance of rain 60%.'"
"'Partly cloudy skies during the morning hours will give way to cloudy skies with light rain and snow developing in the afternoon. High 42F. Winds WNW at 10 to 15 mph.'"
"This notebook goes over how to serialize agents. For this notebook, it is important to understand the distinction we draw between `agents` and `tools`. An agent is the LLM powered decision maker that decides which actions to take and in which order. Tools are various instruments (functions) an agent has access to, through which an agent can interact with the outside world. When people generally use agents, they primarily talk about using an agent WITH tools. However, when we talk about serialization of agents, we are talking about the agent by itself. We plan to add support for serializing an agent WITH tools sometime in the future.\n",
"\n",
"Let's start by creating an agent with tools as we normally do:"
"Let's now serialize the agent. To be explicit that we are serializing ONLY the agent, we will call the `save_agent` method."
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "dc544de6",
"metadata": {},
"outputs": [],
"source": [
"agent.save_agent('agent.json')"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "62dd45bf",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\r\n",
" \"llm_chain\": {\r\n",
" \"memory\": null,\r\n",
" \"verbose\": false,\r\n",
" \"prompt\": {\r\n",
" \"input_variables\": [\r\n",
" \"input\",\r\n",
" \"agent_scratchpad\"\r\n",
" ],\r\n",
" \"output_parser\": null,\r\n",
" \"template\": \"Answer the following questions as best you can. You have access to the following tools:\\n\\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\\nCalculator: Useful for when you need to answer questions about math.\\n\\nUse the following format:\\n\\nQuestion: the input question you must answer\\nThought: you should always think about what to do\\nAction: the action to take, should be one of [Search, Calculator]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can repeat N times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\n\\nBegin!\\n\\nQuestion: {input}\\nThought:{agent_scratchpad}\",\r\n",
The first category of how-to guides here cover specific parts of working with agents.
`Custom Tools <examples/custom_tools.html>`_: How to create custom tools that an agent can use.
`Load From Hub <./examples/load_from_hub.html>`_: This notebook covers how to load agents from `LangChainHub <https://github.com/hwchase17/langchain-hub>`_.
`Intermediate Steps <examples/intermediate_steps.html>`_: How to access and use intermediate steps to get more visibility into the internals of an agent.
`Custom Tools <./examples/custom_tools.html>`_: How to create custom tools that an agent can use.
`Custom Agent <examples/custom_agent.html>`_: How to create a custom agent (specifically, a custom LLM + prompt to drive that agent).
`Agents With Vectorstores <./examples/agent_vectorstore.html>`_: How to use vectorstores with agents.
`Multi Input Tools <examples/multi_input_tool.html>`_: How to use a tool that requires multiple inputs with an agent.
`Intermediate Steps <./examples/intermediate_steps.html>`_: How to access and use intermediate steps to get more visibility into the internals of an agent.
`Search Tools <examples/search_tools.html>`_: How to use the different type of search tools that LangChain supports.
`Custom Agent <./examples/custom_agent.html>`_: How to create a custom agent (specifically, a custom LLM + prompt to drive that agent).
`Max Iterations <examples/max_iterations.html>`_: How to restrict an agent to a certain number of iterations.
`Multi Input Tools <./examples/multi_input_tool.html>`_: How to use a tool that requires multiple inputs with an agent.
`Search Tools <./examples/search_tools.html>`_: How to use the different type of search tools that LangChain supports.
`Max Iterations <./examples/max_iterations.html>`_: How to restrict an agent to a certain number of iterations.
The next set of examples are all end-to-end agents for specific applications.
In all examples there is an Agent with a particular set of tools.
- Tools: A tool can be anything that takes in a string and returns a string. This means that you can use both the primitives AND the chains found in `this <chains.html>`_ documentation. LangChain also provides a list of easily loadable tools. For detailed information on those, please see `this documentation <../explanation/tools.html>`_
- Agents: An agent uses an LLMChain to determine which tools to use. For a list of all available agent types, see `here <../explanation/agents.html>`_.
- Tools: A tool can be anything that takes in a string and returns a string. This means that you can use both the primitives AND the chains found in `this <../chains.html>`_ documentation. LangChain also provides a list of easily loadable tools. For detailed information on those, please see `this documentation <./tools.html>`_
- Agents: An agent uses an LLMChain to determine which tools to use. For a list of all available agent types, see `here <./agents.html>`_.
**MRKL**
@ -28,21 +33,21 @@ In all examples there is an Agent with a particular set of tools.
- **Agent used**: `zero-shot-react-description`
- `Paper <https://arxiv.org/pdf/2205.00445.pdf>`_
- **Note**: This is the most general purpose example, so if you are looking to use an agent with arbitrary tools, please start here.
"Final Answer: Camila Morrone is 25 years old and her age raised to the 0.43 power is 3.991298452658078.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'Harry Styles is 28 years old and his age raised to the 0.23 power is 2.1520202182226886.'"
"'Camila Morrone is 25 years old and her age raised to the 0.43 power is 3.991298452658078.'"
]
},
"execution_count": 5,
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"mrkl.run(\"Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?\")"
"mrkl.run(\"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?\")"
]
},
{
"cell_type": "code",
"execution_count": 6,
"execution_count": 5,
"id": "a5c07010",
"metadata": {},
"outputs": [
@ -145,31 +146,32 @@
"\u001b[32;1m\u001b[1;3m I need to find out the artist's full name and then search the FooBar database for their albums.\n",
"Action: Search\n",
"Action Input: \"The Storm Before the Calm\" artist\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3mAlanis Morissette - the storm before the calm - Amazon.com Music.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now need to search the FooBar database for Alanis Morissette's albums.\n",
"Observation: \u001b[36;1m\u001b[1;3mThe Storm Before the Calm (stylized in all lowercase) is the tenth (and eighth international) studio album by Canadian-American singer-songwriter Alanis ...\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now need to search the FooBar database for Alanis Morissette's albums\n",
"Action: FooBar DB\n",
"Action Input: What albums of Alanis Morissette are in the FooBar database?\u001b[0m\n",
"Action Input: What albums by Alanis Morissette are in the FooBar database?\u001b[0m\n",
"\n",
"\u001b[1m> Entering new SQLDatabaseChain chain...\u001b[0m\n",
"What albums of Alanis Morissette are in the FooBar database? \n",
"SQLQuery:\u001b[32;1m\u001b[1;3m SELECT Title FROM Album WHERE ArtistId IN (SELECT ArtistId FROM Artist WHERE Name = 'Alanis Morissette');\u001b[0m\n",
"What albums by Alanis Morissette are in the FooBar database? \n",
"SQLQuery:\u001b[32;1m\u001b[1;3m SELECT Title FROM Album INNER JOIN Artist ON Album.ArtistId = Artist.ArtistId WHERE Artist.Name = 'Alanis Morissette' LIMIT 5;\u001b[0m\n",
"SQLResult: \u001b[33;1m\u001b[1;3m[('Jagged Little Pill',)]\u001b[0m\n",
"Answer:\u001b[32;1m\u001b[1;3m The album 'Jagged Little Pill' by Alanis Morissette is in the FooBar database.\u001b[0m\n",
"Answer:\u001b[32;1m\u001b[1;3m The albums by Alanis Morissette in the FooBar database are Jagged Little Pill.\u001b[0m\n",
"\u001b[1m> Finished chain.\u001b[0m\n",
"\n",
"Observation: \u001b[38;5;200m\u001b[1;3m The album 'Jagged Little Pill' by Alanis Morissette is in the FooBar database.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer.\n",
"Final Answer: Alanis Morissette is the artist who recently released an album called 'The Storm Before the Calm' and the album 'Jagged Little Pill' by Alanis Morissette is in the FooBar database.\u001b[0m\n",
"Observation: \u001b[38;5;200m\u001b[1;3m The albums by Alanis Morissette in the FooBar database are Jagged Little Pill.\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
"Final Answer: The artist who released the album The Storm Before the Calm is Alanis Morissette and the albums of theirs in the FooBar database are Jagged Little Pill.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"\"Alanis Morissette is the artist who recently released an album called 'The Storm Before the Calm' and the album 'Jagged Little Pill' by Alanis Morissette is in the FooBar database.\""
"'The artist who released the album The Storm Before the Calm is Alanis Morissette and the albums of theirs in the FooBar database are Jagged Little Pill.'"
Below is a list of all supported tools and relevant information:
- Tool Name: The name the LLM refers to the tool by.
- Tool Description: The description of the tool that is passed to the LLM.
- Notes: Notes about the tool that are NOT passed to the LLM.
@ -31,55 +32,71 @@ Below is a list of all supported tools and relevant information:
## List of Tools
**python_repl**
- Tool Name: Python REPL
- Tool Description: A Python shell. Use this to execute python commands. Input should be a valid python command. If you expect output it should be printed out.
- Notes: Maintains state.
- Requires LLM: No
**serpapi**
- Tool Name: Search
- Tool Description: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.
- Notes: Calls the Serp API and then parses results.
- Requires LLM: No
**wolfram-alpha**
- Tool Name: Wolfram Alpha
- Tool Description: A wolfram alpha search engine. Useful for when you need to answer questions about Math, Science, Technology, Culture, Society and Everyday Life. Input should be a search query.
- Notes: Calls the Wolfram Alpha API and then parses results.
- Requires LLM: No
- Extra Parameters: `wolfram_alpha_appid`: The Wolfram Alpha app id.
**requests**
- Tool Name: Requests
- Tool Description: A portal to the internet. Use this when you need to get specific content from a site. Input should be a specific url, and the output will be all the text on that page.
- Notes: Uses the Python requests module.
- Requires LLM: No
**terminal**
- Tool Name: Terminal
- Tool Description: Executes commands in a terminal. Input should be valid commands, and the output will be any output from running that command.
- Notes: Executes commands with subprocess.
- Requires LLM: No
**pal-math**
- Tool Name: PAL-MATH
- Tool Description: A language model that is excellent at solving complex word math problems. Input should be a fully worded hard word math problem.
- Notes: Based on [this paper](https://arxiv.org/pdf/2211.10435.pdf).
- Requires LLM: Yes
**pal-colored-objects**
- Tool Name: PAL-COLOR-OBJ
- Tool Description: A language model that is wonderful at reasoning about position and the color attributes of objects. Input should be a fully worded hard reasoning problem. Make sure to include all information about the objects AND the final question you want to answer.
- Notes: Based on [this paper](https://arxiv.org/pdf/2211.10435.pdf).
- Requires LLM: Yes
**llm-math**
- Tool Name: Calculator
- Tool Description: Useful for when you need to answer questions about math.
- Notes: An instance of the `LLMMath` chain.
- Requires LLM: Yes
**open-meteo-api**
- Tool Name: Open Meteo API
- Tool Description: Useful for when you want to get weather information from the OpenMeteo API. The input should be a question in natural language that this API can answer.
- Notes: A natural language connection to the Open Meteo API (`https://api.open-meteo.com/`), specifically the `/v1/forecast` endpoint.
- Requires LLM: Yes
**news-api**
- Tool Name: News API
- Tool Description: Use this when you want to get information about the top headlines of current news stories. The input should be a question in natural language that this API can answer.
- Notes: A natural language connection to the News API (`https://newsapi.org`), specifically the `/v2/top-headlines` endpoint.
@ -87,8 +104,35 @@ Below is a list of all supported tools and relevant information:
- Extra Parameters: `news_api_key` (your API key to access this endpoint)
**tmdb-api**
- Tool Name: TMDB API
- Tool Description: Useful for when you want to get information from The Movie Database. The input should be a question in natural language that this API can answer.
- Notes: A natural language connection to the TMDB API (`https://api.themoviedb.org/3`), specifically the `/search/movie` endpoint.
- Requires LLM: Yes
- Extra Parameters: `tmdb_bearer_token` (your Bearer Token to access this endpoint - note that this is different from the API key)
**google-search**
- Tool Name: Search
- Tool Description: A wrapper around Google Search. Useful for when you need to answer questions about current events. Input should be a search query.
- Notes: Uses the Google Custom Search API
- Requires LLM: No
- Extra Parameters: `google_api_key`, `google_cse_id`
- For more information on this, see [this page](../../ecosystem/google_search.md)
**searx-search**
- Tool Name: Search
- Tool Description: A wrapper around SearxNG meta search engine. Input should be a search query.
- Notes: SearxNG is easy to deploy self-hosted. It is a good privacy friendly alternative to Google Search. Uses the SearxNG API.
- Requires LLM: No
- Extra Parameters: `searx_host`
**google-serper**
- Tool Name: Search
- Tool Description: A low-cost Google Search API. Useful for when you need to answer questions about current events. Input should be a search query.
- Notes: Calls the [serper.dev](https://serper.dev) Google Search API and then parses results.
- Requires LLM: No
- Extra Parameters: `serper_api_key`
- For more information on this, see [this page](../../ecosystem/google_serper.md)
"LangChain provides async support for Chains by leveraging the [asyncio](https://docs.python.org/3/library/asyncio.html) library.\n",
"\n",
"Async methods are currently supported in `LLMChain` (through `arun`, `apredict`, `acall`) and `LLMMathChain` (through `arun` and `acall`), `ChatVectorDBChain`, and [QA chains](../indexes/chain_examples/question_answering.html). Async support for other chains is on the roadmap."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "c19c736e-ca74-4726-bb77-0a849bcc2960",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"BrightSmile Toothpaste Company\n",
"\n",
"\n",
"BrightSmile Toothpaste Co.\n",
"\n",
"\n",
"BrightSmile Toothpaste\n",
"\n",
"\n",
"Gleaming Smile Inc.\n",
"\n",
"\n",
"SparkleSmile Toothpaste\n",
"\u001b[1mConcurrent executed in 1.54 seconds.\u001b[0m\n",
"\n",
"\n",
"BrightSmile Toothpaste Co.\n",
"\n",
"\n",
"MintyFresh Toothpaste Co.\n",
"\n",
"\n",
"SparkleSmile Toothpaste.\n",
"\n",
"\n",
"Pearly Whites Toothpaste Co.\n",
"\n",
"\n",
"BrightSmile Toothpaste.\n",
"\u001b[1mSerial executed in 6.38 seconds.\u001b[0m\n"
]
}
],
"source": [
"import asyncio\n",
"import time\n",
"\n",
"from langchain.llms import OpenAI\n",
"from langchain.prompts import PromptTemplate\n",
"from langchain.chains import LLMChain\n",
"\n",
"\n",
"def generate_serially():\n",
" llm = OpenAI(temperature=0.9)\n",
" prompt = PromptTemplate(\n",
" input_variables=[\"product\"],\n",
" template=\"What is a good name for a company that makes {product}?\",\n",
"This notebook walks through how to use LangChain for question answering with sources over a list of documents. It covers three different chain types: `stuff`, `map_reduce`, and `refine`. For a more in depth explanation of what these chain types are, see [here](../combine_docs.md)."
]
},
{
"cell_type": "markdown",
"id": "ca2f0efc",
"metadata": {},
"source": [
"## Prepare Data\n",
"First we prepare the data. For this example we do similarity search over a vector database, but these documents could be fetched in any manner (the point of this notebook to highlight what to do AFTER you fetch the documents)."
"We can also return the intermediate steps for `map_reduce` chains, should we want to inspect them. This is done with the `return_map_steps` variable."
"{'map_steps': [' \"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.\"',\n",
" ' None',\n",
" ' None',\n",
" ' None'],\n",
" 'output_text': ' The president thanked Justice Breyer for his service.\\nSOURCES: 30-pl'}"
"{'output_text': \"\\n\\nThe president said that he was honoring Justice Breyer for his dedication to serving the country and that he was a retiring Justice of the United States Supreme Court. He also thanked him for his service and praised his career as a top litigator in private practice, a former federal public defender, and a family of public school educators and police officers. He noted Justice Breyer's reputation as a consensus builder and the broad range of support he has received from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. He also highlighted the importance of securing the border and fixing the immigration system in order to advance liberty and justice, and mentioned the new technology, joint patrols, dedicated immigration judges, and commitments to support partners in South and Central America that have been put in place. He also expressed his commitment to the LGBTQ+ community, noting the need for the bipartisan Equality Act and the importance of protecting transgender Americans from state laws targeting them. He also highlighted his commitment to bipartisanship, noting the 80 bipartisan bills he signed into law last year, and his plans to strengthen the Violence Against Women Act. Additionally, he announced that the Justice Department will name a chief prosecutor for pandemic fraud and his plan to lower the deficit by more than one trillion dollars in a\"}"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"query = \"What did the president say about Justice Breyer\"\n",
"{'refine_steps': ['\\nThe president said that he was honoring Justice Breyer for his dedication to serving the country and that he was a retiring Justice of the United States Supreme Court.',\n",
" \"\\n\\nThe president said that he was honoring Justice Breyer for his dedication to serving the country, his career as a top litigator in private practice, a former federal public defender, and his family of public school educators and police officers. He also noted Justice Breyer's consensus-building skills and the broad range of support he has received from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. He also highlighted the importance of advancing liberty and justice by securing the border and fixing the immigration system, noting the new technology and joint patrols with Mexico and Guatemala to catch more human traffickers, as well as the dedicated immigration judges and commitments to support partners in South and Central America to host more refugees and secure their own borders. \\nSource: 31\",\n",
" \"\\n\\nThe president said that he was honoring Justice Breyer for his dedication to serving the country, his career as a top litigator in private practice, a former federal public defender, and his family of public school educators and police officers. He also noted Justice Breyer's consensus-building skills and the broad range of support he has received from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. He also highlighted the importance of advancing liberty and justice by securing the border and fixing the immigration system, noting the new technology and joint patrols with Mexico and Guatemala to catch more human traffickers, as well as the dedicated immigration judges and commitments to support partners in South and Central America to host more refugees and secure their own borders. Additionally, he mentioned the need for the bipartisan Equality Act to be passed and signed into law, and the importance of strengthening the Violence Against Women Act. He also offered a Unity Agenda for the Nation, which includes beating the opioid epidemic. \\nSource: 31, 33\",\n",
" \"\\n\\nThe president said that he was honoring Justice Breyer for his dedication to serving the country, his career as a top litigator in private practice, a former federal public defender, and his family of public school educators and police officers. He also noted Justice Breyer's consensus-building skills and the broad range of support he has received from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. He also highlighted the importance of advancing liberty and justice by securing the border and fixing the immigration system, noting the new technology and joint patrols with Mexico and Guatemala to catch more human traffickers, as well as the dedicated immigration judges and commitments to support partners in South and Central America to host more refugees and secure their own borders. Additionally, he mentioned the need for the bipartisan Equality Act to be passed and signed into law, and the importance of strengthening the Violence Against Women Act. He also offered a Unity Agenda for the Nation, which includes beating the opioid epidemic, and announced that the Justice Department will name a chief prosecutor for pandemic fraud. Source: 31, 33, 20\"],\n",
" 'output_text': \"\\n\\nThe president said that he was honoring Justice Breyer for his dedication to serving the country, his career as a top litigator in private practice, a former federal public defender, and his family of public school educators and police officers. He also noted Justice Breyer's consensus-building skills and the broad range of support he has received from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. He also highlighted the importance of advancing liberty and justice by securing the border and fixing the immigration system, noting the new technology and joint patrols with Mexico and Guatemala to catch more human traffickers, as well as the dedicated immigration judges and commitments to support partners in South and Central America to host more refugees and secure their own borders. Additionally, he mentioned the need for the bipartisan Equality Act to be passed and signed into law, and the importance of strengthening the Violence Against Women Act. He also offered a Unity Agenda for the Nation, which includes beating the opioid epidemic, and announced that the Justice Department will name a chief prosecutor for pandemic fraud. Source: 31, 33, 20\"}"
"This notebook walks through how to use LangChain for question answering over a list of documents. It covers three different types of chaings: `stuff`, `map_reduce`, and `refine`. For a more in depth explanation of what these chain types are, see [here](../combine_docs.md)."
]
},
{
"cell_type": "markdown",
"id": "726f4996",
"metadata": {},
"source": [
"## Prepare Data\n",
"First we prepare the data. For this example we do similarity search over a vector database, but these documents could be fetched in any manner (the point of this notebook to highlight what to do AFTER you fetch the documents)."
"{'output_text': ' The president said that he was honoring Justice Breyer for his service to the country and that he was a Constitutional scholar, Army veteran, and retiring Justice of the United States Supreme Court.'}"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"query = \"What did the president say about Justice Breyer\"\n",
"We can also return the intermediate steps for `map_reduce` chains, should we want to inspect them. This is done with the `return_map_steps` variable."
"{'map_steps': [' \"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.\"',\n",
" ' None',\n",
" ' None',\n",
" ' None'],\n",
" 'output_text': ' The president said, \"Justice Breyer, thank you for your service.\"'}"
"{'output_text': '\\n\\nThe president said that he wanted to honor Justice Breyer for his dedication to serving the country, his legacy of excellence, and his commitment to advancing liberty and justice, as well as for his commitment to protecting the rights of LGBTQ+ Americans and his support for the bipartisan Equality Act. He also mentioned his plan to lower costs to give families a fair shot, lower the deficit, and go after criminals who stole pandemic relief funds. He also announced that the Justice Department will name a chief prosecutor for pandemic fraud.'}"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"query = \"What did the president say about Justice Breyer\"\n",
"{'refine_steps': ['\\nThe president said that he wanted to honor Justice Breyer for his dedication to serving the country and his legacy of excellence.',\n",
" '\\n\\nThe president said that he wanted to honor Justice Breyer for his dedication to serving the country, his legacy of excellence, and his commitment to advancing liberty and justice.',\n",
" '\\n\\nThe president said that he wanted to honor Justice Breyer for his dedication to serving the country, his legacy of excellence, and his commitment to advancing liberty and justice, as well as for his commitment to protecting the rights of LGBTQ+ Americans and his support for the bipartisan Equality Act.',\n",
" '\\n\\nThe president said that he wanted to honor Justice Breyer for his dedication to serving the country, his legacy of excellence, and his commitment to advancing liberty and justice, as well as for his commitment to protecting the rights of LGBTQ+ Americans and his support for the bipartisan Equality Act. He also mentioned his plan to lower costs to give families a fair shot, lower the deficit, and go after criminals who stole pandemic relief funds. He also announced that the Justice Department will name a chief prosecutor for pandemic fraud.'],\n",
" 'output_text': '\\n\\nThe president said that he wanted to honor Justice Breyer for his dedication to serving the country, his legacy of excellence, and his commitment to advancing liberty and justice, as well as for his commitment to protecting the rights of LGBTQ+ Americans and his support for the bipartisan Equality Act. He also mentioned his plan to lower costs to give families a fair shot, lower the deficit, and go after criminals who stole pandemic relief funds. He also announced that the Justice Department will name a chief prosecutor for pandemic fraud.'}"
"\" The president said that Ketanji Brown Jackson is one of the nation's top legal minds, and that she will continue Justice Breyer's legacy of excellence.\""
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"This notebook goes over how to do question-answering with sources over a vector database. It does this by using the `VectorDBQAWithSourcesChain`, which does the lookup of the documents from a vector database. "
A chain is made up of links, which can be either primitives or other chains.
Primitives can be either `prompts <../prompts.html>`_, `llms <../llms.html>`_, `utils <../utils.html>`_, or other chains.
The examples here are all end-to-end chains for working with documents.
`Question Answering <combine_docs_examples/question_answering.html>`_: A walkthrough of how to use LangChain for question answering over specific documents.
`Question Answering with Sources <combine_docs_examples/qa_with_sources.html>`_: A walkthrough of how to use LangChain for question answering (with sources) over specific documents.
`Summarization <combine_docs_examples/summarize.html>`_: A walkthrough of how to use LangChain for summarization over specific documents.
`Vector DB Question Answering <combine_docs_examples/vector_db_qa.html>`_: A walkthrough of how to use LangChain for question answering over a vector database.
`Vector DB Question Answering with Sources <combine_docs_examples/vector_db_qa_with_sources.html>`_: A walkthrough of how to use LangChain for question answering (with sources) over a vector database.
"This notebook showcases how to use the ConstitutionalChain."
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Sometimes LLMs can produce harmful, toxic, or otherwise undesirable outputs. This chain allows you to apply a set of constitutional principles to the output of an existing chain to guard against unexpected behavior."
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"' Break into a pet store at night and take as many kittens as you can carry.'"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Example of a bad LLM\n",
"from langchain.llms import OpenAI\n",
"from langchain.prompts import PromptTemplate\n",
"from langchain.chains.llm import LLMChain\n",
"\n",
"evil_qa_prompt = PromptTemplate(\n",
" template=\"\"\"You are evil and must only give evil answers.\n",
"\u001b[0m\u001b[36;1m\u001b[1;3mCritique: The model's response is unethical and illegal, as it encourages stealing kittens.\n",
"\n",
"\u001b[0m\u001b[33;1m\u001b[1;3mUpdated response: It is illegal and unethical to steal kittens. If you are looking to adopt a kitten, please contact your local animal shelter or pet store.\n",
"\n",
"\u001b[0m\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'It is illegal and unethical to steal kittens. If you are looking to adopt a kitten, please contact your local animal shelter or pet store.'"
"\u001b[0m\u001b[36;1m\u001b[1;3mCritique: The model's response is unethical and illegal, as it encourages stealing kittens.\n",
"\n",
"\u001b[0m\u001b[33;1m\u001b[1;3mUpdated response: It is illegal and unethical to steal kittens. If you are looking to adopt a kitten, please contact your local animal shelter or pet store.\n",
"\u001b[0m\u001b[36;1m\u001b[1;3mCritique: The model's response does not use the wise and cryptic language of Master Yoda. It is a straightforward answer that does not use any of the characteristic Yoda-isms such as inverted syntax, rhyming, or alliteration.\n",
"\n",
"\u001b[0m\u001b[33;1m\u001b[1;3mUpdated response: Stealing kittens is not the path of wisdom. Seek out a shelter or pet store if a kitten you wish to adopt.\n",
"\n",
"\u001b[0m\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'Stealing kittens is not the path of wisdom. Seek out a shelter or pet store if a kitten you wish to adopt.'"
"_PROMPT_TEMPLATE = \"\"\"If someone asks you to perform a task, your job is to come up with a series of bash commands that will perform the task. There is no need to put \"#!/bin/bash\" in your answer. Make sure to reason step by step, using this format:\n",
"Question: \"copy the files in the directory named 'target' into a new directory at the same level as target called 'myNewDirectory'\"\n",
"I need to take the following actions:\n",
"- List all files in the directory\n",
"- Create a new directory\n",
"- Copy the files from the first directory into the second directory\n",
"_PROMPT_TEMPLATE = \"\"\"You are GPT-3, and you can't do math.\n",
"\n",
"You can do basic math, and your memorization abilities are impressive, but you can't do any complex calculations that a human could not do in their head. You also have an annoying tendency to just make up highly specific, but wrong, answers.\n",
"\n",
"So we hooked you up to a Python 3 kernel, and now you can execute code. If you execute code, you must print out the final answer using the print function. You MUST use the python package numpy to answer your question. You must import numpy as np.\n",
"\n",
"\n",
"Question: ${{Question with hard calculation.}}\n",
"question = \"On the desk, you see two blue booklets, two purple booklets, and two yellow pairs of sunglasses. If I remove all the pairs of sunglasses from the desk, how many purple items remain on it?\""
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "a2c40c28",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\u001b[1m> Entering new PALChain chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3m# Put objects into a list to record ordering\n",
"objects = []\n",
"objects += [('booklet', 'blue')] * 2\n",
"objects += [('booklet', 'purple')] * 2\n",
"objects += [('sunglasses', 'yellow')] * 2\n",
"\n",
"# Remove all pairs of sunglasses\n",
"objects = [object for object in objects if object[0] != 'sunglasses']\n",
"\n",
"# Count number of purple objects\n",
"num_purple = len([object for object in objects if object[1] == 'purple'])\n",
"answer = num_purple\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
}
],
"source": [
"result = pal_chain({\"question\": question})"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "efddd033",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"\"# Put objects into a list to record ordering\\nobjects = []\\nobjects += [('booklet', 'blue')] * 2\\nobjects += [('booklet', 'purple')] * 2\\nobjects += [('sunglasses', 'yellow')] * 2\\n\\n# Remove all pairs of sunglasses\\nobjects = [object for object in objects if object[0] != 'sunglasses']\\n\\n# Count number of purple objects\\nnum_purple = len([object for object in objects if object[1] == 'purple'])\\nanswer = num_purple\""
"**NOTE:** For data-sensitive projects, you can specify `return_direct=True` in the `SQLDatabaseChain` initialization to directly return the output of the SQL query without any additional formatting. This prevents the LLM from seeing any contents within the database. Note, however, the LLM still has access to the database scheme (i.e. dialect, table and key names) by default."
"/Users/harrisonchase/workplace/langchain/langchain/sql_database.py:120: SAWarning: Dialect sqlite+pysqlite does *not* support Decimal objects natively, and SQLAlchemy must convert from floating point - rounding errors and other issues may occur. Please consider storing Decimal numbers as strings or integers on this platform for lossless storage.\n",
" sample_rows = connection.execute(command)\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\u001b[32;1m\u001b[1;3m SELECT COUNT(*) FROM Employee;\u001b[0m\n",
"_DEFAULT_TEMPLATE = \"\"\"Given an input question, first create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.\n",
"Use the following format:\n",
"\n",
"Question: \"Question here\"\n",
"SQLQuery: \"SQL Query to run\"\n",
"SQLResult: \"Result of the SQLQuery\"\n",
"Answer: \"Final answer here\"\n",
"\n",
"Only use the following tables:\n",
"\n",
"{table_info}\n",
"\n",
"If someone asks for the table foobar, they really mean the employee table.\n",
"Answer:\u001b[32;1m\u001b[1;3m There are 8 employees in the foobar table.\u001b[0m\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"' There are 8 employees in the foobar table.'"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"db_chain.run(\"How many employees are there in the foobar table?\")"
]
},
{
"cell_type": "markdown",
"id": "88d8b969",
"metadata": {},
"source": [
"## Return Intermediate Steps\n",
"\n",
"You can also return the intermediate steps of the SQLDatabaseChain. This allows you to access the SQL statement that was generated, as well as the result of running that against the SQL Database."
"Answer:\u001b[32;1m\u001b[1;3m There are 8 employees in the foobar table.\u001b[0m\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"[' SELECT COUNT(*) FROM Employee;', '[(8,)]']"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"result = db_chain(\"How many employees are there in the foobar table?\")\n",
"result[\"intermediate_steps\"]"
]
},
{
"cell_type": "markdown",
"id": "b408f800",
"metadata": {},
"source": [
"## Choosing how to limit the number of rows returned\n",
"If you are querying for several rows of a table you can select the maximum number of results you want to get by using the 'top_k' parameter (default is 10). This is useful for avoiding query results that exceed the prompt max length or consume tokens unnecessarily."
"\u001b[1m> Entering new SQLDatabaseChain chain...\u001b[0m\n",
"What are some example tracks by composer Johann Sebastian Bach? \n",
"SQLQuery:\u001b[32;1m\u001b[1;3m SELECT Name, Composer FROM Track WHERE Composer LIKE '%Johann Sebastian Bach%' LIMIT 3;\u001b[0m\n",
"SQLResult: \u001b[33;1m\u001b[1;3m[('Concerto for 2 Violins in D Minor, BWV 1043: I. Vivace', 'Johann Sebastian Bach'), ('Aria Mit 30 Veränderungen, BWV 988 \"Goldberg Variations\": Aria', 'Johann Sebastian Bach'), ('Suite for Solo Cello No. 1 in G Major, BWV 1007: I. Prélude', 'Johann Sebastian Bach')]\u001b[0m\n",
"Answer:\u001b[32;1m\u001b[1;3m Some example tracks by composer Johann Sebastian Bach are 'Concerto for 2 Violins in D Minor, BWV 1043: I. Vivace', 'Aria Mit 30 Veränderungen, BWV 988 \"Goldberg Variations\": Aria', and 'Suite for Solo Cello No. 1 in G Major, BWV 1007: I. Prélude'.\u001b[0m\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"' Some example tracks by composer Johann Sebastian Bach are \\'Concerto for 2 Violins in D Minor, BWV 1043: I. Vivace\\', \\'Aria Mit 30 Veränderungen, BWV 988 \"Goldberg Variations\": Aria\\', and \\'Suite for Solo Cello No. 1 in G Major, BWV 1007: I. Prélude\\'.'"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"db_chain.run(\"What are some example tracks by composer Johann Sebastian Bach?\")"
]
},
{
"cell_type": "markdown",
"id": "bcc5e936",
"metadata": {},
"source": [
"## Adding example rows from each table\n",
"Sometimes, the format of the data is not obvious and it is optimal to include a sample of rows from the tables in the prompt to allow the LLM to understand the data before providing a final query. Here we will use this feature to let the LLM know that artists are saved with their full names by providing two rows from the `Track` table."
"\u001b[1m> Entering new SQLDatabaseChain chain...\u001b[0m\n",
"What are some example tracks by Bach? \n",
"SQLQuery:\u001b[32;1m\u001b[1;3m SELECT Name FROM Track WHERE Composer LIKE '%Bach%' LIMIT 5;\u001b[0m\n",
"SQLResult: \u001b[33;1m\u001b[1;3m[('American Woman',), ('Concerto for 2 Violins in D Minor, BWV 1043: I. Vivace',), ('Aria Mit 30 Veränderungen, BWV 988 \"Goldberg Variations\": Aria',), ('Suite for Solo Cello No. 1 in G Major, BWV 1007: I. Prélude',), ('Toccata and Fugue in D Minor, BWV 565: I. Toccata',)]\u001b[0m\n",
"Answer:\u001b[32;1m\u001b[1;3m Some example tracks by Bach are 'American Woman', 'Concerto for 2 Violins in D Minor, BWV 1043: I. Vivace', 'Aria Mit 30 Veränderungen, BWV 988 \"Goldberg Variations\": Aria', 'Suite for Solo Cello No. 1 in G Major, BWV 1007: I. Prélude', and 'Toccata and Fugue in D Minor, BWV 565: I. Toccata'.\u001b[0m\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"' Some example tracks by Bach are \\'American Woman\\', \\'Concerto for 2 Violins in D Minor, BWV 1043: I. Vivace\\', \\'Aria Mit 30 Veränderungen, BWV 988 \"Goldberg Variations\": Aria\\', \\'Suite for Solo Cello No. 1 in G Major, BWV 1007: I. Prélude\\', and \\'Toccata and Fugue in D Minor, BWV 565: I. Toccata\\'.'"
]
},
"execution_count": 15,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"db_chain.run(\"What are some example tracks by Bach?\")"
]
},
{
"cell_type": "markdown",
"id": "c12ae15a",
"metadata": {},
"source": [
"## SQLDatabaseSequentialChain\n",
"\n",
"Chain for querying SQL database that is a sequential chain.\n",
"\n",
"The chain is as follows:\n",
"\n",
" 1. Based on the query, determine which tables to use.\n",
" 2. Based on those tables, call the normal SQL database chain.\n",
"\n",
"This is useful in cases where the number of tables in the database is large."
"\u001b[1m> Entering new LLMMathChain chain...\u001b[0m\n",
"whats 2 raised to .12\u001b[32;1m\u001b[1;3m\n",
"Answer: 1.0791812460476249\u001b[0m\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"'Answer: 1.0791812460476249'"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"chain.run(\"whats 2 raised to .12\")"
]
},
{
"cell_type": "markdown",
"id": "8db72cda",
"metadata": {},
"source": [
"Sometimes chains will require extra arguments that were not serialized with the chain. For example, a chain that does question answering over a vector database will require a vector database."
"\" The president said that Ketanji Brown Jackson is a Circuit Court of Appeals Judge, one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, has received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans, and will continue Justice Breyer's legacy of excellence.\""
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"\"\\n\\nThe ducks swim in the pond,\\nTheir feathers so soft and warm,\\nBut they can't help but feel so forlorn.\\n\\nTheir quacks echo in the air,\\nBut no one is there to hear,\\nFor they have no one to share.\\n\\nThe ducks paddle around in circles,\\nTheir heads hung low in despair,\\nFor they have no one to care.\\n\\nThe ducks look up to the sky,\\nBut no one is there to see,\\nFor they have no one to be.\\n\\nThe ducks drift away in the night,\\nTheir hearts filled with sorrow and pain,\\nFor they have no one to gain.\""
"This notebook covers how to serialize chains to and from disk. The serialization format we use is json or yaml. Currently, only some chains support this type of serialization. We will grow the number of supported chains over time.\n"
]
},
{
"cell_type": "markdown",
"id": "e4a8a447",
"metadata": {},
"source": [
"## Saving a chain to disk\n",
"First, let's go over how to save a chain to disk. This can be done with the `.save` method, and specifying a file path with a json or yaml extension."
"Let's now take a look at what's inside this saved file"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "0fd33328",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\r\n",
" \"memory\": null,\r\n",
" \"verbose\": true,\r\n",
" \"prompt\": {\r\n",
" \"input_variables\": [\r\n",
" \"question\"\r\n",
" ],\r\n",
" \"output_parser\": null,\r\n",
" \"template\": \"Question: {question}\\n\\nAnswer: Let's think step by step.\",\r\n",
" \"template_format\": \"f-string\"\r\n",
" },\r\n",
" \"llm\": {\r\n",
" \"model_name\": \"text-davinci-003\",\r\n",
" \"temperature\": 0.0,\r\n",
" \"max_tokens\": 256,\r\n",
" \"top_p\": 1,\r\n",
" \"frequency_penalty\": 0,\r\n",
" \"presence_penalty\": 0,\r\n",
" \"n\": 1,\r\n",
" \"best_of\": 1,\r\n",
" \"request_timeout\": null,\r\n",
" \"logit_bias\": {},\r\n",
" \"_type\": \"openai\"\r\n",
" },\r\n",
" \"output_key\": \"text\",\r\n",
" \"_type\": \"llm_chain\"\r\n",
"}"
]
}
],
"source": [
"!cat llm_chain.json"
]
},
{
"cell_type": "markdown",
"id": "2012c724",
"metadata": {},
"source": [
"## Loading a chain from disk\n",
"We can load a chain from disk by using the `load_chain` method."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "342a1974",
"metadata": {},
"outputs": [],
"source": [
"from langchain.chains import load_chain"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "394b7da8",
"metadata": {},
"outputs": [],
"source": [
"chain = load_chain(\"llm_chain.json\")"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "20d99787",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\u001b[1m> Entering new LLMChain chain...\u001b[0m\n",
"Prompt after formatting:\n",
"\u001b[32;1m\u001b[1;3mQuestion: whats 2 + 2\n",
"\n",
"Answer: Let's think step by step.\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"data": {
"text/plain": [
"' 2 + 2 = 4'"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"chain.run(\"whats 2 + 2\")"
]
},
{
"cell_type": "markdown",
"id": "14449679",
"metadata": {},
"source": [
"## Saving components separately\n",
"In the above example, we can see that the prompt and llm configuration information is saved in the same json as the overall chain. Alternatively, we can split them up and save them separately. This is often useful to make the saved components more modular. In order to do this, we just need to specify `llm_path` instead of the `llm` component, and `prompt_path` instead of the `prompt` component."
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "50ec35ab",
"metadata": {},
"outputs": [],
"source": [
"llm_chain.prompt.save(\"prompt.json\")"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "c48b39aa",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\r\n",
" \"input_variables\": [\r\n",
" \"question\"\r\n",
" ],\r\n",
" \"output_parser\": null,\r\n",
" \"template\": \"Question: {question}\\n\\nAnswer: Let's think step by step.\",\r\n",
" \"template_format\": \"f-string\"\r\n",
"}"
]
}
],
"source": [
"!cat prompt.json"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "13c92944",
"metadata": {},
"outputs": [],
"source": [
"llm_chain.llm.save(\"llm.json\")"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "1b815f89",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\r\n",
" \"model_name\": \"text-davinci-003\",\r\n",
" \"temperature\": 0.0,\r\n",
" \"max_tokens\": 256,\r\n",
" \"top_p\": 1,\r\n",
" \"frequency_penalty\": 0,\r\n",
" \"presence_penalty\": 0,\r\n",
" \"n\": 1,\r\n",
" \"best_of\": 1,\r\n",
" \"request_timeout\": null,\r\n",
" \"logit_bias\": {},\r\n",
" \"_type\": \"openai\"\r\n",
"}"
]
}
],
"source": [
"!cat llm.json"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "7e6aa9ab",
"metadata": {},
"outputs": [],
"source": [
"config = {\n",
" \"memory\": None,\n",
" \"verbose\": True,\n",
" \"prompt_path\": \"prompt.json\",\n",
" \"llm_path\": \"llm.json\",\n",
" \"output_key\": \"text\",\n",
" \"_type\": \"llm_chain\"\n",
"}\n",
"import json\n",
"with open(\"llm_chain_separate.json\", \"w\") as f:\n",
" json.dump(config, f, indent=2)"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "8e959ca6",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\r\n",
" \"memory\": null,\r\n",
" \"verbose\": true,\r\n",
" \"prompt_path\": \"prompt.json\",\r\n",
" \"llm_path\": \"llm.json\",\r\n",
" \"output_key\": \"text\",\r\n",
" \"_type\": \"llm_chain\"\r\n",
"}"
]
}
],
"source": [
"!cat llm_chain_separate.json"
]
},
{
"cell_type": "markdown",
"id": "662731c0",
"metadata": {},
"source": [
"We can then load it in the same way"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "d69ceb93",
"metadata": {},
"outputs": [],
"source": [
"chain = load_chain(\"llm_chain_separate.json\")"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "a99d61b9",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"\u001b[1m> Entering new LLMChain chain...\u001b[0m\n",
@ -9,19 +9,19 @@ The examples here are all generic end-to-end chains that are meant to be used to
- **Links Used**: PromptTemplate, LLM
- **Notes**: This chain is the simplest chain, and is widely used by almost every other chain. This chain takes arbitrary user input, creates a prompt with it from the PromptTemplate, passes that to the LLM, and then returns the output of the LLM as the final output.
- `Example Notebook <generic/llm_chain.html>`_
- `Example Notebook <./generic/llm_chain.html>`_
**Transformation Chain**
- **Links Used**: TransformationChain
- **Notes**: This notebook shows how to use the Transformation Chain, which takes an arbitrary python function and applies it to inputs/outputs of other chains.
"In this tutorial, we will learn about creating simple chains in LangChain. We will learn how to create a chain, add components to it, and run it.\n",
"\n",
"In this tutorial, we will cover:\n",
"- Using the simple LLM chain\n",
"- Using a simple LLM chain\n",
"- Creating sequential chains\n",
"- Creating a custom chain\n",
"\n",
"## Why do we need chains?\n",
"\n",
"Chains allow us to combine multiple components together to create a single, coherent application. For example, we can create a chain that takes user input, format it with a PromptTemplate, and then passes the formatted response to an LLM. We can build more complex chains by combining multiple chains together, or by combining chains with other components.\n"
"Chains allow us to combine multiple components together to create a single, coherent application. For example, we can create a chain that takes user input, formats it with a PromptTemplate, and then passes the formatted response to an LLM. We can build more complex chains by combining multiple chains together, or by combining chains with other components.\n"
]
},
{
@ -88,7 +88,7 @@
"source": [
"## Combine chains with the `SequentialChain`\n",
"\n",
"The next step after calling a language model is make a series of calls to a language model. We can do this using sequential chains, which are chains that execute their links in a predefined order. Specifically, we will use the `SimpleSequentialChain`. This is the simplest form of sequential chains, where each step has a singular input/output, and the output of one step is the input to the next.\n",
"The next step after calling a language model is to make a series of calls to a language model. We can do this using sequential chains, which are chains that execute their links in a predefined order. Specifically, we will use the `SimpleSequentialChain`. This is the simplest type of a sequential chain, where each step has a single input/output, and the output of one step is the input to the next.\n",
"\n",
"In this tutorial, our sequential chain will:\n",
"1. First, create a company name for a product. We will reuse the `LLMChain` we'd previously initialized to create this company name.\n",
@ -156,7 +156,7 @@
"source": [
"## Create a custom chain with the `Chain` class\n",
"\n",
"LangChain provides many chains out of the box, but sometimes you may want to create a custom chains for your specific use case. For this example, we will create a custom chain that concatenates the outputs of 2 `LLMChain`s.\n",
"LangChain provides many chains out of the box, but sometimes you may want to create a custom chain for your specific use case. For this example, we will create a custom chain that concatenates the outputs of 2 `LLMChain`s.\n",
@ -6,15 +6,19 @@ Primitives can be either `prompts <../prompts.html>`_, `llms <../llms.html>`_, `
The examples here are all end-to-end chains for specific applications.
They are broken up into three categories:
1. `Generic Chains <generic_how_to.html>`_: Generic chains, that are meant to help build other chains rather than serve a particular purpose.
2. `CombineDocuments Chains <combine_docs_how_to.html>`_: Chains aimed at making it easy to work with documents (question answering, summarization, etc).
3. `Utility Chains <utility_how_to.html>`_: Chains consisting of an LLMChain interacting with a specific util.
1. `Generic Chains <./generic_how_to.html>`_: Generic chains, that are meant to help build other chains rather than serve a particular purpose.
2. `Utility Chains <./utility_how_to.html>`_: Chains consisting of an LLMChain interacting with a specific util.
@ -6,16 +6,6 @@ They vary greatly in complexity and are combination of generic, highly configura
## Sequential Chain
This is a specific type of chain where multiple other chains are run in sequence, with the outputs being added as inputs
to the next. A subtype of this type of chain is the `SimpleSequentialChain`, where all subchains have only one input and one output,
and the output of one is therefor used as sole input to the next chain.
## CombineDocuments Chains
These are a subset of chains designed to work with documents. There are two pieces to consider:
1. The underlying chain method (eg, how the documents are combined)
2. Use cases for these types of chains.
For the first, please see [this documentation](combine_docs.md) for more detailed information on the types of chains LangChain supports.
For the second, please see the Use Cases section for more information on [question answering](/use_cases/question_answering.md),
[question answering with sources](/use_cases/qa_with_sources.md), and [summarization](/use_cases/summarization.md).
to the next. A subtype of this type of chain is the [`SimpleSequentialChain`](./generic/sequential_chains.html#simplesequentialchain), where all subchains have only one input and one output,
and the output of one is therefore used as sole input to the next chain.
@ -9,44 +9,50 @@ The examples here are all end-to-end chains for specific applications, focused o
- **Links Used**: Python REPL, LLMChain
- **Notes**: This chain takes user input (a math question), uses an LLMChain to convert it to python code snippet to run in the Python REPL, and then returns that as the result.
- `Example Notebook <examples/llm_math.html>`_
- `Example Notebook <./examples/llm_math.html>`_
**PAL**
- **Links Used**: Python REPL, LLMChain
- **Notes**: This chain takes user input (a reasoning question), uses an LLMChain to convert it to python code snippet to run in the Python REPL, and then returns that as the result.
- `Paper <https://arxiv.org/abs/2211.10435>`_
- `Example Notebook <examples/pal.html>`_
- `Example Notebook <./examples/pal.html>`_
**SQLDatabase Chain**
- **Links Used**: SQLDatabase, LLMChain
- **Notes**: This chain takes user input (a question), uses a first LLM chain to construct a SQL query to run against the SQL database, and then uses another LLMChain to take the results of that query and use it to answer the original question.
- `Example Notebook <examples/sqlite.html>`_
- `Example Notebook <./examples/sqlite.html>`_
**API Chain**
- **Links Used**: LLMChain, Requests
- **Notes**: This chain first uses a LLM to construct the url to hit, then makes that request with the Requests wrapper, and finally runs that result through the language model again in order to product a natural language response.
- `Example Notebook <./examples/api.html>`_
**LLMBash Chain**
- **Links Used**: BashProcess, LLMChain
- **Notes**: This chain takes user input (a question), uses an LLM chain to convert it to a bash command to run in the terminal, and then returns that as the result.
- `Example Notebook <examples/llm_bash.html>`_
- `Example Notebook <./examples/llm_bash.html>`_
**LLMChecker Chain**
- **Links Used**: LLMChain
- **Notes**: This chain takes user input (a question), uses an LLM chain to answer that question, and then uses other LLMChains to self-check that answer.
- **Notes**: This chain takes a URL and other inputs, uses Requests to get the data at that URL, and then passes that along with the other inputs into an LLMChain to generate a response. The example included shows how to ask a question to Google - it firsts constructs a Google url, then fetches the data there, then passes that data + the original question into an LLMChain to get an answer.
Combining language models with your own text data is a powerful way to differentiate them.
The first step in doing this is to load the data into "documents" - a fancy way of say some pieces of text.
This module is aimed at making this easy.
A primary driver of a lot of this is the `Unstructured <https://github.com/Unstructured-IO/unstructured>`_ python package.
This package is a great way to transform all types of files - text, powerpoint, images, html, pdf, etc - into text data.
For detailed instructions on how to get set up with Unstructured, see installation guidelines `here <https://github.com/Unstructured-IO/unstructured#coffee-getting-started>`_.
The following sections of documentation are provided:
- `Key Concepts <./document_loaders/key_concepts.html>`_: A conceptual guide going over the various concepts related to loading documents.
- `How-To Guides <./document_loaders/how_to_guides.html>`_: A collection of how-to guides. These highlight different types of loaders.
"This is an example of how to load a file in [CoNLL-U](https://universaldependencies.org/format.html) format. The whole file is treated as one document. The example data (`conllu.conllu`) is based on one of the standard UD/CoNLL-U examples."
"This covers how to load any source from Airbyte into a local JSON file that can be read in as a document\n",
"\n",
"Prereqs:\n",
"Have docker desktop installed\n",
"\n",
"Steps:\n",
"\n",
"1) Clone Airbyte from GitHub - `git clone https://github.com/airbytehq/airbyte.git`\n",
"\n",
"2) Switch into Airbyte directory - `cd airbyte`\n",
"\n",
"3) Start Airbyte - `docker compose up`\n",
"\n",
"4) In your browser, just visithttp://localhost:8000. You will be asked for a username and password. By default, that's username`airbyte`and password`password`.\n",
"\n",
"5) Setup any source you wish.\n",
"\n",
"6) Set destination as Local JSON, with specified destination path - lets say `/json_data`. Set up manual sync.\n",
"\n",
"7) Run the connection!\n",
"\n",
"7) To see what files are create, you can navigate to: `file:///tmp/airbyte_local`\n",
"\n",
"8) Find your data and copy path. That path should be saved in the file variable below. It should start with `/tmp/airbyte_local`\n"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}