The gitbook importer had some issues while trying to ingest a particular
site, these commits allowed it to work as expected. The last commit
(06017ff) is to open the door to extending this class for other
documentation formats (which will come in a future PR).
Right now, eval chains require an answer for every question. It's
cumbersome to collect this ground truth so getting around this issue
with 2 things:
* Adding a context param in `ContextQAEvalChain` and simply evaluating
if the question is answered accurately from context
* Adding chain of though explanation prompting to improve the accuracy
of this w/o GT.
This also gets to feature parity with openai/evals which has the same
contextual eval w/o GT.
TODO in follow-up:
* Better prompt inheritance. No need for seperate prompt for CoT
reasoning. How can we merge them together
---------
Co-authored-by: Vashisht Madhavan <vashishtmadhavan@Vashs-MacBook-Pro.local>
#991 has already implemented this convenient feature to prevent
exceeding max token limit in embedding model.
> By default, this function is deactivated so as not to change the
previous behavior. If you specify something like 8191 here, it will work
as desired.
According to the author, this is not set by default.
Until now, the default model in OpenAIEmbeddings's max token size is
8191 tokens, no other openai model has a larger token limit.
So I believe it will be better to set this as default value, other wise
users may encounter this error and hard to solve it.
Add support for defining the organization of OpenAI, similarly to what
is done in the reference code below:
```
import os
import openai
openai.organization = os.getenv("OPENAI_ORGANIZATION")
openai.api_key = os.getenv("OPENAI_API_KEY")
```
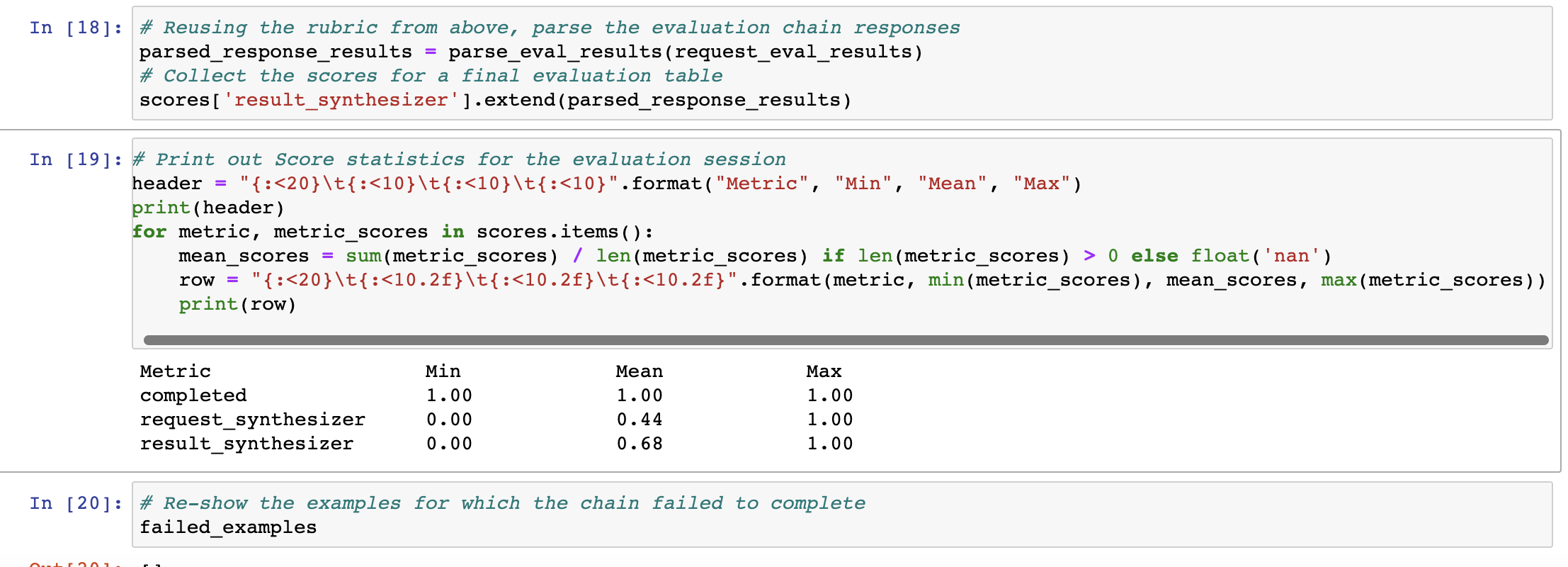
Evaluation so far has shown that agents do a reasonable job of emitting
`json` blocks as arguments when cued (instead of typescript), and `json`
permits the `strict=False` flag to permit control characters, which are
likely to appear in the response in particular.
This PR makes this change to the request and response synthesizer
chains, and fixes the temperature to the OpenAI agent in the eval
notebook. It also adds a `raise_error = False` flag in the notebook to
facilitate debugging
This still doesn't handle the following
- non-JSON media types
- anyOf, allOf, oneOf's
And doesn't emit the typescript definitions for referred types yet, but
that can be saved for a separate PR.
Also, we could have better support for Swagger 2.0 specs and OpenAPI
3.0.3 (can use the same lib for the latter) recommend offline conversion
for now.
`AgentExecutor` already has support for limiting the number of
iterations. But the amount of time taken for each iteration can vary
quite a bit, so it is difficult to place limits on the execution time.
This PR adds a new field `max_execution_time` to the `AgentExecutor`
model. When called asynchronously, the agent loop is wrapped in an
`asyncio.timeout()` context which triggers the early stopping response
if the time limit is reached. When called synchronously, the agent loop
checks for both the max_iteration limit and the time limit after each
iteration.
When used asynchronously `max_execution_time` gives really tight control
over the max time for an execution chain. When used synchronously, the
chain can unfortunately exceed max_execution_time, but it still gives
more control than trying to estimate the number of max_iterations needed
to cap the execution time.
---------
Co-authored-by: Zachary Jones <zjones@zetaglobal.com>
### Features include
- Metadata based embedding search
- Choice of distance metric function (`L2` for Euclidean, `L1` for
Nuclear, `max` L-infinity distance, `cos` for cosine similarity, 'dot'
for dot product. Defaults to `L2`
- Returning scores
- Max Marginal Relevance Search
- Deleting samples from the dataset
### Notes
- Added numerous tests, let me know if you would like to shorten them or
make smarter
---------
Co-authored-by: Davit Buniatyan <d@activeloop.ai>
### Summary
#1667 updated several Unstructured loaders to accept
`unstructured_kwargs` in the `__init__` function. However, the previous
PR did not add this functionality to every Unstructured loader. This PR
ensures `unstructured_kwargs` are passed in all remaining Unstructured
loaders.
### Summary
Adds support for MSFT Outlook emails saved in `.msg` format to
`UnstructuredEmailLoader`. Works if the user has `unstructured>=0.5.8`
installed.
### Testing
The following tests use the example files under `example-docs` in the
Unstructured repo.
```python
from langchain.document_loaders import UnstructuredEmailLoader
loader = UnstructuredEmailLoader("fake-email.eml")
loader.load()
loader = UnstructuredEmailLoader("fake-email.msg")
loader.load()
```
It's useful to evaluate API Chains against a mock server. This PR makes
an example "robot" server that exposes endpoints for the following:
- Path, Query, and Request Body argument passing
- GET, PUT, and DELETE endpoints exposed OpenAPI spec.
Relies on FastAPI + Uvicorn - I could add to the dev dependencies list
if you'd like
It's helpful for developers to run the linter locally on just the
changed files.
This PR adds support for a `lint_diff` command.
Ruff is still run over the entire directory since it's very fast.
- Create a new docker-compose file to start an Elasticsearch instance
for integration tests.
- Add new tests to `test_elasticsearch.py` to verify Elasticsearch
functionality.
- Include an optional group `test_integration` in the `pyproject.toml`
file. This group should contain dependencies for integration tests and
can be installed using the command `poetry install --with
test_integration`. Any new dependencies should be added by running
`poetry add some_new_deps --group "test_integration" `
Note:
New tests running in live mode, which involve end-to-end testing of the
OpenAI API. In the future, adding `pytest-vcr` to record and replay all
API requests would be a nice feature for testing process.More info:
https://pytest-vcr.readthedocs.io/en/latest/
Fixes https://github.com/hwchase17/langchain/issues/2386
In the case no pinecone index is specified, or a wrong one is, do not
create a new one. Creating new indexes can cause unexpected costs to
users, and some code paths could cause a new one to be created on each
invocation.
This PR solves #2413.
Add `n_batch` and `last_n_tokens_size` parameters to the LlamaCpp class.
These parameters (epecially `n_batch`) significantly effect performance.
There's also a `verbose` flag that prints system timings on the `Llama`
class but I wasn't sure where to add this as it conflicts with (should
be pulled from?) the LLM base class.
The specs used in chat-gpt plugins have only a few endpoints and have
unrealistically small specifications. By contrast, a spec like spotify's
has 60+ endpoints and is comprised 100k+ tokens.
Here are some impressive traces from gpt-4 that string together
non-trivial sequences of API calls. As noted in `planner.py`, gpt-3 is
not as robust but can be improved with i) better retry, self-reflect,
etc. logic and ii) better few-shots iii) etc. This PR's just a first
attempt probing a few different directions that eventually can be made
more core.
`make me a playlist with songs from kind of blue. call it machine
blues.`
```
> Entering new AgentExecutor chain...
Action: api_planner
Action Input: I need to find the right API calls to create a playlist with songs from Kind of Blue and name it Machine Blues
Observation: 1. GET /search to find the album ID for "Kind of Blue".
2. GET /albums/{id}/tracks to get the tracks from the "Kind of Blue" album.
3. GET /me to get the current user's ID.
4. POST /users/{user_id}/playlists to create a new playlist named "Machine Blues" for the current user.
5. POST /playlists/{playlist_id}/tracks to add the tracks from "Kind of Blue" to the newly created "Machine Blues" playlist.
Thought:I have a plan to create the playlist. Now, I will execute the API calls.
Action: api_controller
Action Input: 1. GET /search to find the album ID for "Kind of Blue".
2. GET /albums/{id}/tracks to get the tracks from the "Kind of Blue" album.
3. GET /me to get the current user's ID.
4. POST /users/{user_id}/playlists to create a new playlist named "Machine Blues" for the current user.
5. POST /playlists/{playlist_id}/tracks to add the tracks from "Kind of Blue" to the newly created "Machine Blues" playlist.
> Entering new AgentExecutor chain...
Action: requests_get
Action Input: {"url": "https://api.spotify.com/v1/search?q=Kind%20of%20Blue&type=album", "output_instructions": "Extract the id of the first album in the search results"}
Observation: 1weenld61qoidwYuZ1GESA
Thought:Action: requests_get
Action Input: {"url": "https://api.spotify.com/v1/albums/1weenld61qoidwYuZ1GESA/tracks", "output_instructions": "Extract the ids of all the tracks in the album"}
Observation: ["7q3kkfAVpmcZ8g6JUThi3o"]
Thought:Action: requests_get
Action Input: {"url": "https://api.spotify.com/v1/me", "output_instructions": "Extract the id of the current user"}
Observation: 22rhrz4m4kvpxlsb5hezokzwi
Thought:Action: requests_post
Action Input: {"url": "https://api.spotify.com/v1/users/22rhrz4m4kvpxlsb5hezokzwi/playlists", "data": {"name": "Machine Blues"}, "output_instructions": "Extract the id of the newly created playlist"}
Observation: 48YP9TMcEtFu9aGN8n10lg
Thought:Action: requests_post
Action Input: {"url": "https://api.spotify.com/v1/playlists/48YP9TMcEtFu9aGN8n10lg/tracks", "data": {"uris": ["spotify:track:7q3kkfAVpmcZ8g6JUThi3o"]}, "output_instructions": "Confirm that the tracks were added to the playlist"}
Observation: The tracks were added to the playlist. The snapshot_id is "Miw4NTdmMWUxOGU5YWMxMzVmYmE3ZWE5MWZlYWNkMTc2NGVmNTI1ZjY5".
Thought:I am finished executing the plan.
Final Answer: The tracks from the "Kind of Blue" album have been added to the newly created "Machine Blues" playlist. The playlist ID is 48YP9TMcEtFu9aGN8n10lg.
> Finished chain.
Observation: The tracks from the "Kind of Blue" album have been added to the newly created "Machine Blues" playlist. The playlist ID is 48YP9TMcEtFu9aGN8n10lg.
Thought:I am finished executing the plan and have created the playlist with songs from Kind of Blue, named Machine Blues.
Final Answer: I have created a playlist called "Machine Blues" with songs from the "Kind of Blue" album. The playlist ID is 48YP9TMcEtFu9aGN8n10lg.
> Finished chain.
```
or
`give me a song in the style of tobe nwige`
```
> Entering new AgentExecutor chain...
Action: api_planner
Action Input: I need to find the right API calls to get a song in the style of Tobe Nwigwe
Observation: 1. GET /search to find the artist ID for Tobe Nwigwe.
2. GET /artists/{id}/related-artists to find similar artists to Tobe Nwigwe.
3. Pick one of the related artists and use their artist ID in the next step.
4. GET /artists/{id}/top-tracks to get the top tracks of the chosen related artist.
Thought:
I'm ready to execute the API calls.
Action: api_controller
Action Input: 1. GET /search to find the artist ID for Tobe Nwigwe.
2. GET /artists/{id}/related-artists to find similar artists to Tobe Nwigwe.
3. Pick one of the related artists and use their artist ID in the next step.
4. GET /artists/{id}/top-tracks to get the top tracks of the chosen related artist.
> Entering new AgentExecutor chain...
Action: requests_get
Action Input: {"url": "https://api.spotify.com/v1/search?q=Tobe%20Nwigwe&type=artist", "output_instructions": "Extract the artist id for Tobe Nwigwe"}
Observation: 3Qh89pgJeZq6d8uM1bTot3
Thought:Action: requests_get
Action Input: {"url": "https://api.spotify.com/v1/artists/3Qh89pgJeZq6d8uM1bTot3/related-artists", "output_instructions": "Extract the ids and names of the related artists"}
Observation: [
{
"id": "75WcpJKWXBV3o3cfluWapK",
"name": "Lute"
},
{
"id": "5REHfa3YDopGOzrxwTsPvH",
"name": "Deante' Hitchcock"
},
{
"id": "6NL31G53xThQXkFs7lDpL5",
"name": "Rapsody"
},
{
"id": "5MbNzCW3qokGyoo9giHA3V",
"name": "EARTHGANG"
},
{
"id": "7Hjbimq43OgxaBRpFXic4x",
"name": "Saba"
},
{
"id": "1ewyVtTZBqFYWIcepopRhp",
"name": "Mick Jenkins"
}
]
Thought:Action: requests_get
Action Input: {"url": "https://api.spotify.com/v1/artists/75WcpJKWXBV3o3cfluWapK/top-tracks?country=US", "output_instructions": "Extract the ids and names of the top tracks"}
Observation: [
{
"id": "6MF4tRr5lU8qok8IKaFOBE",
"name": "Under The Sun (with J. Cole & Lute feat. DaBaby)"
}
]
Thought:I am finished executing the plan.
Final Answer: The top track of the related artist Lute is "Under The Sun (with J. Cole & Lute feat. DaBaby)" with the track ID "6MF4tRr5lU8qok8IKaFOBE".
> Finished chain.
Observation: The top track of the related artist Lute is "Under The Sun (with J. Cole & Lute feat. DaBaby)" with the track ID "6MF4tRr5lU8qok8IKaFOBE".
Thought:I am finished executing the plan and have the information the user asked for.
Final Answer: The song "Under The Sun (with J. Cole & Lute feat. DaBaby)" by Lute is in the style of Tobe Nwigwe.
> Finished chain.
```
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
{kind=link}