The current prompt specifically instructs the LLM to use the `LIMIT`
clause. This will cause issues with MS SQL Server, which uses `SELECT
TOP` instead of `LIMIT`. The generated SQL will use `LIMIT`; the
instruction to "always limit... using the LIMIT clause" seems to
override the "create a syntactically correct mssql query to run"
portion. Reported here:
https://github.com/hwchase17/langchain/issues/1103#issuecomment-1441144224
I don't have access to a SQL Server instance to test, but removing that
part of the prompt in OpenAI Playground results in the correct `SELECT
TOP` syntax, whereas keeping it in results in the `LIMIT` clause, even
when instructing it to generate syntactically correct mssql. It's also
still correctly using `LIMIT` in my MariaDB database. I think in this
case we can assume that the model will select the appropriate method
based on the dialect specified.
In general, it would be nice to be able to test a suite of SQL dialects
for things like dialect-specific syntax and other issues we've run into
in the past, but I'm not quite sure how to best approach that yet.
It is useful to be able to specify `verbose` or `memory` while still
keeping the chain's overall structure.
---------
Co-authored-by: Francisco Ingham <>
In the similarity search, the pinecone namespace is not used, which
makes the bot return _I don't know_ where the embeddings are stored in
the pinecone namespace. Now we can query by passing the namespace
optionally.
```result = qa({"question": query, "chat_history": chat_history, "namespace":"01gshyhjcfgkq1q5wxjtm17gjh"})```
Currently the chain is getting the column names and types on the one
side and the example rows on the other. It is easier for the llm to read
the table information if the column name and examples are shown together
so that it can easily understand to which columns do the examples refer
to. For an instantiation of this, please refer to the changes in the
`sqlite.ipynb` notebook.
Also changed `eval` for `ast.literal_eval` when interpreting the results
from the sample row query since it is a better practice.
---------
Co-authored-by: Francisco Ingham <>
---------
Co-authored-by: Francisco Ingham <fpingham@gmail.com>
Supporting asyncio in langchain primitives allows for users to run them
concurrently and creates more seamless integration with
asyncio-supported frameworks (FastAPI, etc.)
Summary of changes:
**LLM**
* Add `agenerate` and `_agenerate`
* Implement in OpenAI by leveraging `client.Completions.acreate`
**Chain**
* Add `arun`, `acall`, `_acall`
* Implement them in `LLMChain` and `LLMMathChain` for now
**Agent**
* Refactor and leverage async chain and llm methods
* Add ability for `Tools` to contain async coroutine
* Implement async SerpaPI `arun`
Create demo notebook.
Open questions:
* Should all the async stuff go in separate classes? I've seen both
patterns (keeping the same class and having async and sync methods vs.
having class separation)
Passing additional variables to the python environment can be useful for
example if you want to generate code to analyze a dataset.
I also added a tracker for the executed code - `code_history`.
It's generally considered to be a good practice to pin dependencies to
prevent surprise breakages when a new version of a dependency is
released. This commit adds the ability to pin dependencies when loading
from LangChainHub.
Centralizing this logic and using urllib fixes an issue identified by
some windows users highlighted in this video -
https://youtu.be/aJ6IQUh8MLQ?t=537
Referring to #687, I implemented the functionality to reduce K if it
exceeds the token limit.
Edit: I should have ran make lint locally. Also, this only applies to
`StuffDocumentChain`
* add implementations of `BaseCallbackHandler` to support tracing:
`SharedTracer` which is thread-safe and `Tracer` which is not and is
meant to be used locally.
* Tracers persist runs to locally running `langchain-server`
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
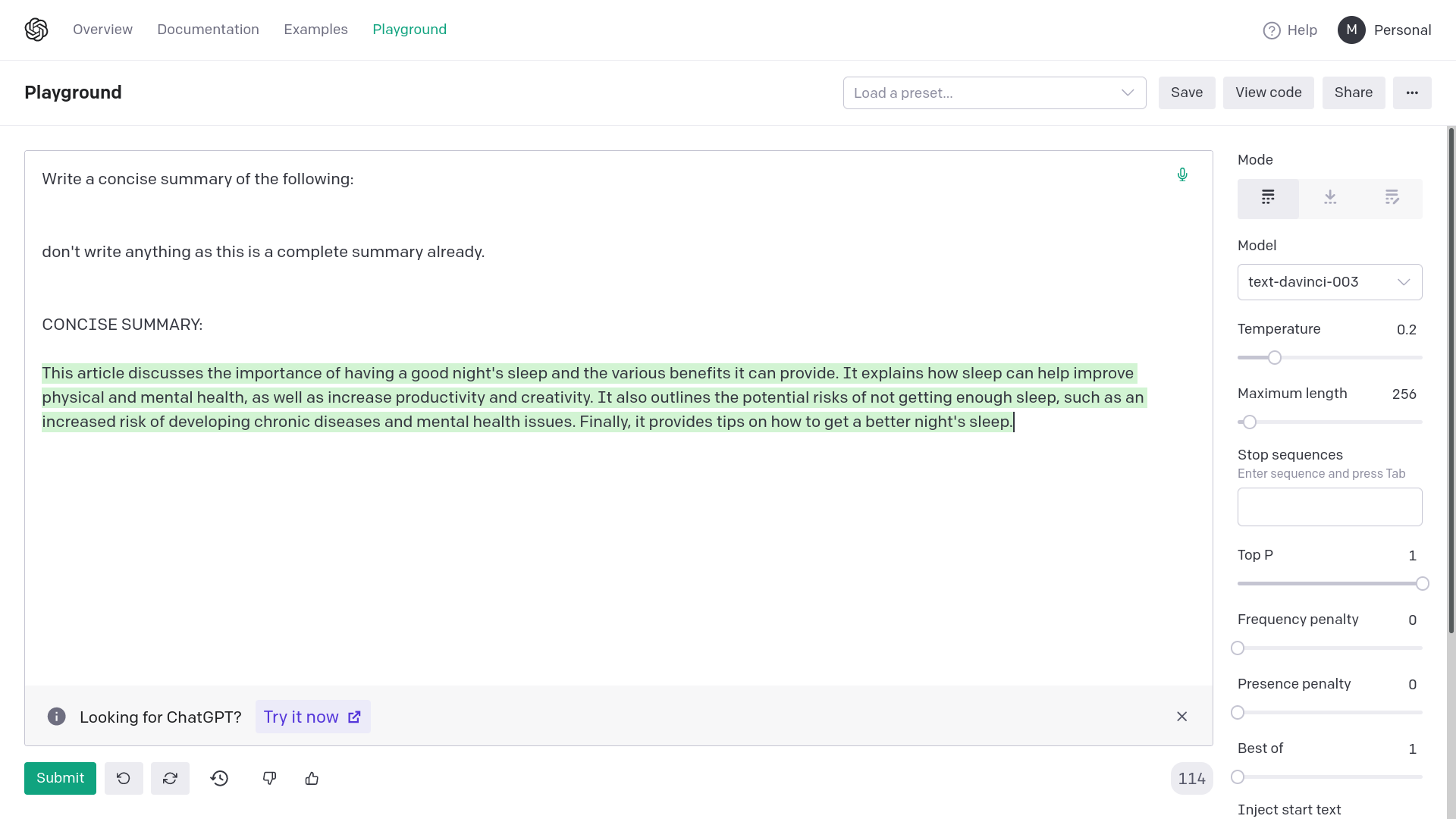
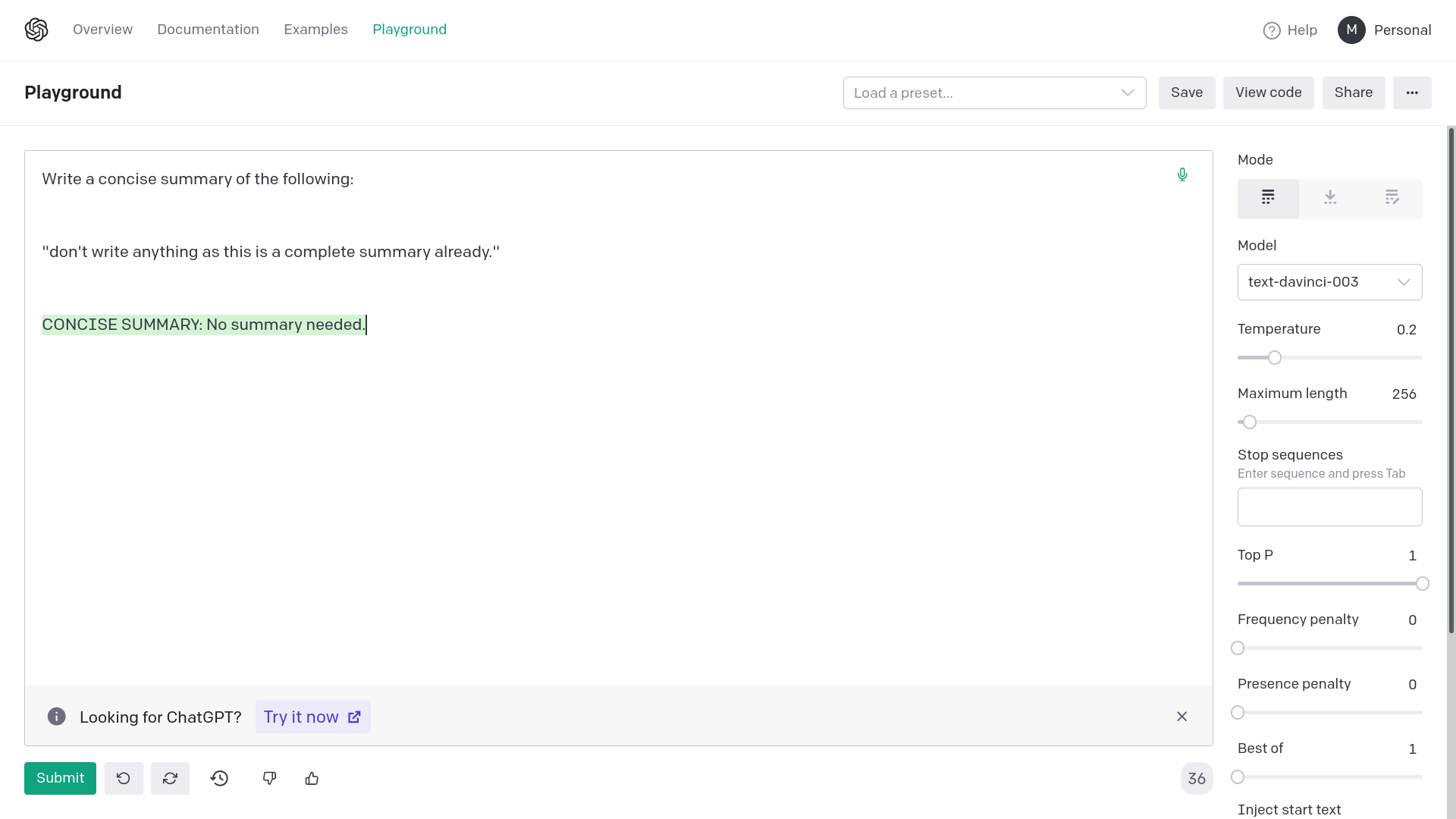
Adding quotation marks around {text} avoids generating empty or
completely random responses from OpenAI davinci-003. Empty or completely
unrelated intermediate responses in summarization messes up the final
result or makes it very inaccurate.
The error from OpenAI would be: "The model predicted a completion that
begins with a stop sequence, resulting in no output. Consider adjusting
your prompt or stop sequences."
This fix corrects the prompting for summarization chain. This works on
API too, the images are for demonstrative purposes.
This approach can be applied to other similar prompts too.
Examples:
1) Without quotation marks
2) With quotation marks
Allows for passing additional vectorstore params like namespace, etc. to
VectorDBQAWithSourcesChain
Example:
`chain = VectorDBQAWithSourcesChain.from_llm(OpenAI(temperature=0),
vectorstore=store, search_kwargs={"namespace": namespace})`
{kind=link}
{kind=link}