7.9 KiB
Bien démarrer
Qu'est-ce qu'un fragment shader ?
Au chapitre précédent, nous avons décrit les shaders comme l'équivalent de l'avènement de la presse par Gutenberg pour l'impression. Pourquoi cette comparaison mais surtout : Qu'est-ce qu'un shader ?
Si vous avez déjà dessiné avec un ordinateur, vous savez qu'il faut dessiner un cercle, puis un rectangle, une ligne, quelques triangles jusqu'à pouvoir composer l'image qu'on veut. Ce processus est très similaire à l'écriture d'une lettre ou d'un livre voire à la peinture, c'est un ensemble d'instructions, exécutées en série, l'une après l'autre.
Les shaders sont également des ensembles d'instructions, mais à la différence des API de dessin classiques, toutes les instructions sont exécutées sur chaque pixel de l'écran. Cela signifie que le code va devoir se comporter différemment selon la position du pixel à l'écran. Comme la presse d'imprimerie, le fragment shader est une fonction à laquelle on passe une position et qui nous renvoie une couleur. Une fois compilé, ce programme peut s'exécuter extrêmement rapidement.

Pourquoi sont-ils si rapides ?
La réponse est le traitement parallèle.
Imaginez le CPU de votre ordinateur comme un tuyau et chacune des tâches que vous lui demandez d'exécuter comme quelque chose qui passe par ce tuyau, comme dans une usine. Certaines tâches seront sans doute plus importantes que d'autres, elles demanderont plus de temps et d'énergie pour être traitées, on dit qu'elles nécessitent plus de ressources ou de puissance de calcul. Du fait de l'architecture des ordinateurs, les tâches sont traitées en série ; chaque tâche doit être terminée avant que le CPU puisse traiter la suivante. Les ordinateurs récents ont généralement plusieurs processeurs qui jouent le rôle de tuyaux, ce qui permet d'enchaîner les tâches en série tout en gardant une certaines fluidité, ces tuyaux s'appellent des threads.
Les jeux vidéos et autres applications graphiques demandent beaucoup plus de puissance de calcul que les autres programmes. Par nature, ils demandent de grandes quantités d'opérations au pixel, chaque changement d'image demandent de recalculer l'ensemble des pixels de l'écran. Dans les applications 3D, on doit également mettre à jour les modèles, les textures, les transformations etc... ce qui rajoute encore du poids à la charge CPU.
Revenons à notre métaphore des tuyaux et des tâches où : "trouver la couleur d'un pixel à l'écran" représente une petite tâche toute simple. En soi, chaque tâche n'est pas bien méchante mais il faut l'appliquer sur chaque pixel de l'écran ! Et c'est là que ça se corse ; il nous faut à présent exécuter cette petite opération un nombre considérable de fois. Par exemple pour exécuter l'ensemble des tâches permettant de dessiner l'ensemble des pixels d'un vieux moniteur ayant une résolution de 800 x 600 pixels, il faut compter 800 x 600 = 480.000 appels à cette petite tâche. Ces 480.000 appels ne valent que pour dessiner une seule frame, si on veut animer notre écran à 30 images/seconde pendant une seconde, il nous en coûtera 11.520.000 appels et si on veut du 60fps, on passe à 28.800.000 tâches à traiter.
Peut-être que le problème est plus facile à identifier lorsqu'on commence à parler de dizaines de millions d'opérations/seconde, si on prend une configuration moderne, 2880/1800 pixels devant tourner à 60 fps, on atteint 311.040.000 calculs / seconde. Des centaines de millions d'opérations par seconde, ce sont des quantités propres à freezer voire à détruire un microprocesseur. Alors comment fait-on ?

C'est là qu'intervient le traitement parallèle (parallel processing). Au lieu d'avoir quelques gros tuyaux (microprocesseurs), on préfère avoir de nombreux petits microprocesseurs qui tournent en parallèle et simultanément, c'est l'essence du GPU: Graphics Processing Unit.
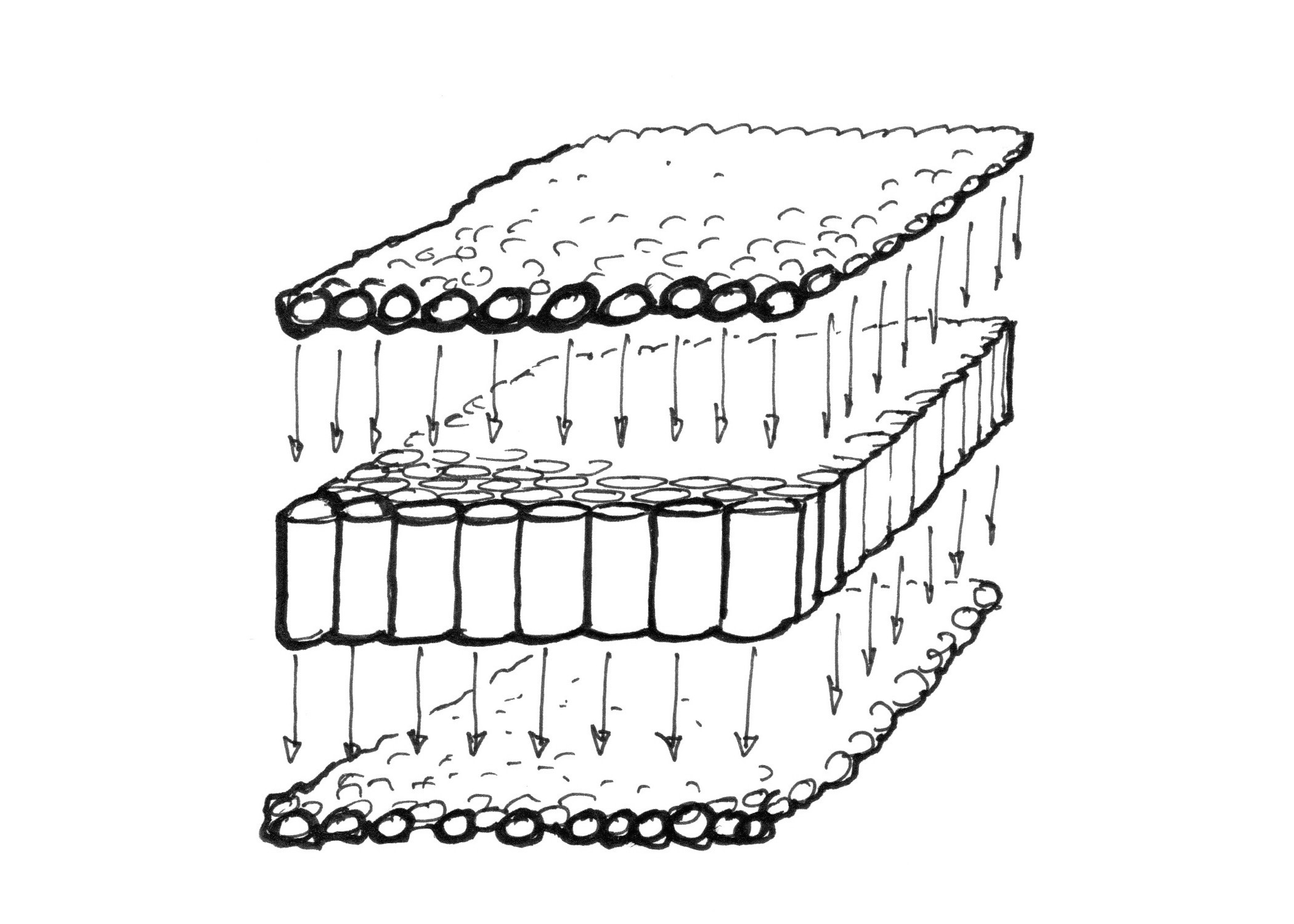
Imaginez ces petits microprocesseurs comme une trame de tuyaux, et les données de chaque pixel comme des balles de Ping Pong. 14.400.000 balles de Ping Pong par secondes pourraient boucher à peu près n'importe quel tuyau. Mais une trame de 800 * 600 (480.000) petits tuyaux recevant 30 vagues de 480.000 balles de pingpong par secondes peuvent traiter la charge facilement. Et ça marche pour des résolutions plus élevées ; plus le matériel est capable de traiter d'informations en parallèle, plus il pourra traiter des flux importants.
Un autre pouvoir magique des GPU c'est l'accélération matérielle de certaines fonctions mathématiques. Certaines fonctions souvent un peu complexes seront traitées directement par le matériel au lieu de passer par la couche logicielle. Ce qui signifie que certaines opérations mathématiques un peu complexes comme les transformations de matrices et les opérations trigonométriques seront traitées très vite, en fait, à la vitesse de l'électricité.
Qu'est ce que le GLSL ?
GLSL est l'acronyme de "openGL Shading Language" (où GL signifie Graphics Library), c'est une norme servant à écrire les programmes de shaders que nous aborderons dans les chapitres suivants. Il existe d'autres types de shaders, selon les plateformes et le matériel utilisé, nous nous concentrerons sur l'OpenGL, dont les spécifications sont faites par le Khronos Group.
Comprendre l'histoire d'OpenGL peut être utile pour comprendre certaines conventions un peu bizarres, si cela vous intéresse, vous pouvez vous reporter à openglbook.com/chapter-0-preface-what-is-opengl.html.
Pourquoi les gens tremblent en entendant le mot Shader ?
Comme dit Uncle Ben dans Spiderman: "with great power comes great responsibility", le traitement parallèle ne déroge pas à cette règle et aussi puissante que soit la programmation GPU, elle apporte un cortège de contraintes et de restrictions.
Pour pouvoir travailler avec une trame de threads, il faut que chaque thread soit indépendant des autres. On dit que le thread est aveugle à ce que font les autres threads. Cette restriction implique que toutes les données doivent aller dans le même sens, il est donc impossible de se servir ou simplement de connaître les résultat d'un autre thread. Autoriser la communication entre threads au moment de l'exécution pourrait compromettre l'intégrité des données en cours de traitement.
Il faut également savoir que le GPU s'assure que tous ses microprocesseurs (la trame de threads) sont actifs en permanence ; dès qu'un thread a fini son traitement, le GPU lui ré-assigne une tâche à traiter. Le thread ne garde aucune trace de ce qu'il faisait la fois précédente ; s'il était en train de dessiner un le pixel d'un bouton sur une interface graphique, sa tâche suivante pourra être de rendre un bout du ciel dans un jeu, puis de rendre un bout de texte sur un client mail, etc. Donc un thread est non seulement aveugle mais aussi amnésique !
En plus du niveau d'abstraction élevé requis pour coder une fonction générique qui saura rendre une image entière uniquement à partir de la variation d'une position, les deux contraintes des threads, aveuglement et amnésie rendent la programmation de shaders assez impopulaire auprès des programmeurs débutants.
Mais n'ayez crainte ! Au cours des chapitres suivants, nous abordons les problèmes étape par étape et passerons d'un simple shader à des calculs avancés. Si vous lisez ceci dans un navigateur récent, vous apprécierez de pouvoir manipuler les exemples interactifs et beaucoup de ce qui vient d'être dit s'éclairera de soi même. Sans plus attendre, jetons nous dans le vif du sujet.
Appuyez sur Next >> pour plonger dans le code !