7.8 KiB
Einstieg
Was ist ein Fragment-Shader?
Im vorangegangenen Kapitel haben wir Fragment-Shader als eine Art Gutenbergsche Druckerpresse für Grafiken beschrieben. Nun, wie kommen wir darauf? Und vor allem: Was genau soll das sein, ein „Shader“?
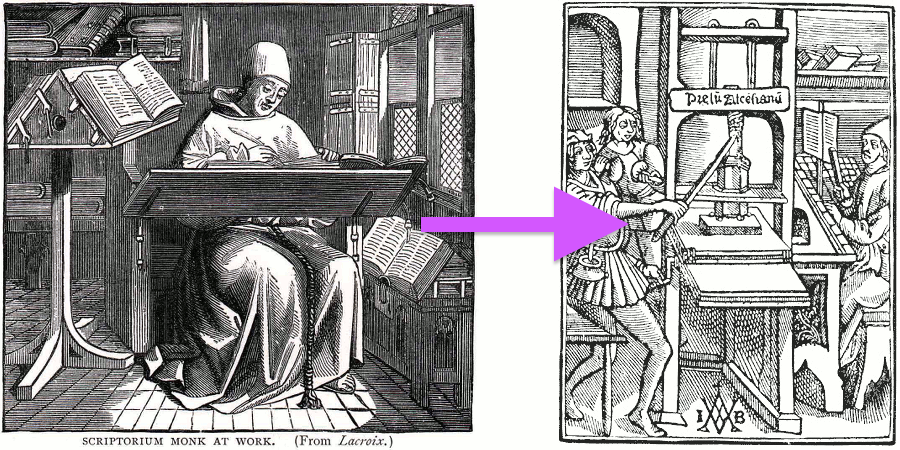
Falls Du schon Erfahrung mit der Erstellung von Computergrafiken gesammelt hast, kennst Du bestimmt die folgende Vorgehensweise: Man malt per Programmbefehl Kreise, Rechtecke, Dreiecke und Linien, damit auf dem Bildschirm nach und nach die gewünschte Grafik entsteht. Dieser Prozess erinnert stark an das Verfassen eines Dokuments per Hand, indem man einzelne Zeichen-Operationen Schritt für Schritt abarbeitet.
Auch Shader verkörpern eine Abfolge von Operationen, doch hier werden diese Operationen gleichzeitig für jeden Bildpunkt (Pixel) auf der Zeichenfläche ausgeführt. Das hat zur Folge, dass der Programmcode des Shaders in Abhängigkeit von der Lage des jeweils bearbeiteten Bildpunktes unterschiedlich agieren muss. Der Shader arbeitet dabei als eine Funktion, die die Koordinaten des jeweiligen Bildpunktes erhält und als Ergebnis die Farbe für diesen Bildpunkt zurückliefert. Ist der Shader einmal kompiliert, läuft dieser Prozess unglaublich schnell und für sehr viele Bildpunkte gleichzeitig ab.

Warum arbeiten Shader schnell?
Diese Frage beantwortet sich, wenn wir uns das Prinzip der parallelen Verarbeitung anschauen.
Stelle Dir den Prozessor in Deinem Computer als eine große Pipeline vor und jede zu bearbeitende Aufgabe als etwas, das durch die Pipeline fließt - wie an einem Fließband innerhalb einer Fabrik. Einige Aufgaben sind größer als andere, weshalb ihre Abarbeitung mehr Zeit und mehr Energie in Anspruch nimmt. Wir sagen dann, diese Aufgaben benötigen mehr „Prozessorleistung“. Der Aufbau des Computers zwingt die verschiedenen Aufgaben dazu, eine nach der anderen durch die Pipeline zu strömen. Die nächste Aufgabe ist an der Reihe, sobald die vorangehende Aufgabe erfolgreich abgearbeitet wurde. Moderne Prozessoren verfügen in der Regel über mehrere Kerne (typischerweise zwei, vier oder acht), von denen jeder wie eine Pipeline arbeitet, so dass mehrere Ströme von Aufgaben (engl. „Threads“) gleichzeitig abgearbeitet werden können.
Videospiele und leistungsstarke Grafikanwendungen benötigen in der Regel wesentlich mehr Prozessorleistung als andere Computerprogramme. Weil sie grafikorientiert arbeiten, müssen diese Programme eine enorme Anzahl an Pixel-Operationen ausführen. Jeder einzelne Bildpunkt muss individuell berechnet werden, und bei 3D-Anwendungen kommen noch perspektivische Verzerrungen sowie das Spiel von Licht und Schatten hinzu.
Kommen wir noch einmal auf das Bild einer Pipeline zurück. Jeder einzelne Bildpunkt verkörpert eine Rechenaufgabe, die durch die Pipeline abgearbeitet werden muss. Einzeln genommen macht das nicht viel Arbeit - der enorme Aufwand entsteht erst durch die schiere Masse an Pixeln auf dem Bildschirm. Schon bei einer Auflösung von 800 x 600 Bildpunkten müssen pro Bild 480.000 Pixels berechnet werden. Für eine flüssige Darstellung mit 30 Bildern pro Sekunde ergeben sich also bereits 14.400.000 Berechnungen pro Sekunde. Das ist eine Dimension, bei der auch moderne Prozessoren an ihre Grenzen stoßen. Und bei einem hochauflösenden Retina-Display mit 2880 x 1800 Bildpunkten und einer Wiederholrate von 60 Bildern pro Sekunde kommen sogar 311.040.000 Berechnungen pro Sekunde zusammen. Fragt sich also, wie ein Computersystem dies bewältigen kann?

Hier kommt die gleichzeitige - parallele - Berechnung möglichst vieler Bildpunkte ins Spiel. An die Stelle weniger großer und immens leistungsfähiger Pipelines (sprich: Mikroprozessoren) treten viele kleine, einfachere Prozessoren, die parallel arbeiten. Sie bilden den Kern einer sogenannten „Graphic Processing Unit“, kurz GPU.
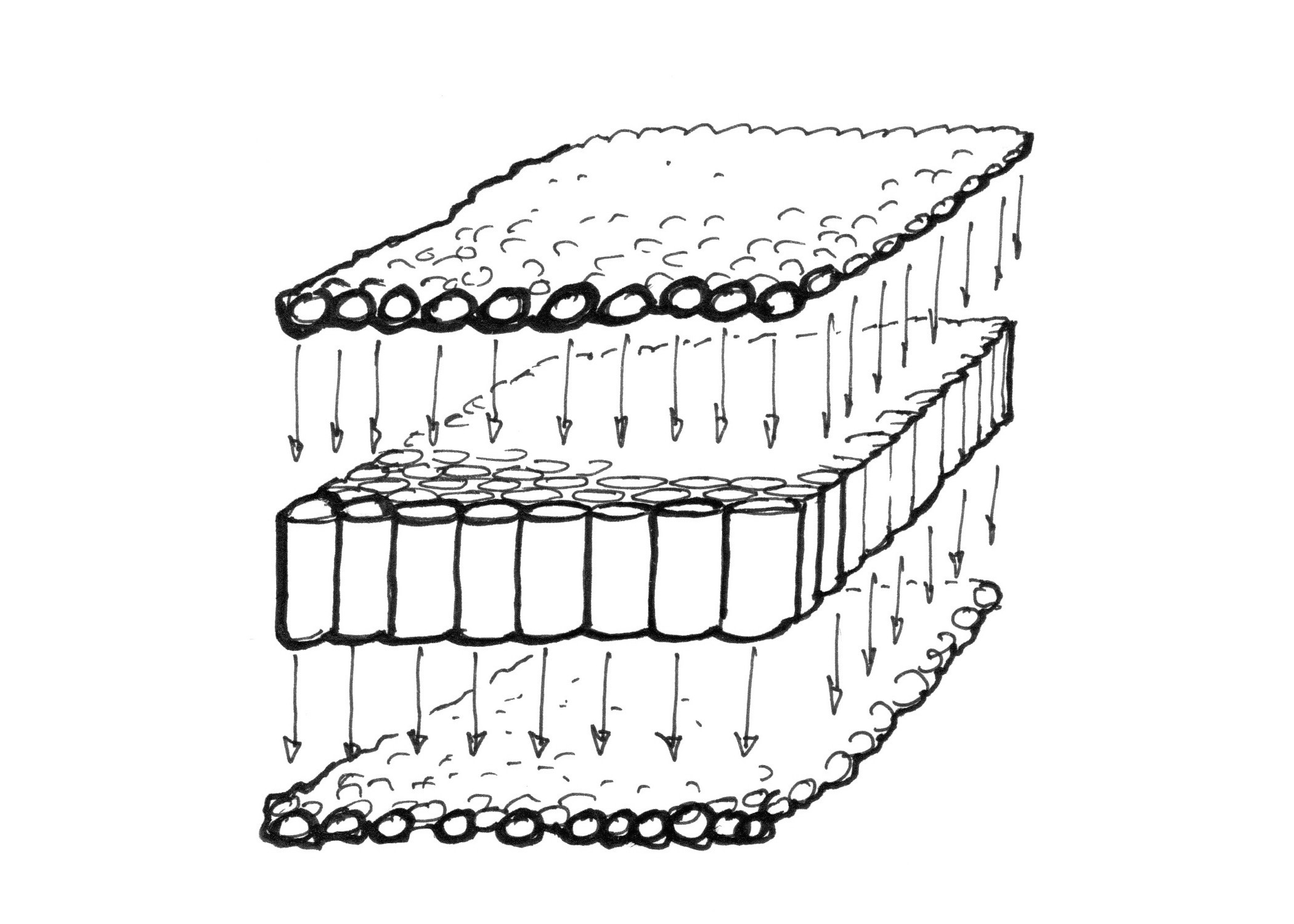
Stelle Dir eine solche GPU wie ein Feld aus lauter Pipelines vor - eine neben der anderen. Jeder Bildpunkt entspricht einem Tischtennisball, der durch eine solche Pipeline hindurchmuss. 14.400.000 Bälle pro Sekunde sind wahrscheinlich zu viel für jede einzelne noch so dicke Pipeline. Hat man aber ein Feld aus 800 x 600 kleinen Pipelines, muss jede nur 30 Bälle pro Sekunde verarbeiten, damit man eine flüssige Darstellung auf dem Bildschirm erhält. Und das ist durchaus machbar. Gleiches gilt für höhere Auflösungen und größere Bildwiederholraten: Je mehr Pipelines parallel arbeiten, desto mehr Bildpunkte können sie pro Zeiteinheit bewältigen.
Die enorme Leistung einer solchen GPU rührt aber auch aus einer anderen Quelle: Viele für die Grafikberechnung unverzichtbare mathematische Operationen lassen sich direkt in der Hardware, in jeder einzelnen Pipeline, parallel ausführen. Es wird also keine zusätzliche Software benötigt, um diese Berechnungen in mehreren Schritten aus einfachen Grundoperationen zusammenzusetzen. Das gilt beispielsweise für die wichtigen trigonometrischen Funktionen und für Matrizenoperationen. Das bringt die Darstellung zusätzlich auf Trab.
Was ist GLSL?
GLSL ist die Abkürzung für „OpenGL Shading Language“, einem weit verbreiteten Standard für Shader-Programme, mit dem sich die folgenden Kapitel beschäftigen. Es gibt auch andere Arten von Shadern, je nach Grafikhardware und Betriebssystem. Wir orientieren uns hier an der wichtigen OpenGL-Spezifikation, die von der Khronos Gruppe erarbeitet wurde. Wenn man die Geschichte von OpenGL kennt, kann man einige der teilweise etwas merkwürdigen Konstrukte und Konventionen besser verstehen. Allen Interessierten empfehle ich deshalb einen Blick auf openglbook.com/chapter-0-preface-what-is-opengl.html.
Warum sind Shader so anspruchsvoll?
Mein reicher Onkel Willi aus Amerika sagte früher immer zu mir: „Denk dran, Junge, unglaublich viel Power bedeutet immer auch unglaublich viel Verantwortung“. Dies gilt in gewisser Weise auch für das Feld des „Parallel Computings“. Die enorme Leistungsfähigkeit moderner GPUs erzeugt ihre eigenen Regeln und Abhängigkeiten. Und die wollen beachtet werden, damit wir nicht über das Ziel hinausschießen.
Damit jede Pipeline innerhalb der GPU parallel an ihrer Aufgabe arbeiten kann, muss sie unabhängig von den anderen Pipelines sein. Sie ist quasi blind dafür, was die anderen gerade tun. Dies bringt u.a. die Einschränkung mit sich, dass alle Daten nur in eine Richtung fließen können. Es ist praktisch unmöglich, auf die Ergebnisse einer anderen Pipeline einzugehen, deren Ergebnis abzurufen und damit eine dritte Pipeline zu füttern.
Außerdem hält die GPU ihre zahlreichen Mikroprozessoren (Pipelines) ständig beschäftigt. Sobald eine Pipeline mit der Berechnung der Farbe für einen Bildpunkt fertig ist, wird sie auch schon mit dem nächsten Bildpunkt „gefüttert“. Aus Sicht des Shader-Programms gibt es quasi kein Vorher und Nachher, sondern immer nur den aktuell zu berechnenden Bildpunkt. Das Shader-Programm in jeder Pipeline ist also nicht nur blind für alle anderen, sondern auch ohne Erinnerung für das Gewesene. Das ist ein Teil der Herausforderung, die die Entwicklung von Shadern bei Programmieranfängern nicht unbedingt beliebt macht.
Aber keine Angst! In den folgenden Kapiteln werden wir uns Schritt für Schritt von einfachen Shadern hin zu komplexen Shadern voran arbeiten. Sofern Du diesen Text mit einem modernen Browser liest, wirst Du ganz einfach mit den zahlreichen interaktiven Beispielprogrammen experimentieren können. Also, lass uns gleich anfangen, indem Du auf die „Next“-Schaltfläche unten auf der Seite klickst.