7.3 KiB
들어가면서
Fragment shader는 무엇인가?
전 챕터에서 컴퓨터그래픽의 쉐이더는 구텐베르크의 인쇄기술과 같다고 했다. 왜 그런가? 아니, 쉐이더란 도데체 무엇이길래?
이미 컴퓨터로 무언가 그리는것에 대한 경험이 조금이라도 있다면, 무언가를 그리기 위해, 어떤 형태의 동그라미, 사각형, 선, 삼각형들과 같은 모양들이 서로 계속 조합해져 최종 원하는 모형이 만들어진다는 것을 이해 할것이다. 이런 프로세스는 어떤 명령어들의 집합이기도 하다고 볼수 있을것이다.
쉐이더 역시 명령어들의 집합이지만, 이 명령어들이 스크린위에 낱개의 픽셀마다 실행되고 이 실행이 모두 한번에 일어난다는 점이 조금 흥미롭다. 이말은 명령어들은 스크린위에 픽셀의 위치마다 연산이 달라진다는 말이다. 이 명령어 셋들 자체가 스크린 픽셀 포지션을 받고, 색을 출력하는 하나의 프로그램이자 함수인셈이다. 그리고 컴파일된 이 프로그램은 굉장히 빠르다.

왜 쉐이더는 빠를까?
대답하기 위해 소개한다. parallel processing.
CPU가 하나의 큰 공장같은 파이프라고 가정하자. 파이프로 들어오는것들은 어떤 작업들이고, 그 작업들이 파이프를 지나면 나오면서 결과가 된다고 하자. 어떤 작업은 크고 복잡하기도 할것이고 어떤건 매우 단순하기도 할것이다. 그리고 컴퓨터는 설계상 절차적으로 작업을 실행하도록 되어 있다; 작업하나가 끝나야 그다음 작업이 시작된다. 근대의 컴퓨터들은 4개의 프로세서로 이루어진 그룹이 이런 파이프처럼 작동하는데, 역시 순차적으로 작업을 하나 끝내고 다음걸 시작하는 방식이다. 각 파이프는 thread라고도 알려져 있다.
비디오 게임이나 그래픽응용어플리케이션들은 일반적으로 보다 많은 프로세싱 파워를 요구한다. 이유는 그래픽 요소들 자체가 수많은 픽셀들의 연산으로 이루어졌기 때무이다. 스크린위에 모든 픽셀들이 각각 계산되고, 3D 게임의 경우, 각 3D 객체들과 모든 퍼스펙티브가 계산되어야 할것이다.
다시 파이프와 작업들의 개념으로 돌아와서, 스크린위에 각 픽셀들은 각각 하나의 작은 작업들을 의미한다. 그리고 이 각각의 작은 작업들은 CPU에게 그다지 버겁지 않은 작업일 것이다. 하지만 (문제 등장) 이렇게 작은 작업들이 스크린위에 픽셀개수만큼 반복되어야 한다는 점이다! 800x600 레졸루션의 게임이라고 하면 480,000개의 픽셀들이 매 프레임 계산되어야 하는데 이말은 14,400,000 번의 계산이 초당 이루어 져야 한다는 말이다! 이것은 꽤나 비효율적일수 있다. (CPU에게) 근대 레티나 디스플레이의 경우, 2880x1800 레졸루션의 픽셀들이 초당 60번 계산되어야 하는데, 계산해보면 초당 311,040,000번이다. 그래픽 엔지니어들은 이 문제를 어떻게 풀까?
바로 이 문제를 풀기위해 등장하는 솔루션이 있다. 바로 parellel processing이다. 강력한 마이크로 프로세서를 몇개 또는 큰 파이프를 쓰는대신, 매우 작은 마이크로 프로세서들을 한번에 돌리는 것이다. 그것이 바로 Graphic Processor Unit. GPU이다.
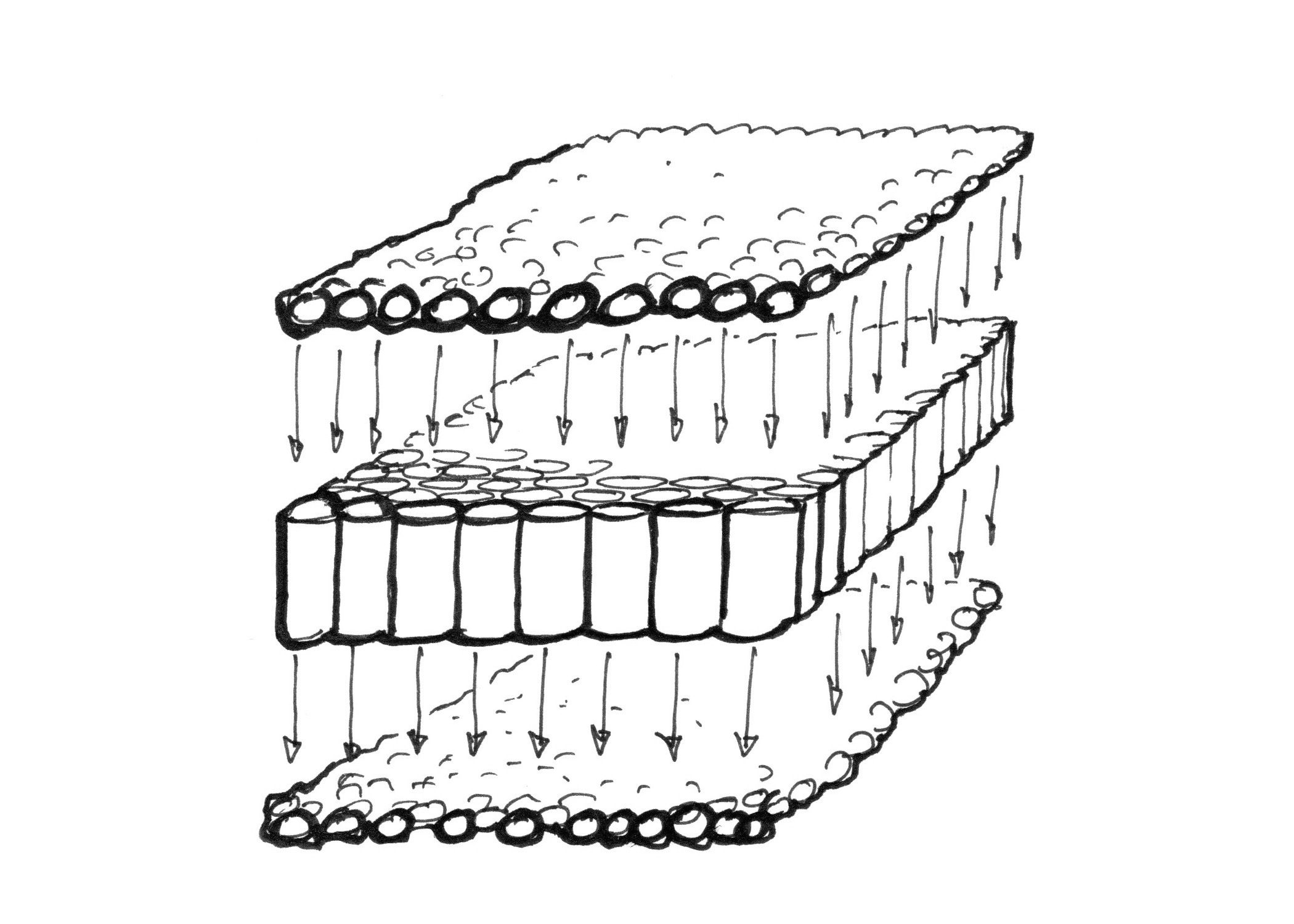
작은 마이크로프로세서들을 여러개의 파이프들로 이루어진 테이블로 생각해보자. 그리고 각 픽셀의 데이터를 핑퐁볼이라고 생각해보자. 14,400,000개의 핑퐁볼이 있다고 한다면, 800x600개의 작은 파이프들로 이루어진 테이블에 480,000개의 핑퐁볼을 30번 떨어뜨리면 아마 최대한 효과적으로 모든 핑퐁볼을 이 테이블 파이프를 통해 통과 시킬수 있을것이다. 하이레졸루션 스크린 렌더링도 이런식으로 진행되는 것이다 - 병렬하드웨어 지원이 높을수록 더 큰 픽셀데이터들을 다룰수 있게 되는것이다.
GPU의 또다른 슈퍼파워중 하나는, 하드웨어지원으로 가속된 수학 함수 연산이다. 즉, 소프트웨어상에서가 아닌, 마이크로칩상에서 바로 연산이 진행된다는 이야기다. 이말은 더 많은 삼각함수연산, 매트릭스연산이 가능하다는 말이다 - 전기가 얼마나 빠르게 흐르냐에 따라.
GLSL은 무엇인가?
GLSL은 openGL Shading Language의 줄임말로, 앞으로의 챕터들에서 쓰게될 쉐이더 프로그램 랭기지이다. 하드웨어나 운영체제에 따라 이 언어는 달라지기도 한다. 이 책에서는 크로노스그룹에서 규정된 openGL 규격을 따른다. Khronos Group. OpenGL의 역사를 이해하는것 또한 앞으로 보게될 전문용어들에 크게 도움이 될것이며, 아래 링크를 추천한다: openglbook.com/chapter-0-preface-what-is-opengl.html
왜 쉐이더를 사람들이 어렵다고 할까?
2차 세계대전에서 쌀공급으로 유명한 미국의 벤삼촌이 이르길, "큰 힘에는 큰 책임이 따른다"고 했다. 병렬연산또한 이 법칙을 따른다; GPU의 강력한 컴퓨테이션 능력은 이것을 쓰기위해 따라야할 제약과 제한이 있다.
파이프상에서 병렬처리를 하기위해서는, 각 쓰레드마다, 서로에 대해 철저히 개별적이여야 한다. 쓰레드는 다른 쓰레드에 대해 "실명" 되어 있다고 미국에서는 표현하는데, 서로의 데이터에 대해 엑세스가 없다는 말이다. 그래서 각각의 프로세스들은 서로 데이터를 주고 받고 처리하는것이 불가능하다. 쓰레드끼리 소통하게 하는것은 데이터를 더럽힐수 있다.
또한, GPU는 모든 병렬 마이크로 프로세서들 (파이프들) 을 항시 바쁘게 하고 있다; 이 파이프들은 해당작업이 끝나는 대로 다른 작업을 받아 수행하도록 설계되어 있다. 또한, 각 쓰레드는 이미 수행한 작업에 대한 어떠한 정보도 가질수 없다. 보통 이런 작업들은 운영체제의 UI요소를 그리고 있는것이거나, 게임의 배경화면을 그리거나, 브라우져의 이메일 텍스트를 그리는 것들이다. 각 쓰레드는 서로에게 실명되있다고 표현할뿐아니라, 기억이없음 이라고도 표현하는데, 이것은 이미 수행한 작업에 대한 어떠한 정보도 가지고 있지 않다는 말이다. 바로 이런 점들이 일반적인 프로그래밍 요소와 크게 다른부분이라고 할수 있어서 프로그래밍을 막 접한 이들에게는 어려운 컨셉일수도 있는것이다.
하지만 걱정하지 마시라! 앞으로의 챕터들에서 우리는 간단한 것부터 복잡한 쉐이딩 연산들에 대해 하나씩 짚고 넘어갈 것이다. 만약 당신이 이 책을 근대 브라우져에서 읽오 있다면, 인터엑티브한 예제들로 인해 공부에 도움을 받을것이다. 더이상 지겨운 서론은 짚어 치우고, *Next >>*를 누르고 코드로 넘어가보자!