| .. | ||
| cube-diffuse.jpg | ||
| cubes-correct.png | ||
| cubes.png | ||
| README.md | ||
{kind=link}
{kind=link}
{kind=link}
Model Loading
Up to this point we've been creating our models manually. While this is an acceptable way to do this, but it's really slow if we want to include complex models with lots of polygons. Because of this, we're going modify our code to leverage the obj model format so that we can create a model in a software such as blender and display it in our code.
Our main.rs file is getting pretty cluttered, let's create a model.rs file that we can put our model loading code into.
// model.rs
pub trait Vertex {
fn desc<'a>() -> wgpu::VertexBufferDescriptor<'a>;
}
#[repr(C)]
#[derive(Copy, Clone, Debug)]
pub struct ModelVertex {
position: [f32; 3],
tex_coords: [f32; 2],
normal: [f32; 3],
}
impl Vertex for ModelVertex {
fn desc<'a>() -> wgpu::VertexBufferDescriptor<'a> {
unimplemented!();
}
}
You'll notice a couple of things here. In main.rs we had Vertex as a struct, here we're using a trait. We could have multiple vertex types (model, UI, instance data, etc.). Making Vertex a trait will allow us to abstract our the VertexBufferDescriptor creation code to make creating RenderPipelines simpler.
Another thing to mention is the normal field in ModelVertex. We won't use this until we talk about lighting, but will add it to the struct for now.
Let's define our VertexBufferDescriptor.
impl Vertex for ModelVertex {
fn desc<'a>() -> wgpu::VertexBufferDescriptor<'a> {
use std::mem;
wgpu::VertexBufferDescriptor {
stride: mem::size_of::<ModelVertex>() as wgpu::BufferAddress,
step_mode: wgpu::InputStepMode::Vertex,
attributes: &[
wgpu::VertexAttributeDescriptor {
offset: 0,
shader_location: 0,
format: wgpu::VertexFormat::Float3,
},
wgpu::VertexAttributeDescriptor {
offset: mem::size_of::<[f32; 3]>() as wgpu::BufferAddress,
shader_location: 1,
format: wgpu::VertexFormat::Float2,
},
wgpu::VertexAttributeDescriptor {
offset: mem::size_of::<[f32; 5]>() as wgpu::BufferAddress,
shader_location: 2,
format: wgpu::VertexFormat::Float3,
},
]
}
}
}
This is basically the same as the original VertexBufferDescriptor, but we added a VertexAttributeDescriptor for the normal. Remove the Vertex struct in main.rs as we won't need it anymore, and use our new Vertex from model for the RenderPipeline.
let render_pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
// ...
vertex_buffers: &[
model::ModelVertex::desc(),
],
// ...
});
With all that in place we need a model to render. If you have one already that's great, but I've supplied a zip file with the model and all of it's textures. We're going to put this model in a new res folder.
Speaking of textures, let's add a load() method to Texture in texture.rs.
use std::path::Path;
impl Texture {
pub fn load<P: AsRef<Path>>(device: &wgpu::Device, path: P) -> Result<(Self, wgpu::CommandBuffer), failure::Error> {
let img = image::open(path)?;
Self::from_image(device, &img)
}
}
The load method will be useful when we load the textures for our models, as include_bytes! requires that we know the name of the file at compile time which we can't really guarantee with model textures.
While we're at it let's import texture.rs in model.rs.
use crate::texture;
Loading models with TOBJ
We're going to use the tobj library to load our model. Before we can load our model though, we need somewhere to put it.
// model.rs
pub struct Model {
pub meshes: Vec<Mesh>,
pub materials: Vec<Material>,
}
You'll notice that our Model struct has a Vec for the meshes, and for materials. This is important as our obj file can include multiple meshes and materials. We still need to create the Mesh and Material classes, so let's do that.
pub struct Material {
pub name: String,
pub diffuse_texture: texture::Texture,
}
pub struct Mesh {
pub name: String,
pub vertex_buffer: wgpu::Buffer,
pub index_buffer: wgpu::Buffer,
pub num_elements: u32,
pub material: usize,
}
The Material is pretty simple, it's just the name and one texture. Our cube obj actually has 2 textures, but one is a normal map, and we'll get to those later. The name is more for debugging purposes.
Mesh holds a vertex buffer, an index buffer, and the number of indices in the mesh. We're using an usize for the material. This usize will be used to index the materials list when it comes time to draw.
With all that out of the way, we can get to loading our model.
impl Model {
pub fn load<P: AsRef<Path>>(device: &wgpu::Device, path: P) -> Result<(Self, Vec<wgpu::CommandBuffer>), failure::Error> {
let (obj_models, obj_materials) = tobj::load_obj(path.as_ref())?;
// We're assuming that the texture files are stored with the obj file
let containing_folder = path.as_ref().parent().unwrap();
// Our `Texure` struct currently returns a `CommandBuffer` when it's created so we need to collect those and return them.
let mut command_buffers = Vec::new();
let mut materials = Vec::new();
for mat in obj_materials {
let diffuse_path = mat.diffuse_texture;
let (diffuse_texture, cmds) = texture::Texture::load(&device, containing_folder.join(diffuse_path))?;
materials.push(Material {
name: mat.name,
diffuse_texture,
});
command_buffers.push(cmds);
}
let mut meshes = Vec::new();
for m in obj_models {
let mut vertices = Vec::new();
for i in 0..m.mesh.positions.len() / 3 {
vertices.push(ModelVertex {
position: [
m.mesh.positions[i * 3],
m.mesh.positions[i * 3 + 1],
m.mesh.positions[i * 3 + 2],
],
tex_coords: [
m.mesh.texcoords[i * 2],
m.mesh.texcoords[i * 2 + 1],
],
normal: [
m.mesh.normals[i * 3],
m.mesh.normals[i * 3 + 1],
m.mesh.normals[i * 3 + 2],
],
});
}
let vertex_buffer = device
.create_buffer_mapped(vertices.len(), wgpu::BufferUsage::VERTEX)
.fill_from_slice(&vertices);
let index_buffer = device
.create_buffer_mapped(m.mesh.indices.len(), wgpu::BufferUsage::INDEX)
.fill_from_slice(&m.mesh.indices);
meshes.push(Mesh {
name: m.name,
vertex_buffer,
index_buffer,
num_elements: m.mesh.indices.len() as u32,
material: m.mesh.material_id.unwrap_or(0),
});
}
Ok((Self { meshes, materials, }, command_buffers))
}
}
Make sure that you change the IndexFormat that the RenderPipeline uses from Uint16 to Uint32. Tobj stores the indices as u32s, so using a lower bit stride will result in your model getting mangled.
let render_pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
// ...
index_format: wgpu::IndexFormat::Uint32,
// ...
});
Rendering a mesh
Before we can draw the model, we need to be able to draw an individual mesh. Let's create a trait called DrawModel, and implement it for RenderPass.
pub trait DrawModel {
fn draw_mesh(&mut self, mesh: &Mesh);
fn draw_mesh_instanced(&mut self, mesh: &Mesh, instances: Range<u32>);
}
impl<'a> DrawModel for wgpu::RenderPass<'a> {
fn draw_mesh(&mut self, mesh: &Mesh) {
self.draw_mesh_instanced(mesh, 0..1);
}
fn draw_mesh_instanced(&mut self, mesh: &Mesh, instances: Range<u32>) {
self.set_vertex_buffers(0, &[(&mesh.vertex_buffer, 0)]);
self.set_index_buffer(&mesh.index_buffer, 0);
self.draw_indexed(0..mesh.num_elements, 0, instances);
}
}
We could have put this methods in impl Model, but I felt it made more sense to have the RenderPass do all the rendering, as that's kind of it's job. This does mean we have to import DrawModel when we go to render though.
// main.rs
render_pass.set_pipeline(&self.render_pipeline);
render_pass.set_bind_group(0, &self.diffuse_bind_group, &[]);
render_pass.set_bind_group(1, &self.uniform_bind_group, &[]);
use model::DrawModel;
render_pass.draw_mesh_instanced(&self.obj_model.meshes[0], 0..self.instances.len() as u32);
Before that though we need to actually load the model and save it to State. Put the following in State::new().
let (obj_model, cmds) = model::Model::load(&device, "code/beginner/tutorial9-models/src/res/cube.obj").unwrap();
queue.submit(&cmds);
The path to the obj will be different for you, so keep that in mind.
Our new model is a bit bigger than our previous one so we're gonna need to adjust the spacing on our instances a bit.
const SPACE_BETWEEN: f32 = 3.0;
let instances = (0..NUM_INSTANCES_PER_ROW).flat_map(|z| {
(0..NUM_INSTANCES_PER_ROW).map(move |x| {
let x = SPACE_BETWEEN * (x as f32 - NUM_INSTANCES_PER_ROW as f32 / 2.0);
let z = SPACE_BETWEEN * (z as f32 - NUM_INSTANCES_PER_ROW as f32 / 2.0);
let position = cgmath::Vector3 { x, y: 0.0, z };
let rotation = if position.is_zero() {
cgmath::Quaternion::from_axis_angle(cgmath::Vector3::unit_z(), cgmath::Deg(0.0))
} else {
cgmath::Quaternion::from_axis_angle(position.clone().normalize(), cgmath::Deg(45.0))
};
Instance {
position, rotation,
}
})
}).collect::<Vec<_>>();
With all that done, you should get something like this.
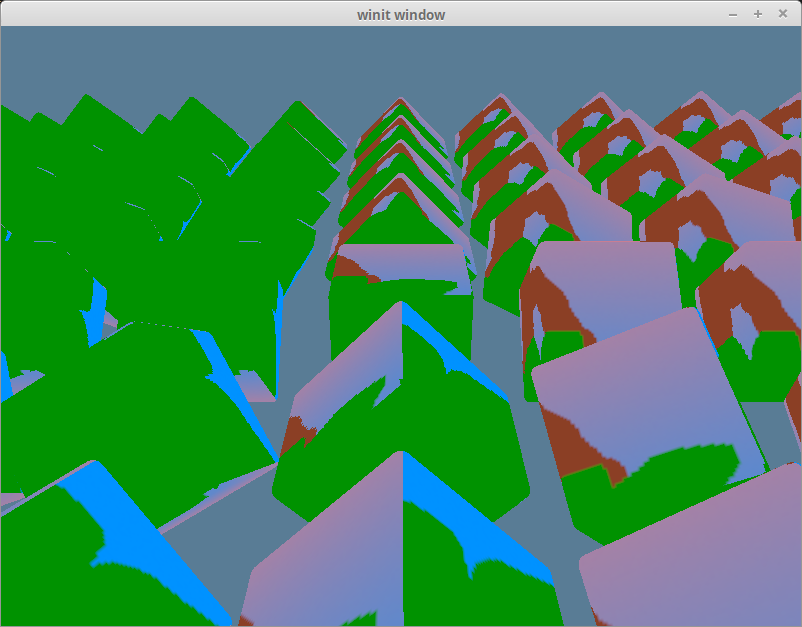
Using the correct textures
If you look at the texture files for our obj, you'll see that they don't match up to our obj. The texture we want to see is this one,

but we're still getting our happy tree texture.
The reason for this is quite simple. Though we've created our textures we haven't created a bind group to give to the RenderPass. We're still using our old diffuse_bind_group. If we want to change that we need to create a bind group for our materials. Add a bind_group field to Material.
pub struct Material {
pub name: String,
pub diffuse_texture: texture::Texture,
pub bind_group: wgpu::BindGroup, // NEW!
}
We're going to add a material parameter to DrawModel.
pub trait DrawModel {
fn draw_mesh(&mut self, mesh: &Mesh, material: &Material, uniforms: &wgpu::BindGroup);
fn draw_mesh_instanced(&mut self, mesh: &Mesh, material: &Material, instances: Range<u32>, uniforms: &wgpu::BindGroup);
}
impl<'a> DrawModel for wgpu::RenderPass<'a> {
fn draw_mesh(&mut self, mesh: &Mesh, material: &Material, uniforms: &wgpu::BindGroup) {
self.draw_mesh_instanced(mesh, material, 0..1, uniforms);
}
fn draw_mesh_instanced(&mut self, mesh: &Mesh, material: &Material, instances: Range<u32>, uniforms: &wgpu::BindGroup) {
self.set_vertex_buffers(0, &[(&mesh.vertex_buffer, 0)]);
self.set_index_buffer(&mesh.index_buffer, 0);
self.set_bind_group(0, &material.bind_group, &[]);
// Do to a bug in 0.4, we need to pass in the uniforms and bind them here.
// This will be fixed in 0.5
self.set_bind_group(1, &uniforms, &[]);
self.draw_indexed(0..mesh.num_elements, 0, instances);
}
}
We need to change the render code to reflect this.
render_pass.set_pipeline(&self.render_pipeline);
let mesh = &self.obj_model.meshes[0];
let material = &self.obj_model.materials[mesh.material];
render_pass.draw_mesh_instanced(mesh, material, 0..self.instances.len() as u32, &self.uniform_bind_group);
With all that in place we should get the following.
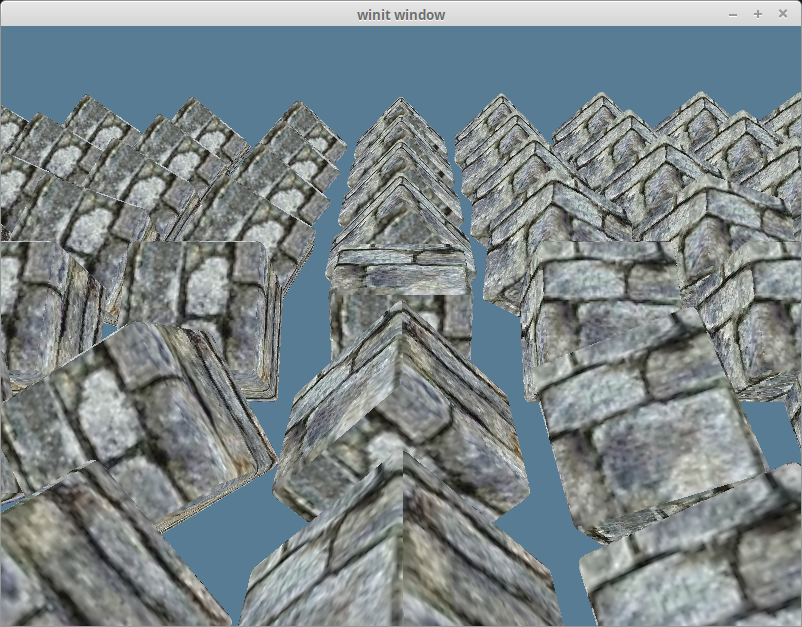
Rendering the entire model
Right now we are specifying the mesh and the material directly. This is useful if we want to draw a mesh with a different material. We're also not rendering other parts of the model (if we had some). Let's create a method for DrawModel that will draw all the parts of the model with their respective materials.
pub trait DrawModel {
// ...
fn draw_model(&mut self, model: &Model, uniforms: &wgpu::BindGroup);
fn draw_model_instanced(&mut self, model: &Model, instances: Range<u32>, uniforms: &wgpu::BindGroup);
}
impl<'a> DrawModel for wgpu::RenderPass<'a> {
// ...
fn draw_model(&mut self, model: &Model, uniforms: &wgpu::BindGroup) {
self.draw_model_instanced(model, 0..1, uniforms);
}
fn draw_model_instanced(&mut self, model: &Model, instances: Range<u32>, uniforms: &wgpu::BindGroup) {
for mesh in &model.meshes {
let material = &model.materials[mesh.material];
self.draw_mesh_instanced(mesh, material, instances.clone(), uniforms);
}
}
}
The code in main.rs will change accordingly.
render_pass.set_pipeline(&self.render_pipeline);
render_pass.draw_model_instanced(&self.obj_model, 0..self.instances.len() as u32, &self.uniform_bind_group);