14 KiB
The Swapchain
First, some house keeping: State
For convenience we're going to pack all the fields into a struct, and create some methods on that.
// main.rs
struct State {
surface: wgpu::Surface,
adapter: wgpu::Adapter,
device: wgpu::Device,
queue: wgpu::Queue,
sc_desc: wgpu::SwapChainDescriptor,
swap_chain: wgpu::SwapChain,
size: winit::dpi::PhysicalSize<u32>,
}
impl State {
async fn new(window: &Window) -> Self {
unimplemented!()
}
fn resize(&mut self, new_size: winit::dpi::PhysicalSize<u32>) {
unimplemented!()
}
// input() won't deal with GPU code, so it can be synchronous
fn input(&mut self, event: &WindowEvent) -> bool {
unimplemented!()
}
fn update(&mut self) {
unimplemented!()
}
fn render(&mut self) {
unimplemented!()
}
}
I'm glossing over States fields, but they'll make more sense as I explain the code behind the methods.
State::new()
The code for this is pretty straight forward, but let's break this down a bit.
impl State {
// ...
async fn new(window: &Window) -> Self {
let size = window.inner_size();
let surface = wgpu::Surface::create(window);
let adapter = wgpu::Adapter::request(
&wgpu::RequestAdapterOptions {
power_preference: wgpu::PowerPreference::Default,
compatible_surface: Some(&surface),
},
wgpu::BackendBit::PRIMARY, // Vulkan + Metal + DX12 + Browser WebGPU
).await.unwrap(); // Get used to seeing this
The surface is used to create the swap_chain. Our window needs to implement raw-window-handle's HasRawWindowHandle trait to access the native window implementation for wgpu to properly create the graphics backend. Fortunately, winit's Window fits the bill. We also need it to request our adapter.
We need the adapter to create the device and queue.
let (device, queue) = adapter.request_device(&wgpu::DeviceDescriptor {
extensions: wgpu::Extensions {
anisotropic_filtering: false,
},
limits: Default::default(),
}).await;
As of writing, the wgpu implementation doesn't allow you to customize much of requesting a device and queue. Eventually the descriptor structs will be filled out more to allow you to find the optimal device and queue. Even so, we still need them, so we'll store them in the struct.
let sc_desc = wgpu::SwapChainDescriptor {
usage: wgpu::TextureUsage::OUTPUT_ATTACHMENT,
format: wgpu::TextureFormat::Bgra8UnormSrgb,
width: size.width,
height: size.height,
present_mode: wgpu::PresentMode::Fifo,
};
let swap_chain = device.create_swap_chain(&surface, &sc_desc);
Here we are defining and creating the swap_chain. The usage field describes how the swap_chain's underlying textures will be used. OUTPUT_ATTACHMENT specifies that the textures will be used to write to the screen (we'll talk about more TextureUsages later).
The format defines how the swap_chains textures will be stored on the gpu. Usually you want to specify the format of the display you're using. As of writing, I was unable to find a way to query what format the display has through wgpu, though there are plans on including such a method, so wgpu::TextureFormat::Bgra8UnormSrgb will do for now. We use wgpu::TextureFormat::Bgra8UnormSrgb because that's the format that's guaranteed to be natively supported by the swapchains of all the APIs/platforms which are currently supported.
width and height, are self explanatory.
The present_mode uses the wgpu::PresentMode enum which is defined as follows.
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq, Eq, Hash)]
#[cfg_attr(feature = "serde", derive(Serialize, Deserialize))]
pub enum PresentMode {
/// The presentation engine does **not** wait for a vertical blanking period and
/// the request is presented immediately. This is a low-latency presentation mode,
/// but visible tearing may be observed. Will fallback to `Fifo` if unavailable on the
/// selected platform and backend. Not optimal for mobile.
Immediate = 0,
/// The presentation engine waits for the next vertical blanking period to update
/// the current image, but frames may be submitted without delay. This is a low-latency
/// presentation mode and visible tearing will **not** be observed. Will fallback to `Fifo`
/// if unavailable on the selected platform and backend. Not optimal for mobile.
Mailbox = 1,
/// The presentation engine waits for the next vertical blanking period to update
/// the current image. The framerate will be capped at the display refresh rate,
/// corresponding to the `VSync`. Tearing cannot be observed. Optimal for mobile.
Fifo = 2,
}
At the end of the method, we simply return the resulting struct.
Self {
surface,
adapter,
device,
queue,
sc_desc,
swap_chain,
size,
}
}
// ...
}
We'll want to call this in our main method before we enter the event loop.
use futures::executor::block_on;
// Since main can't be async, we're going to need to block
let mut state = block_on(State::new(&window));
resize()
If we want to support resizing in our application, we're going to need to recreate the swap_chain everytime the window's size changes. That's the reason we stored the physical size and the sc_desc used to create the swapchain. With all of these, the resize method is very simple.
// impl State
fn resize(&mut self, new_size: winit::dpi::PhysicalSize<u32>) {
self.size = new_size;
self.sc_desc.width = new_size.width;
self.sc_desc.height = new_size.height;
self.swap_chain = self.device.create_swap_chain(&self.surface, &self.sc_desc);
}
There's nothing really different here from creating the swap_chain initially, so I won't get into it.
We call this method in main() in the event loop for the following events.
match event {
// ...
} if window_id == window.id() => if !state.input(event) {
match event {
// ...
WindowEvent::Resized(physical_size) => {
state.resize(*physical_size);
}
WindowEvent::ScaleFactorChanged { new_inner_size, .. } => {
// new_inner_size is &mut so we have to dereference it twice
state.resize(**new_inner_size);
}
// ...
}
input()
input() returns a bool to indicate whether an event has been fully processed. If the method returns true, the main loop won't process the event any further.
We're just going to return false for now because we don't have any events we want to capture.
// impl State
fn input(&mut self, event: &WindowEvent) -> bool {
false
}
We need to do a little more work in the event loop. We want State to have priority over main(). Doing that (and previous changes) should have your loop looking like this.
// main()
event_loop.run(move |event, _, control_flow| {
match event {
Event::WindowEvent {
ref event,
window_id,
} if window_id == window.id() => if !state.input(event) { // <- This line changed after the "=>"
match event {
WindowEvent::CloseRequested => *control_flow = ControlFlow::Exit,
WindowEvent::KeyboardInput {
input,
..
} => {
match input {
KeyboardInput {
state: ElementState::Pressed,
virtual_keycode: Some(VirtualKeyCode::Escape),
..
} => *control_flow = ControlFlow::Exit,
_ => {}
}
}
WindowEvent::Resized(physical_size) => {
state.resize(*physical_size);
}
WindowEvent::ScaleFactorChanged { new_inner_size, .. } => {
// new_inner_size is &mut so w have to dereference it twice
state.resize(**new_inner_size);
}
_ => {}
} // <- remove the comma on this line
} // <- Add a new closing brace for the if expression
_ => {}
}
});
update()
We don't have anything to update yet, so leave the method empty.
fn update(&mut self) {
// remove `unimplemented!()`
}
render()
Here's where the magic happens. First we need to get a frame to render to. This will include a wgpu::Texture and wgpu::TextureView that will hold the actual image we're drawing to (we'll cover this more when we talk about textures).
// impl State
fn render(&mut self) {
let frame = self.swap_chain.get_next_texture()
.expect("Timeout getting texture");
We also need to create a CommandEncoder to create the actual commands to send to the gpu. Most modern graphics frameworks expect commands to be stored in a command buffer before being sent to the gpu. The encoder builds a command buffer that we can then send to the gpu.
let mut encoder = self.device.create_command_encoder(&wgpu::CommandEncoderDescriptor {
label: Some("Render Encoder"),
});
Now we can actually get to clearing the screen (long time coming). We need to use the encoder to create a RenderPass. The RenderPass has all the methods to do the actual drawing. The code for creating a RenderPass is a bit nested, so I'll copy it all here, and talk about the pieces.
{
let _render_pass = encoder.begin_render_pass(&wgpu::RenderPassDescriptor {
color_attachments: &[
wgpu::RenderPassColorAttachmentDescriptor {
attachment: &frame.view,
resolve_target: None,
load_op: wgpu::LoadOp::Clear,
store_op: wgpu::StoreOp::Store,
clear_color: wgpu::Color {
r: 0.1,
g: 0.2,
b: 0.3,
a: 1.0,
},
}
],
depth_stencil_attachment: None,
});
}
self.queue.submit(&[
encoder.finish()
]);
}
First things first, let's talk about the {}. encoder.begin_render_pass(...) borrows encoder mutably (aka &mut self). We can't call encoder.finish() until we release that mutable borrow. The {} around encoder.begin_render_pass(...) tells rust to drop any variables within them when the code leaves that scope thus releasing the mutable borrow on encoder and allowing us to finish() it. If you don't like the {}, you can also use drop(render_pass) to achieve the same effect.
We can get the same results by removing the {}, and the let _render_pass = line, but we need access to the _render_pass in the next tutorial, so we'll leave it as is.
The last lines of the code tell wgpu to finish the command buffer, and to submit it to the gpu's render queue.
We need to update the event loop again to call this method. We'll also call update before it too.
// main()
event_loop.run(move |event, _, control_flow| {
match event {
// ...
Event::RedrawRequested(_) => {
state.update();
state.render();
}
Event::MainEventsCleared => {
// RedrawRequested will only trigger once, unless we manually
// request it.
window.request_redraw();
}
// ...
}
});
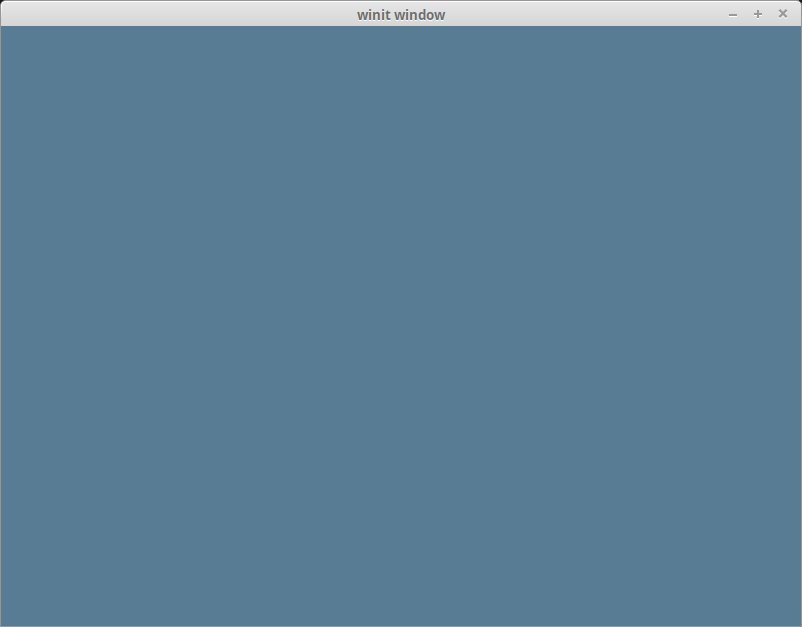
With all that, you should be getting something that looks like this.
Wait, what's going on with RenderPassDescriptor?
Some of you may be able to tell what's going on just by looking at it, but I'd be remiss if I didn't go over it. Let's take a look at the code again.
&wgpu::RenderPassDescriptor {
color_attachments: &[
// ...
],
depth_stencil_attachment: None,
}
A RenderPassDescriptor only has two fields: color_attachments and depth_stencil_attachment. The color_attachements describe where we are going to draw our color to.
We'll use depth_stencil_attachment later, but we'll set it to None for now.
wgpu::RenderPassColorAttachmentDescriptor {
attachment: &frame.view,
resolve_target: None,
load_op: wgpu::LoadOp::Clear,
store_op: wgpu::StoreOp::Store,
clear_color: wgpu::Color {
r: 0.1,
g: 0.2,
b: 0.3,
a: 1.0,
},
}
The RenderPassColorAttachmentDescriptor has the attachment field which informs wgpu what texture to save the colors to. In this case we specify frame.view that we created using swap_chain.get_next_texture(). This means that any colors we draw to this attachment will get drawn to the screen.
There's not much documentation for resolve_target at the moment, but it does expect an Option<&'a TextureView>. Fortunately, we can use None.
load_op and store_op define what operation to perform when gpu looks to load and store the colors for this color attachment for this render pass. We'll get more into this when we cover render passes in depth, but for now we just LoadOp::Clear the texture when the render pass starts, and StoreOp::Store the colors when it ends.
The last field clear_color is just the color to use when LoadOp::Clear and/or StoreOp::Clear are used. This is where the blue color comes from.
Challenge
Modify the input() method to capture mouse events, and update the clear color using that. Hint: you'll probably need to use WindowEvent::CursorMoved