mirror of
https://github.com/hwchase17/langchain
synced 2024-11-08 07:10:35 +00:00
118 lines
3.6 KiB
Markdown
118 lines
3.6 KiB
Markdown
|
|
# rag-gemini-multi-modal
|
|
|
|
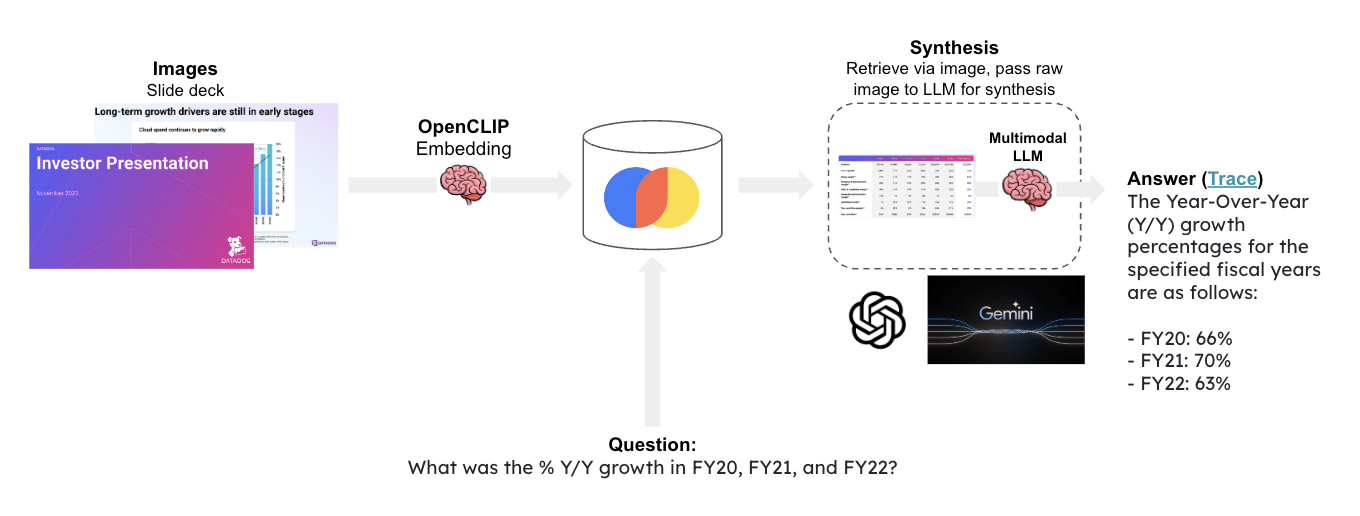
Multi-modal LLMs enable visual assistants that can perform question-answering about images.
|
|
|
|
This template create a visual assistant for slide decks, which often contain visuals such as graphs or figures.
|
|
|
|
It uses OpenCLIP embeddings to embed all of the slide images and stores them in Chroma.
|
|
|
|
Given a question, relevat slides are retrieved and passed to [Google Gemini](https://deepmind.google/technologies/gemini/#introduction) for answer synthesis.
|
|
|
|
|
|
|
|
## Input
|
|
|
|
Supply a slide deck as pdf in the `/docs` directory.
|
|
|
|
By default, this template has a slide deck about Q3 earnings from DataDog, a public techologyy company.
|
|
|
|
Example questions to ask can be:
|
|
```
|
|
How many customers does Datadog have?
|
|
What is Datadog platform % Y/Y growth in FY20, FY21, and FY22?
|
|
```
|
|
|
|
To create an index of the slide deck, run:
|
|
```
|
|
poetry install
|
|
python ingest.py
|
|
```
|
|
|
|
## Storage
|
|
|
|
This template will use [OpenCLIP](https://github.com/mlfoundations/open_clip) multi-modal embeddings to embed the images.
|
|
|
|
You can select different embedding model options (see results [here](https://github.com/mlfoundations/open_clip/blob/main/docs/openclip_results.csv)).
|
|
|
|
The first time you run the app, it will automatically download the multimodal embedding model.
|
|
|
|
By default, LangChain will use an embedding model with moderate performance but lower memory requirments, `ViT-H-14`.
|
|
|
|
You can choose alternative `OpenCLIPEmbeddings` models in `rag_chroma_multi_modal/ingest.py`:
|
|
```
|
|
vectorstore_mmembd = Chroma(
|
|
collection_name="multi-modal-rag",
|
|
persist_directory=str(re_vectorstore_path),
|
|
embedding_function=OpenCLIPEmbeddings(
|
|
model_name="ViT-H-14", checkpoint="laion2b_s32b_b79k"
|
|
),
|
|
)
|
|
```
|
|
|
|
## LLM
|
|
|
|
The app will retrieve images using multi-modal embeddings, and pass them to Google Gemini.
|
|
|
|
## Environment Setup
|
|
|
|
Set your `GOOGLE_API_KEY` environment variable in order to access Gemini.
|
|
|
|
## Usage
|
|
|
|
To use this package, you should first have the LangChain CLI installed:
|
|
|
|
```shell
|
|
pip install -U langchain-cli
|
|
```
|
|
|
|
To create a new LangChain project and install this as the only package, you can do:
|
|
|
|
```shell
|
|
langchain app new my-app --package rag-gemini-multi-modal
|
|
```
|
|
|
|
If you want to add this to an existing project, you can just run:
|
|
|
|
```shell
|
|
langchain app add rag-gemini-multi-modal
|
|
```
|
|
|
|
And add the following code to your `server.py` file:
|
|
```python
|
|
from rag_gemini_multi_modal import chain as rag_gemini_multi_modal_chain
|
|
|
|
add_routes(app, rag_gemini_multi_modal_chain, path="/rag-gemini-multi-modal")
|
|
```
|
|
|
|
(Optional) Let's now configure LangSmith.
|
|
LangSmith will help us trace, monitor and debug LangChain applications.
|
|
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
|
If you don't have access, you can skip this section
|
|
|
|
```shell
|
|
export LANGCHAIN_TRACING_V2=true
|
|
export LANGCHAIN_API_KEY=<your-api-key>
|
|
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
|
```
|
|
|
|
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
|
|
|
```shell
|
|
langchain serve
|
|
```
|
|
|
|
This will start the FastAPI app with a server is running locally at
|
|
[http://localhost:8000](http://localhost:8000)
|
|
|
|
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
|
We can access the playground at [http://127.0.0.1:8000/rag-gemini-multi-modal/playground](http://127.0.0.1:8000/rag-gemini-multi-modal/playground)
|
|
|
|
We can access the template from code with:
|
|
|
|
```python
|
|
from langserve.client import RemoteRunnable
|
|
|
|
runnable = RemoteRunnable("http://localhost:8000/rag-gemini-multi-modal")
|
|
```
|