# Add QnA with sources example
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes: see
https://stackoverflow.com/questions/76207160/langchain-doesnt-work-with-weaviate-vector-database-getting-valueerror/76210017#76210017
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@dev2049
# Bibtex integration
Wrap bibtexparser to retrieve a list of docs from a bibtex file.
* Get the metadata from the bibtex entries
* `page_content` get from the local pdf referenced in the `file` field
of the bibtex entry using `pymupdf`
* If no valid pdf file, `page_content` set to the `abstract` field of
the bibtex entry
* Support Zotero flavour using regex to get the file path
* Added usage example in
`docs/modules/indexes/document_loaders/examples/bibtex.ipynb`
---------
Co-authored-by: Sébastien M. Popoff <sebastien.popoff@espci.fr>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Allow to specify ID when adding to the FAISS vectorstore
This change allows unique IDs to be specified when adding documents /
embeddings to a faiss vectorstore.
- This reflects the current approach with the chroma vectorstore.
- It allows rejection of inserts on duplicate IDs
- will allow deletion / update by searching on deterministic ID (such as
a hash).
- If not specified, a random UUID is generated (as per previous
behaviour, so non-breaking).
This commit fixes#5065 and #3896 and should fix#2699 indirectly. I've
tested adding and merging.
Kindly tagging @Xmaster6y @dev2049 for review.
---------
Co-authored-by: Ati Sharma <ati@agalmic.ltd>
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Change Default GoogleDriveLoader Behavior to not Load Trashed Files
(issue #5104)
Fixes#5104
If the previous behavior of loading files that used to live in the
folder, but are now trashed, you can use the `load_trashed_files`
parameter:
```
loader = GoogleDriveLoader(
folder_id="1yucgL9WGgWZdM1TOuKkeghlPizuzMYb5",
recursive=False,
load_trashed_files=True
)
```
As not loading trashed files should be expected behavior, should we
1. even provide the `load_trashed_files` parameter?
2. add documentation? Feels most users will stick with default behavior
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
DataLoaders
- @eyurtsev
Twitter: [@nicholasliu77](https://twitter.com/nicholasliu77)
I found an API key for `serpapi_api_key` while reading the docs. It
seems to have been modified very recently. Removed it in this PR
@hwchase17 - project lead
Copies `GraphIndexCreator.from_text()` to make an async version called
`GraphIndexCreator.afrom_text()`.
This is (should be) a trivial change: it just adds a copy of
`GraphIndexCreator.from_text()` which is async and awaits a call to
`chain.apredict()` instead of `chain.predict()`. There is no unit test
for GraphIndexCreator, and I did not create one, but this code works for
me locally.
@agola11 @hwchase17
# fix a mistake in concepts.md
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
Example:
```
$ langchain plus start --expose
...
$ langchain plus status
The LangChainPlus server is currently running.
Service Status Published Ports
langchain-backend Up 40 seconds 1984
langchain-db Up 41 seconds 5433
langchain-frontend Up 40 seconds 80
ngrok Up 41 seconds 4040
To connect, set the following environment variables in your LangChain application:
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT=https://5cef-70-23-89-158.ngrok.io
$ langchain plus stop
$ langchain plus status
The LangChainPlus server is not running.
$ langchain plus start
The LangChainPlus server is currently running.
Service Status Published Ports
langchain-backend Up 5 seconds 1984
langchain-db Up 6 seconds 5433
langchain-frontend Up 5 seconds 80
To connect, set the following environment variables in your LangChain application:
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT=http://localhost:1984
```
# Add Joplin document loader
[Joplin](https://joplinapp.org/) is an open source note-taking app.
Joplin has a [REST API](https://joplinapp.org/api/references/rest_api/)
for accessing its local database. The proposed `JoplinLoader` uses the
API to retrieve all notes in the database and their metadata. Joplin
needs to be installed and running locally, and an access token is
required.
- The PR includes an integration test.
- The PR includes an example notebook.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
## Description
The html structure of readthedocs can differ. Currently, the html tag is
hardcoded in the reader, and unable to fit into some cases. This pr
includes the following changes:
1. Replace `find_all` with `find` because we just want one tag.
2. Provide `custom_html_tag` to the loader.
3. Add tests for readthedoc loader
4. Refactor code
## Issues
See more in https://github.com/hwchase17/langchain/pull/2609. The
problem was not completely fixed in that pr.
---------
Signed-off-by: byhsu <byhsu@linkedin.com>
Co-authored-by: byhsu <byhsu@linkedin.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Output parsing variation allowance for self-ask with search
This change makes self-ask with search easier for Llama models to
follow, as they tend toward returning 'Followup:' instead of 'Follow
up:' despite an otherwise valid remaining output.
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
`vectorstore.PGVector`: The transactional boundary should be increased
to cover the query itself
Currently, within the `similarity_search_with_score_by_vector` the
transactional boundary (created via the `Session` call) does not include
the select query being made.
This can result in un-intended consequences when interacting with the
PGVector instance methods directly
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# OpanAI finetuned model giving zero tokens cost
Very simple fix to the previously committed solution to allowing
finetuned Openai models.
Improves #5127
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
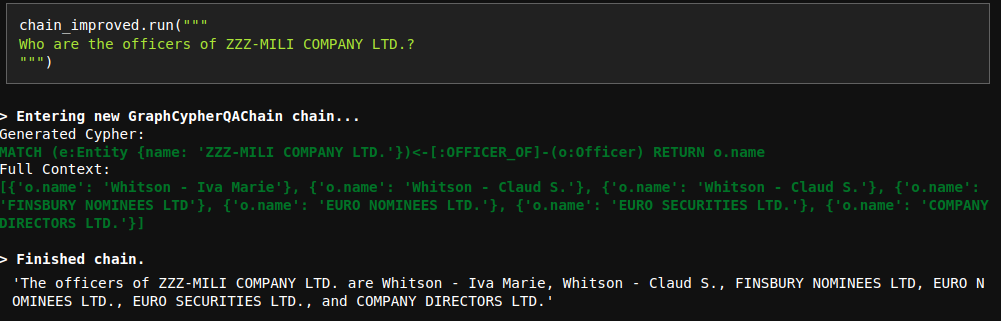
# Improve Cypher QA prompt
The current QA prompt is optimized for networkX answer generation, which
returns all the possible triples.
However, Cypher search is a bit more focused and doesn't necessary
return all the context information.
Due to that reason, the model sometimes refuses to generate an answer
even though the information is provided:
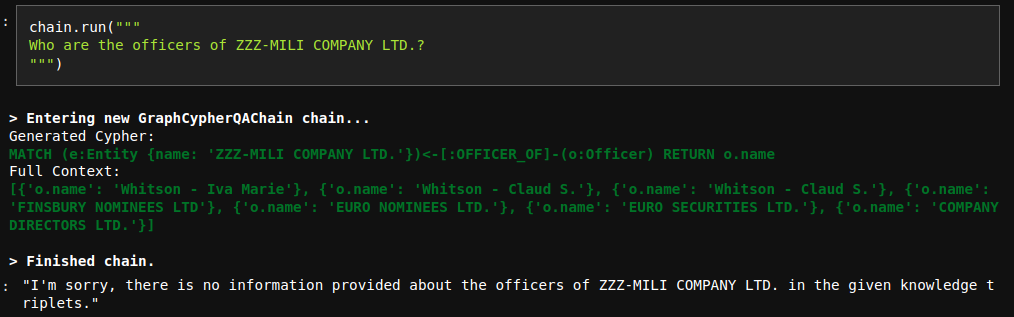
To fix this issue, I have updated the prompt. Interestingly, I tried
many variations with less instructions and they didn't work properly.
However, the current fix works nicely.
# Reuse `length_func` in `MapReduceDocumentsChain`
Pretty straightforward refactor in `MapReduceDocumentsChain`. Reusing
the local variable `length_func`, instead of the longer alternative
`self.combine_document_chain.prompt_length`.
@hwchase17
Follow up of https://github.com/hwchase17/langchain/pull/5015
Thanks for catching this!
Just a small PR to adjust couple of strings to these changes
Signed-off-by: jupyterjazz <saba.sturua@jina.ai>
# Beam
Calls the Beam API wrapper to deploy and make subsequent calls to an
instance of the gpt2 LLM in a cloud deployment. Requires installation of
the Beam library and registration of Beam Client ID and Client Secret.
Additional calls can then be made through the instance of the large
language model in your code or by calling the Beam API.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Vectara Integration
This PR provides integration with Vectara. Implemented here are:
* langchain/vectorstore/vectara.py
* tests/integration_tests/vectorstores/test_vectara.py
* langchain/retrievers/vectara_retriever.py
And two IPYNB notebooks to do more testing:
* docs/modules/chains/index_examples/vectara_text_generation.ipynb
* docs/modules/indexes/vectorstores/examples/vectara.ipynb
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# DOCS added missed document_loader examples
Added missed examples: `JSON`, `Open Document Format (ODT)`,
`Wikipedia`, `tomarkdown`.
Updated them to a consistent format.
## Who can review?
@hwchase17
@dev2049
# Clarification of the reference to the "get_text_legth" function in
getting_started.md
Reference to the function "get_text_legth" in the documentation did not
make sense. Comment added for clarification.
@hwchase17
# Docs: updated getting_started.md
Just accommodating some unnecessary spaces in the example of "pass few
shot examples to a prompt template".
@vowelparrot
# Same as PR #5045, but for async
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes#4825
I had forgotten to update the asynchronous counterpart `aadd_documents`
with the bug fix from PR #5045, so this PR also fixes `aadd_documents`
too.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@dev2049
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# Add async versions of predict() and predict_messages()
#4615 introduced a unifying interface for "base" and "chat" LLM models
via the new `predict()` and `predict_messages()` methods that allow both
types of models to operate on string and message-based inputs,
respectively.
This PR adds async versions of the same (`apredict()` and
`apredict_messages()`) that are identical except for their use of
`agenerate()` in place of `generate()`, which means they repurpose all
existing work on the async backend.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@hwchase17 (follows his work on #4615)
@agola11 (async)
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Check whether 'other' is empty before popping
This PR could fix a potential 'popping empty set' error.
Co-authored-by: Junlin Zhou <jlzhou@zjuici.com>
# Add MosaicML inference endpoints
This PR adds support in langchain for MosaicML inference endpoints. We
both serve a select few open source models, and allow customers to
deploy their own models using our inference service. Docs are here
(https://docs.mosaicml.com/en/latest/inference.html), and sign up form
is here (https://forms.mosaicml.com/demo?utm_source=langchain). I'm not
intimately familiar with the details of langchain, or the contribution
process, so please let me know if there is anything that needs fixing or
this is the wrong way to submit a new integration, thanks!
I'm also not sure what the procedure is for integration tests. I have
tested locally with my api key.
## Who can review?
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
This PR introduces a new module, `elasticsearch_embeddings.py`, which
provides a wrapper around Elasticsearch embedding models. The new
ElasticsearchEmbeddings class allows users to generate embeddings for
documents and query texts using a [model deployed in an Elasticsearch
cluster](https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding).
### Main features:
1. The ElasticsearchEmbeddings class initializes with an Elasticsearch
connection object and a model_id, providing an interface to interact
with the Elasticsearch ML client through
[infer_trained_model](https://elasticsearch-py.readthedocs.io/en/v8.7.0/api.html?highlight=trained%20model%20infer#elasticsearch.client.MlClient.infer_trained_model)
.
2. The `embed_documents()` method generates embeddings for a list of
documents, and the `embed_query()` method generates an embedding for a
single query text.
3. The class supports custom input text field names in case the deployed
model expects a different field name than the default `text_field`.
4. The implementation is compatible with any model deployed in
Elasticsearch that generates embeddings as output.
### Benefits:
1. Simplifies the process of generating embeddings using Elasticsearch
models.
2. Provides a clean and intuitive interface to interact with the
Elasticsearch ML client.
3. Allows users to easily integrate Elasticsearch-generated embeddings.
Related issue https://github.com/hwchase17/langchain/issues/3400
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Some LLM's will produce numbered lists with leading whitespace, i.e. in
response to "What is the sum of 2 and 3?":
```
Plan:
1. Add 2 and 3.
2. Given the above steps taken, please respond to the users original question.
```
This commit updates the PlanningOutputParser regex to ignore leading
whitespace before the step number, enabling it to correctly parse this
format.
# Allowing openAI fine-tuned models
Very simple fix that checks whether a openAI `model_name` is a
fine-tuned model when loading `context_size` and when computing call's
cost in the `openai_callback`.
Fixes#2887
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Fix typo + add wikipedia package installation part in
human_input_llm.ipynb
This PR
1. Fixes typo ("the the human input LLM"),
2. Addes wikipedia package installation part (in accordance with
`WikipediaQueryRun`
[documentation](https://python.langchain.com/en/latest/modules/agents/tools/examples/wikipedia.html))
in `human_input_llm.ipynb`
(`docs/modules/models/llms/examples/human_input_llm.ipynb`)
# Add link to Psychic from document loaders documentation page
In my previous PR I forgot to update `document_loaders.rst` to link to
`psychic.ipynb` to make it discoverable from the main documentation.