17 KiB
Instruction
Czkawka for now contains two independent frontends - the terminal and graphical interface which share the core module.
GUI GTK
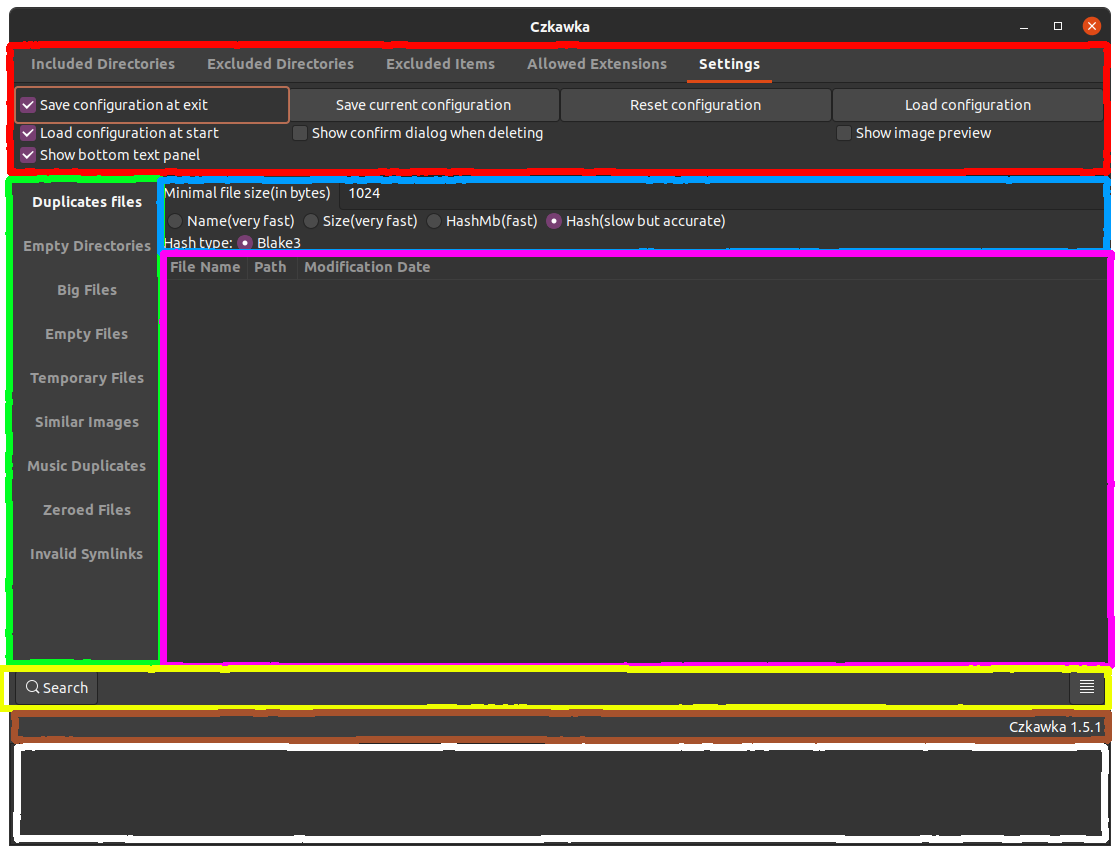
GUI overview
The GUI is built from different pieces:
- Red - Program settings, contains info about included/excluded directories which user may want to check. Also, there is a tab with allowed extensions, which allows users to choose which type of files they want to check. Next category is Excluded items, which allows to discard specific path by using
*wildcard - so/home/ra*means that e.g./home/rafal/will be ignored but not/home/czkawka/. The last one is settings tab which allows to save configuration of the program, reset and load it when needed. - Green - This allows to choose which tool we want to use.
- Blue - Here are settings for the current tool, which we want/need to configure
- Pink - Window in which results of searching are printed
- Yellow - Box with buttons like
Search(starts searching with the currently selected tool),Hide Text View(hides text box at the bottom with white overlay),Symlink(creates symlink to selected file),Select(shows options to select specific rows),Delete(deletes selected files),Save(save to file the search result) - some buttons are only visible when at least one result is visible. - Brown - Small informative field to show informations e.g. about number of found duplicate files
- White - Text window to show possible errors/warnings e.g. when failed to delete folder due no permissions etc.
There is also an option to see image previews in Similar Images tool.
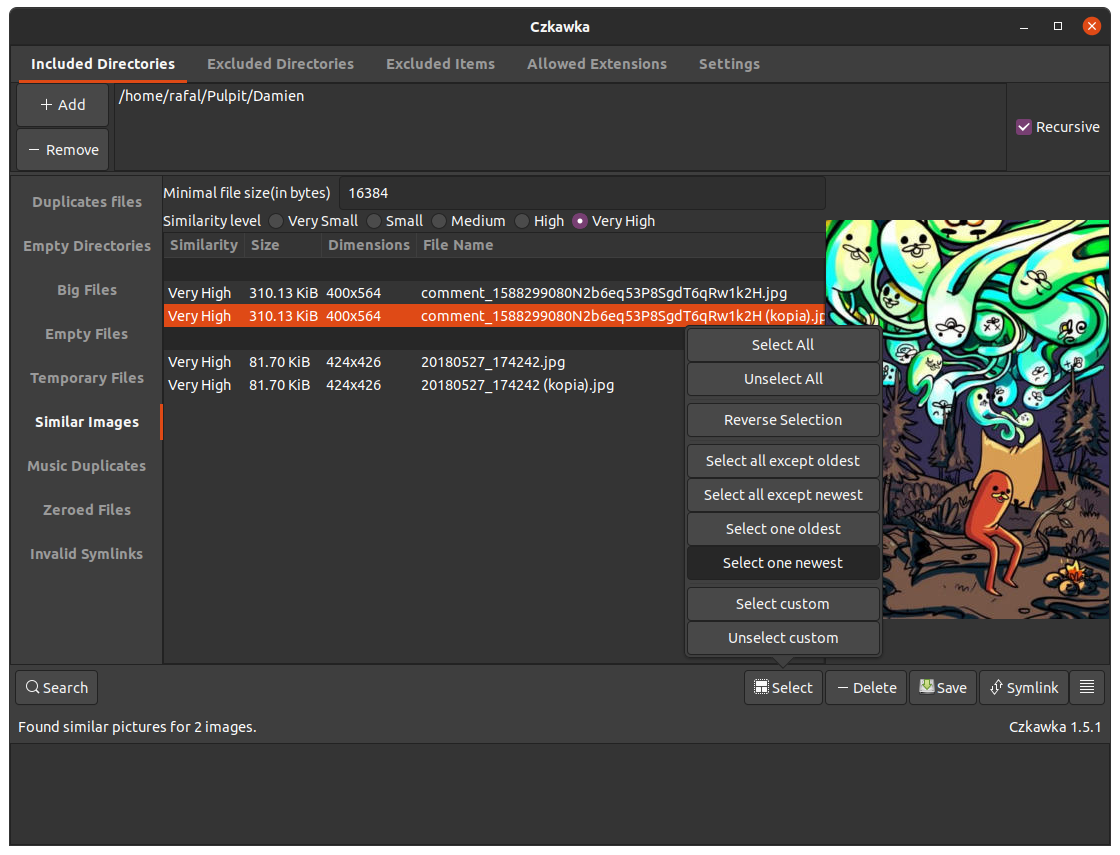
Action Buttons
There are several buttons which do different actions:
- Search - starts searching and shows progress dialog
- Stop - button in progress dialog, allows to easily stop current task. Sometimes it may take a few seconds until all atomic operations end and GUI will become responsive again
- Select - allows selecting multiple entries at once
- Delete - deletes entirely all selected entries
- Symlink - creates symlink to selected files(first file is threaten as original and rest will become symlinks)
- Save - save initial state of results
- Hamburger(parallel lines) - used to show/hide bottom text panel which shows warnings/errors
- Add (directories) - adds directories to include or exclude
- Remove (directories) - removes directories to search or to exclude
- Manual Add (directories) - allows to input by typing directories (may be used to enter non visible in file manager directories)
- Save current configuration - saves current GUI configuration to configuration file
- Load configuration - loads configuration of file and overrides current GUI config
- Reset configuration - resets current GUI configuration to defaults
Opening/Manipulating files
It is possible to open selected files by double clicking on them.
To open multiple file just select desired files with CTRL key pressed and still when clicking this key, double click at selected items with left mouse button.
To open folder containing selected file, just click twice on it with right mouse button.
CLI
Czkawka CLI frontend is great to automate some tasks like removing empty directories.
To get general info how to use it just try to open czkawka_cli in console czkawka_cli
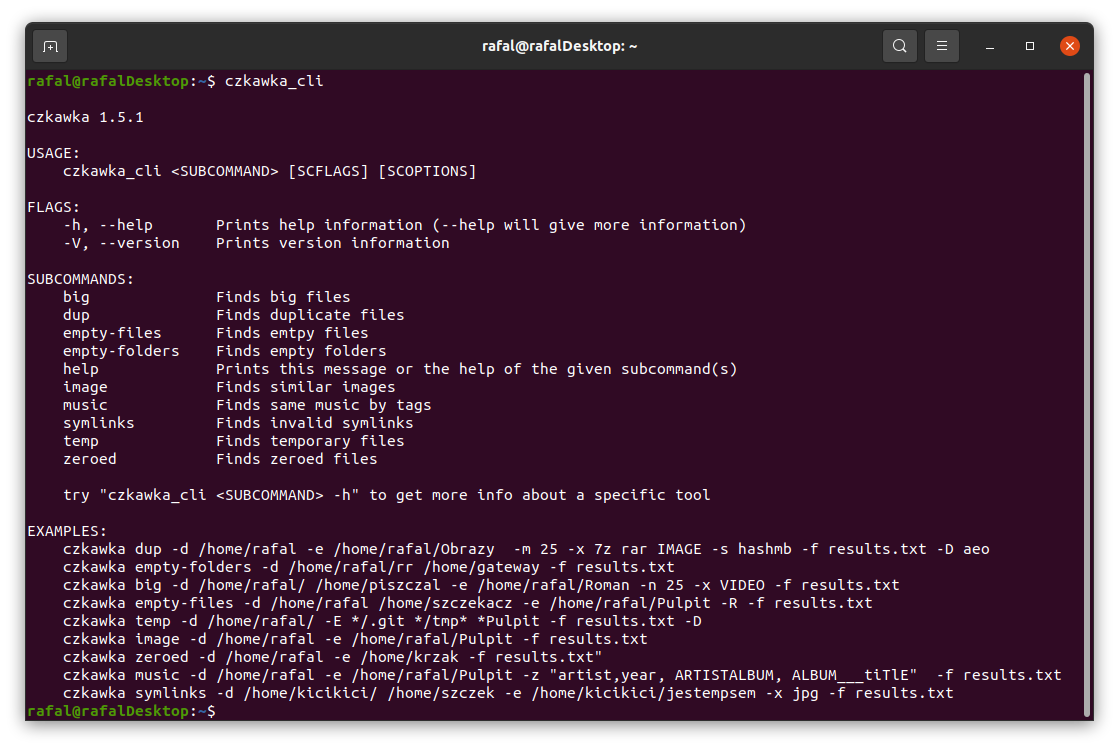
You should see a lot of examples how to use this app.
If you want to get more detailed info about certain tool, just add after its name -h or --help to get more details.
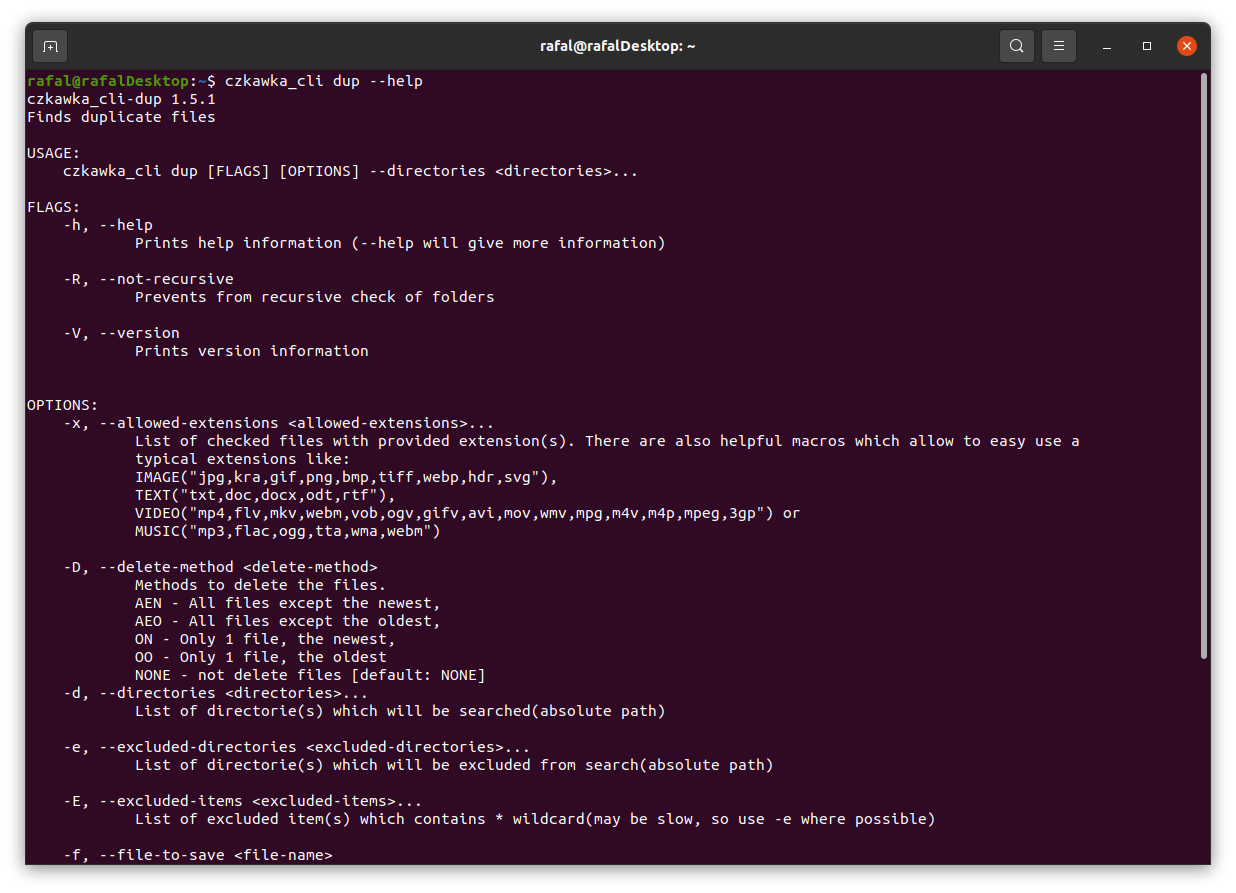
By default, all tools only write about results to console, but it is possible with specific arguments to delete some files/arguments or save it to file.
Config/Cache files
Currently, Czkawka stores few config and cache files on disk:
czkawka_gui_config.txt- stores configuration of GUI which may be loaded at startupcache_similar_image_SIZE_HASH_FILTER.txt- stores cache data and hashes which may be used later without needing to compute image hash again - editing this file manually is not recommended, but it is allowed. Each algorithms uses its own file, because hashes are completely different in each.cache_broken_files.txt- stores cache data of broken filescache_duplicates_Blake3.txt- stores cache data of duplicated files, to not suffer too big of a performance hit when saving/loading file, only already fully hashed files bigger than 5MB are stored. Similar files with replacedBlake3to e.g.SHA256may be shown, when support for new hashes will be introduced in Czkawka.cache_similar_videos.bin/json- stores cache data of video files. Depending on usage(debug/release build) it will produce bin file(fast, but unable to change) or json(slow, but well formatted).
Config files are located in this path:
Linux - /home/username/.config/czkawka
Mac - /Users/username/Library/Application Support/pl.Qarmin.Czkawka
Windows - C:\Users\Username\AppData\Roaming\Qarmin\Czkawka\config
Cache should be here:
Linux - /home/username/.cache/czkawka
Mac - /Users/Username/Library/Caches/pl.Qarmin.Czkawka
Windows - C:\Users\Username\AppData\Local\Qarmin\Czkawka\cache
Tips, Tricks and Known Bugs
- Manually adding multiple directories
You can manually edit config fileczkawka_gui_config.txtand add/remove/change directories as you want. After set required values, configuration must be loaded to Czkawka. - Slow checking of little number similar images/duplicates/broken files
If you checked before a large number of files (several tens of thousands), then the required information about all of them are loaded and saved to the cache, even if you are working with only few files. You can rename one of cache file which starts fromcache_similar_image(to be able to use it again) or delete it - cache will then regenerate but with smaller number of entries and this way it should load and save cache faster. - Not all columns are always visible
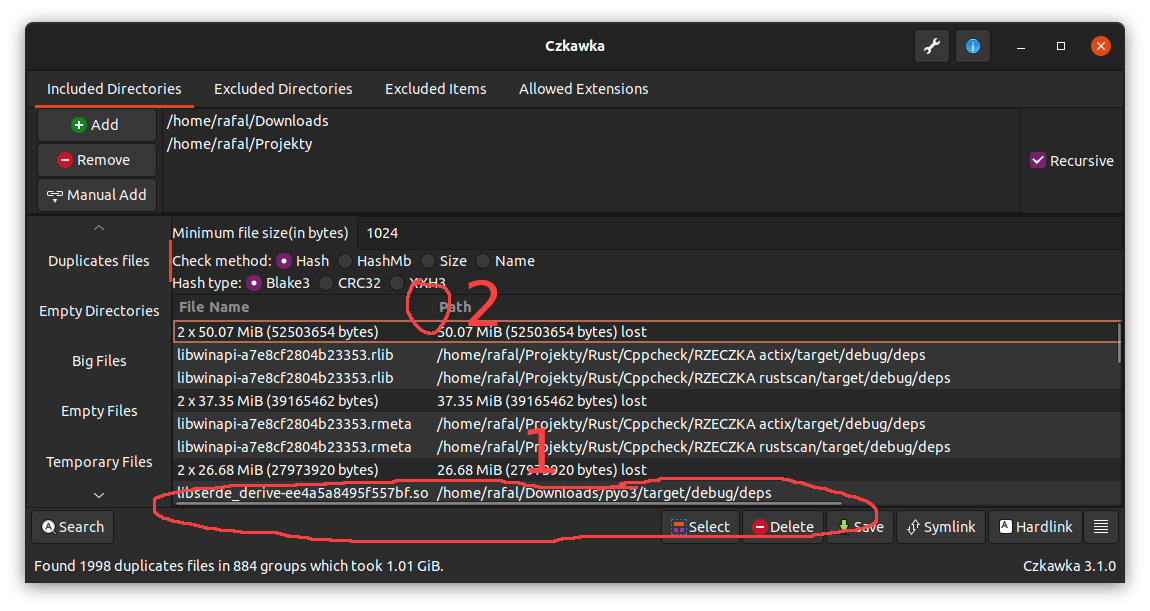
For now it is possible that some columns will not be visible when some are too wide. There are 2 workarounds for now
- View can be scrolled via horizontal scroll bar (1 on image)
- Size of other columns can be slimmed (2 )
This is checked if is possible to do in https://github.com/qarmin/czkawka/issues/169
- Opening parent folders
- It is possible to open parent folder of selected items with double click with right mouse button(RMB) it is also possible to open such item with double click with left mouse button(LMB).
- Faster scanning for big number of duplicates
By default for all files grouped by same size are computed partial hash(hash from only of 2KB each file). Such hash is computed usually very fast, especially on SSD and fast multicore processors. But when scanning a hundred of thousands or millions of files with HDD or slow processor, usually this step can take much time. In settings exists optionUse prehash cachewhich enables caching such things. It is disabled by default because can increase time of loading/saving cache, with big number of entries. - Permanent store of cache entries
After each scan, entries in cache are validated and outdated ones(which points at non-existent files) are removed. This may be problematic when scanning external drivers(like pendrives, disks etc.) and later unplugging and plugging them again. In settings exists optionDelete outdated cache entries automaticallywhich automatically clear this, but this can be disabled. Disabling such option may create big cache files, so buttonRemove outdated resultswill do it manually.
Tools
Duplicate Finder
Duplicate Finder allows you to search for files and group them according to a predefined criterion:
-
By name - Compares and groups files by name e.g.
/home/john/cats.txtwill be treated like a duplicate of a file named/home/lucy/cats.txt. This is the fastest method, but it is very unreliable and should not be used unless you know what you are doing. -
By size - Compares and groups files by their size (in bytes and perfect matches only). It is as fast as the previous mode and usually gives better results with duplicates, but I also do not recommend using it if you do not know what you are doing.
-
By hash - A mode containing a check of the hash (cryptographic hash) of a given file which determines with great probability whether the files are identical.
This is the slowest, but almost 100% sure way to compare the files for being the same.
Because the hash is only checked inside groups of files of the same size, it is practically impossible for two different files to be considered identical.
It consists of 3 steps:
-
Grouping files of identical size - allows you to throw away files of unique size, which are already known to have no duplicates at this stage.
-
PreHash check - Each group of files of identical size is placed in a queue using all processor threads (each action in the group is independent of the others). In each such group a small fragment of each file (2KB) is loaded in turn and then hashed. All files whose partial hashes are unique within the group are removed from it. Using this step usually allows me to reduce the time of searching for duplicates almost by half.
-
Checking the hash - After leaving files that have the same beginning in groups, you should now check the whole contents of the file to make sure they are identical.
-
-
By hashmb - Works the same way as via hash, only in the last phase it does not calculate the hash of the whole file but only of its first megabyte. It is perfect for quick search of possible duplicate files.
Empty Files
Searching for empty files is easy and fast, because we only need to check the file metadata and its length.
Empty Directories
At the beginning, a special entry is created for each directory containing - the parent path (only if it is not a folder directly selected by the user) and a flag to indicate whether the given directory is empty (at the beginning each one is set to be potentionally empty).
First, user-defined folders are put into the pool of folders to be checked.
Each element is checked to see if it is:
- folder - this folder is added to the check queue as possible empty -
FolderEmptiness::Maybe - anything else - the given folder is "poisoned" with the
FolderEmptiness::Noflag, indicating that the folder is no longer empty. Then each folder directly or indirectly containing the file is also poisoned with theFolderEmptiness::Noflag.
Example: there are 4 checked folders which may be empty /cow/, /cow/ear/, /cow/ear/stack/, /cow/ear/flag/.
The last folder contains a file, so that means that /cow/ear/flag is not empty and also all its parents - /cow/ear/ and /cow/,
but /cow/ear/stack/ may still be empty.
Finally, all folders with the flag FolderEmptiness::Maybe are defaulted to empty.
Big Files
For each file inside the given path its size is read and then after sorting the list, e.g. 50 largest, files are displayed.
Temporary Files
Searching for temporary files only involves comparing their extensions with a previously prepared list.
Currently files with these extensions are considered temporary files -
["#", "thumbs.db", ".bak", "~", ".tmp", ".temp", ".ds_store", ".crdownload", ".part", ".cache", ".dmp", ".download", ".partial"]
This only removes the most basic temporary files, for more I suggest to use BleachBit.
Invalid Symlinks
To find invalid symlinks we must first find symlnks.
After searching for them you should check at which element it points to and if it does not exist, add this symlinks into the list of invalid symlinks, pointing to a non-existent path.
The second mode is to detect recursive symlink. Unfortunately, this mode does not work and it displays when using it an error of a non-existent target element, but it is implemented by counting the jumps of the symlink and after exceeding a certain number (e.g. 20) it is considered that the given symlink is recursive.
Same Music
This is a mode to find identical music files through tags.
The number of tags to choose from is limited by an external library.
First, music files with one of the extensions [".mp3", ".flac", ".m4a"] are collected.
Then for each music file its tags are read.
Then, for each selected tag by which we want to search for duplicates, we perform the following steps:
- For each input file we read the value of the currently checked tag
- If it is empty, we ignore the file, if it has a value, we throw it into an array whose key is this value
- After checking all files, arrays containing only one element are deleted
- The remaining files are used as initial data for checking the next tag selected by the user
- After checking all tags, the results are displayed in groups
Similar Images
It is a tool for finding similar images that differ e.g. in watermark, size etc.
The tool first collects images with specific extensions that can be checked - [".jpg", ".jpeg", ".png", ".bmp", ".tiff", ".tif", ".pnm", ".tga", ".ff", ".gif", ".jif", ".jfi", ".ico", ".webp", ".avif"].
Next cached data is loaded from file to prevent hashing twice the same file.
The cache which points to non existing data, by default is deleted automatically.
Then a perceptual hash is created for each image which isn't available in cache.
Cryptographic hash (used for example in ciphers) for similar inputs gives completely different outputs:
11110 ==> AAAAAB
11111 ==> FWNTLW
01110 ==> TWMQLA
Perceptual hash at similar inputs, gives similar outputs:
11110 ==> AAAAAB
11111 ==> AABABB
01110 ==> AAAACB
Computed hash data is then thrown into a special tree that allows to compare hashes using Hamming distance.
Next these hashes are saved to file, to be able to open images without needing to hash it more times.
Finally, each hash is compared with the others and if the distance between them is less than the maximum distance specified by the user, the images are considered similar and thrown from the pool of images to be searched.
It is possible to choose one of 5 types of hashes - Gradient, Mean, VertGradient, Blockhash, DoubleGradient.
Before calculating hashes usually images are resized with specific algorithm(Lanczos3, Gaussian, CatmullRom, Triangle, Nearest) to e.g. 8x8 or 16x16 image(allowed sizes - 4x4, 8x8, 16x16), which allows simplifying later computations. Both size and filter can be adjusted in application.
Each configuration saves results to different cache files to save users from invalid results.
Some images broke hash functions and create hashes full of 0 or 255, so these images are silently excluded from end results(but still are saved to cache).
You can test each algorithm with provided CLI tool, just put to folder test.jpg file and run inside this command czkawka_cli tester -i
Some tidbits:
- Smaller hash size not always means that calculating it will take more time
Blockhashis the only algorithm that don't resize images before hashingNearestresize algorithm can be faster even 5 times than any other available but provide worse results
Similar Videos
Tool works similar as Similar Images.
To work require FFmpeg, so it will show an error when it is not found in OS.
Also only checks files which are longer than 30s.
For now it is limiting to check video files with almost equal length.
At first, it collects video files by extension (mp4, mpv, avi etc.).
Next each file is hashed. Implementation is hidden in library but looks that generate 10 images from this video and hash them with help of perceptual hash.
Such hashes are saved to cache to be able to use them later.
Next, with provided by user tolerance, they are compared to each other and group of similar hashes are returned.
Broken Files
This tool finds files which are corrupted or have an invalid extension.
At first files from specific group (image,archive,audio) are collected and then these files are opened(due to additional dependencies, audio files are disabled by default).
If an error happens when opening such file it means that this file is corrupted or unsupported.
Only some file extensions are handled, because I rely on external crates. Also, some false positives may be shown(e.g. https://github.com/image-rs/jpeg-decoder/issues/130) so always open file to check if it is really broken.