|
|
5 years ago | |
|---|---|---|
| .. | ||
| .cargo | 5 years ago | |
| raspi3_boot | 5 years ago | |
| src | 5 years ago | |
| Cargo.lock | 5 years ago | |
| Cargo.toml | 5 years ago | |
| Makefile | 5 years ago | |
| README.md | 5 years ago | |
| kernel8 | 5 years ago | |
| kernel8.img | 5 years ago | |
| link.ld | 5 years ago | |
README.md
Tutorial 10 - DMA Memory
There's a secret I haven't told you! A certain part of our code doesn't work
anymore since the virtual memory tutorial. There is a
regression that manifests in the Videocore Mailbox driver. It will only work
until paging and caching is switched on. Afterwards, the call() method
will fail. Why is that?
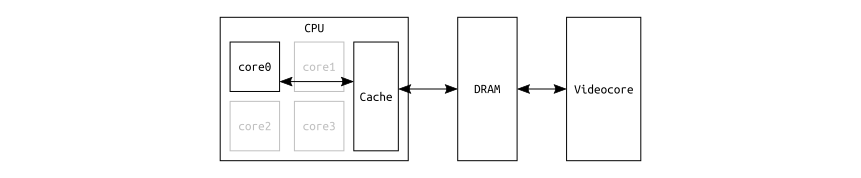
The reason is that in our code, the RPi's processor is sharing a DRAM buffer
with the Videocore device. In other words, the concept of shared memory is
used. Let's recall a simplified version of the protocol:
- RPi
CPUchecks theSTATUSMMIO register of theVidecoreif a message can be written. - If so,
CPUwrites the address of theDRAM bufferin which the actual message is stored into theVideocore'sWRITEMMIO register. CPUchecks theSTATUSandREADMMIO registers if the Videocore has answered.- If so,
CPUchecks the firstu32word of the earlier providedDRAM bufferif the response is valid (theVideocoreputs its answer into the same buffer in which the original request was stored. This is what is commonly called aDMAtransaction).
At step 4, things break. The reason is that code and page tables were
set up in a way that the DRAM buffer used for message exchange between CPU
and Videcore is attributed as cacheable.
So when the CPU is writing to the buffer, the contents might not get written
back to DRAM in time before the notification of a new message is signaled to
the Videocore via the WRITE MMIO register (which is correctly attributed as
device memory in the page tables and hence not cached).
Even if the contents would land in DRAM in time, the Videocore's answer
which overwrites the same buffer would not be reflected in the CPU's cache,
since there is no coherency mechanism in place between the two. The RPi CPU
would read back the same values it put into the buffer itself when setting up
the message, and not the DRAM content that contains the answer.
The regression did not manifest yet because the Mailbox is only used before paging and caching is switched on, and never afterwards. However, now is a good time to fix this.
An Allocator for DMA Memory
The first step is to introduce a region of non-cacheable DRAM in the
KERNEL_VIRTUAL_LAYOUT in memory.rs:
Descriptor {
name: "DMA heap pool",
virtual_range: || RangeInclusive::new(map::virt::DMA_HEAP_START, map::virt::DMA_HEAP_END),
translation: Translation::Identity,
attribute_fields: AttributeFields {
mem_attributes: MemAttributes::NonCacheableDRAM,
acc_perms: AccessPermissions::ReadWrite,
execute_never: true,
},
},
When you saw the inferior performance of non-cacheable mapped DRAM compared to cacheable DRAM in the cache performance tutorial earlier and asked yourself why anybody would ever want this: Exactly for the use-case at hand!
Theoretically, some linker hacks could be used to ensure that the Videcore is
using a buffer that is statically linked to the DMA heap pool once paging and
caching is turned on. However, in real-world kernels, it is common to frequently
map/allocate and unmap/free chunks of DMA memory at runtime, for example in
device drivers for DMA-capable devices.
Hence, let's introduce an allocator.
Bump Allocation
As always in the tutorials, a simple implementation is used for getting started with basic concepts of a topic, and upgrades are introduced when they are needed.
In a bump allocator, when a requests comes in, it always returns the next
possible aligned region of its heap until it runs out of memory. What makes it
really simple is that it doesn't provide means for freeing memory again. When no
more memory is left, game is over.
Conveniently enough, Rust already provides memory allocation APIs. There is an Alloc and a GlobalAlloc trait. The latter is intended for realizing a default allocator, meaning it would be the allocator used for any standard language construtcs that automatically allocate something on the heap, for example a Box. There can only be one global allocator, so the tutorials will make use of it for cacheable DRAM later.
Hence, for the DMA bump allocator,
Alloc will be
used. What is also really nice is that for both traits, only the alloc()
method needs to be implemented. If this is done, you automatically get a bunch
of additional default methods for free, e.g. alloc_zeroed().
Here is the implementation in memory/bump_allocator.rs:
pub struct BumpAllocator {
next: usize,
pool_end: usize,
name: &'static str,
}
unsafe impl Alloc for BumpAllocator {
unsafe fn alloc(&mut self, layout: Layout) -> Result<NonNull<u8>, AllocErr> {
let start = crate::memory::aligned_addr_unchecked(self.next, layout.align());
let end = start + layout.size();
if end <= self.pool_end {
self.next = end;
println!(
"[i] {}:\n Allocated Addr {:#010X} Size {:#X}",
self.name,
start,
layout.size()
);
Ok(NonNull::new_unchecked(start as *mut u8))
} else {
Err(AllocErr)
}
}
// A bump allocator doesn't care
unsafe fn dealloc(&mut self, _ptr: NonNull<u8>, _layout: Layout) {}
}
The alloc() method returns a pointer to memory. However, it is safer to
operate with slices, since
they are intrinsically bounds-checked. Therefore, the BumpAllocator gets an
additional method called alloc_slice_zeroed(), which wraps around
alloc_zeroed() provided by the Alloc trait and on success returns a &'a mut [T].
Global Instance
A global instance of the allocator is needed, and since its methods demand
mutable references to self, it is wrapped into a NullLock, which was
introduced in the last tutorial:
/// The global allocator for DMA-able memory. That is, memory which is tagged
/// non-cacheable in the page tables.
static DMA_ALLOCATOR: sync::NullLock<memory::BumpAllocator> =
sync::NullLock::new(memory::BumpAllocator::new(
memory::map::virt::DMA_HEAP_START as usize,
memory::map::virt::DMA_HEAP_END as usize,
"Global DMA Allocator",
));
Videocore Driver
The Videocore driver has to be changed to use the allocator during
instantiation, and in contrast to earlier, this could fail now:
let ret = crate::DMA_ALLOCATOR.lock(|d| d.alloc_slice_zeroed(MBOX_SIZE, MBOX_ALIGNMENT));
if ret.is_err() {
return Err(());
}
Reorg of the Kernel Init
Since the Videcore now depends on the DMA Allocator, its initialization must
now happen after the MMU init, which turns on paging and caching. This,
in turn, means that the PL011 UART, which is used for printing and needs the
Videcore for its setup, has to shift its init as well. So there is a lot of
shuffling happening.
In summary, the new init procedure would be:
- GPIO
- MMU
- Videcore
- PL011 UART
That is a bit unfortunate, because if anything goes wrong at MMU or
Videocore init, we can not print any fault info on the console. For this
reason, the MiniUart from the earlier tutorials is revived, because it only
needs the GPIO driver to set itself up. So here is the revamped init:
- GPIO
- MiniUart
- MMU
- Videcore
- PL011 UART
Using this procedure, the MiniUart can report faults for any of the subsequent
stages likeMMU or Videocore init. If all is successful and the more capable
PL011 UART comes online, we can let it conveniently replace the MiniUart
through the CONSOLE.replace_with() scheme introduced in the last tutorial.
Make it Fault
If you feel curious and want to put all the theory to action, take a look at the
code in main.rs for the DMA allocator instantiation and try the changes in the
comments:
/// The global allocator for DMA-able memory. That is, memory which is tagged
/// non-cacheable in the page tables.
static DMA_ALLOCATOR: sync::NullLock<memory::BumpAllocator> =
sync::NullLock::new(memory::BumpAllocator::new(
memory::map::virt::DMA_HEAP_START as usize,
memory::map::virt::DMA_HEAP_END as usize,
"Global DMA Allocator",
// Try the following arguments instead to see the PL011 UART init
// fail. It will cause the allocator to use memory that is marked
// cacheable and therefore not DMA-safe. The communication with the
// Videocore will therefore fail.
// 0x00600000 as usize,
// 0x007FFFFF as usize,
// "Global Non-DMA Allocator",
));
This might only work on the real HW and not in QEMU.
QEMU
On the actual HW it is possible to reprogram the same GPIO pins at runtime to
either use the MiniUart or the PL011, and as a result the console output of
both is sent through the same USB-serial dongle. This is transparent to the
user.
On QEMU, unfortunately, two different virtual terminals must be used and this
multiplexing is not possible. As a result, you'll see that the QEMU output has
changed in optics a bit and now provides separate views for the two UARTs.
Output
ferris@box:~$ make raspboot
[0] MiniUart online.
[1] Press a key to continue booting... Greetings fellow Rustacean!
[2] MMU online.
[i] Kernel memory layout:
0x00000000 - 0x0007FFFF | 512 KiB | C RW PXN | Kernel stack
0x00080000 - 0x00083FFF | 16 KiB | C RO PX | Kernel code and RO data
0x00084000 - 0x0008700F | 12 KiB | C RW PXN | Kernel data and BSS
0x00200000 - 0x005FFFFF | 4 MiB | NC RW PXN | DMA heap pool
0x3F000000 - 0x3FFFFFFF | 16 MiB | Dev RW PXN | Device MMIO
[i] Global DMA Allocator:
Allocated Addr 0x00200000 Size 0x90
[3] Videocore Mailbox set up (DMA mem heap allocation successful).
[4] PL011 UART online. Output switched to it.
$>