{
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Question answering using a search API and re-ranking\n",
"\n",
"Searching for relevant information can sometimes feel like looking for a needle in a haystack, but don’t despair, GPTs can actually do a lot of this work for us. In this guide we explore a way to augment existing search systems with various AI techniques, helping us sift through the noise.\n",
"\n",
"Two ways of retrieving information for GPT are:\n",
"\n",
"1. **Mimicking Human Browsing:** [GPT triggers a search](https://openai.com/blog/chatgpt-plugins#browsing), evaluates the results, and modifies the search query if necessary. It can also follow up on specific search results to form a chain of thought, much like a human user would do.\n",
"2. **Retrieval with Embeddings:** Calculate [embeddings](https://platform.openai.com/docs/guides/embeddings) for your content and a user query, and then [retrieve the content](Question_answering_using_embeddings.ipynb) most related as measured by cosine similarity. This technique is [used heavily](https://blog.google/products/search/search-language-understanding-bert/) by search engines like Google.\n",
"\n",
"These approaches are both promising, but each has their shortcomings: the first one can be slow due to its iterative nature and the second one requires embedding your entire knowledge base in advance, continuously embedding new content and maintaining a vector database.\n",
"\n",
"By combining these approaches, and drawing inspiration from [re-ranking](https://www.sbert.net/examples/applications/retrieve_rerank/README.html) methods, we identify an approach that sits in the middle. **This approach can be implemented on top of any existing search system, like the Slack search API, or an internal ElasticSearch instance with private data**. Here’s how it works:\n",
"\n",
"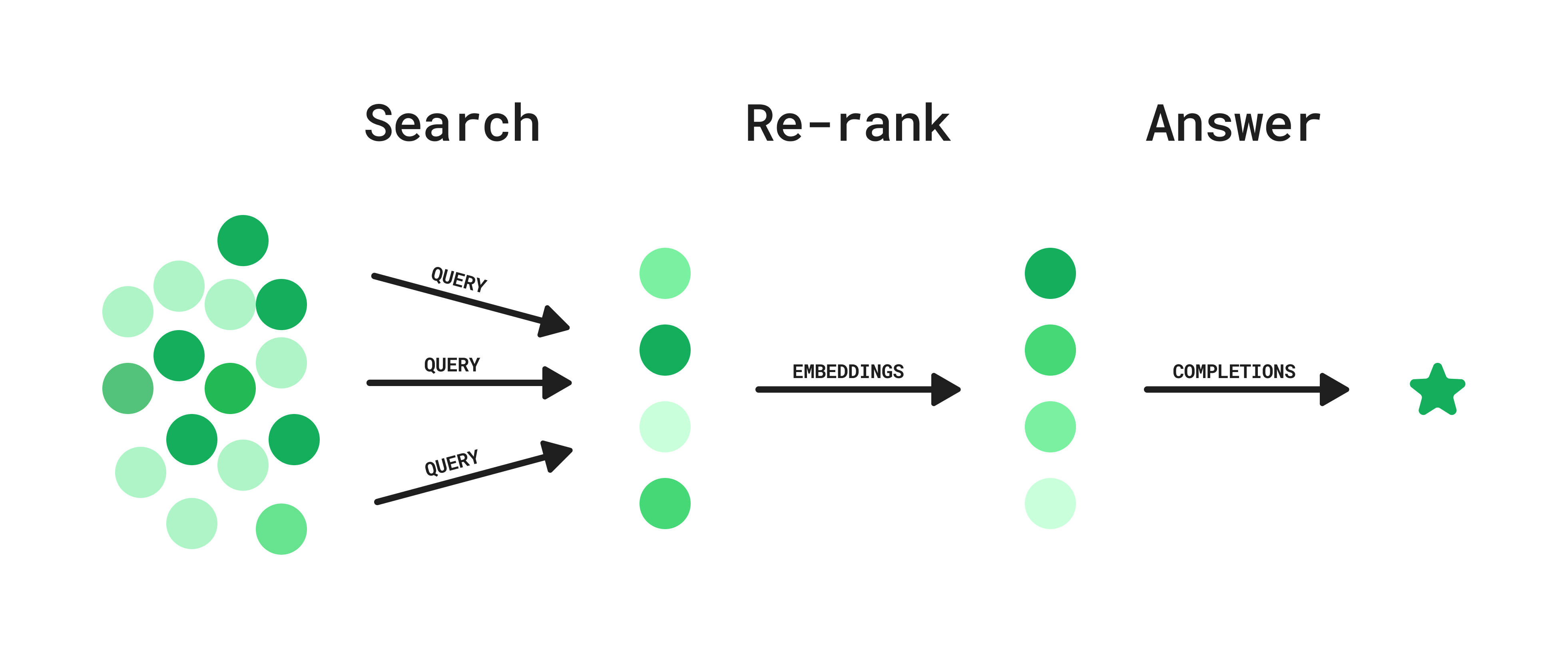\n",
"\n",
"**Step 1: Search**\n",
"\n",
"1. User asks a question.\n",
"2. GPT generates a list of potential queries.\n",
"3. Search queries are executed in parallel.\n",
"\n",
"**Step 2: Re-rank**\n",
"\n",
"1. Embeddings for each result are used to calculate semantic similarity to a generated hypothetical ideal answer to the user question.\n",
"2. Results are ranked and filtered based on this similarity metric.\n",
"\n",
"**Step 3: Answer**\n",
"\n",
"1. Given the top search results, the model generates an answer to the user’s question, including references and links.\n",
"\n",
"This hybrid approach offers relatively low latency and can be integrated into any existing search endpoint, without requiring the upkeep of a vector database. Let's dive into it! We will use the [News API](https://newsapi.org/) as an example domain to search over.\n",
"\n",
"## Setup\n",
"\n",
"In addition to your `OPENAI_API_KEY`, you'll have to include a `NEWS_API_KEY` in your environment. You can get an API key [here](https://newsapi.org/).\n"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"%%capture\n",
"%env NEWS_API_KEY = YOUR_NEWS_API_KEY\n"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"# Dependencies\n",
"from datetime import date, timedelta # date handling for fetching recent news\n",
"from IPython import display # for pretty printing\n",
"import json # for parsing the JSON api responses and model outputs\n",
"from numpy import dot # for cosine similarity\n",
"import openai # for using GPT and getting embeddings\n",
"import os # for loading environment variables\n",
"import requests # for making the API requests\n",
"from tqdm.notebook import tqdm # for printing progress bars\n",
"\n",
"# Load environment variables\n",
"news_api_key = os.getenv(\"NEWS_API_KEY\")\n",
"\n",
"GPT_MODEL = \"gpt-3.5-turbo\"\n",
"\n",
"\n",
"# Helper functions\n",
"def json_gpt(input: str):\n",
" completion = openai.ChatCompletion.create(\n",
" model=GPT_MODEL,\n",
" messages=[\n",
" {\"role\": \"system\", \"content\": \"Output only valid JSON\"},\n",
" {\"role\": \"user\", \"content\": input},\n",
" ],\n",
" temperature=0.5,\n",
" )\n",
"\n",
" text = completion.choices[0].message.content\n",
" parsed = json.loads(text)\n",
"\n",
" return parsed\n",
"\n",
"\n",
"def embeddings(input: list[str]) -> list[list[str]]:\n",
" response = openai.Embedding.create(model=\"text-embedding-ada-002\", input=input)\n",
" return [data.embedding for data in response.data]"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1. Search\n",
"\n",
"It all starts with a user question.\n"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"# User asks a question\n",
"USER_QUESTION = \"Who won the NBA championship? And who was the MVP? Tell me a bit about the last game.\""
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, in order to be as exhaustive as possible, we use the model to generate a list of diverse queries based on this question.\n"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"['NBA championship winner',\n",
" 'MVP of NBA championship',\n",
" 'Last game of NBA championship',\n",
" 'NBA finals winner',\n",
" 'Most valuable player of NBA championship',\n",
" 'Finals game of NBA',\n",
" 'Who won the NBA finals',\n",
" 'NBA championship game summary',\n",
" 'NBA finals MVP',\n",
" 'Champion of NBA playoffs',\n",
" 'NBA finals last game highlights',\n",
" 'NBA championship series result',\n",
" 'NBA finals game score',\n",
" 'NBA finals game recap',\n",
" 'NBA champion team and player',\n",
" 'NBA finals statistics',\n",
" 'NBA championship final score',\n",
" 'NBA finals best player',\n",
" 'NBA playoffs champion and MVP',\n",
" 'NBA finals game analysis',\n",
" 'Who won the NBA championship? And who was the MVP? Tell me a bit about the last game.']"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"QUERIES_INPUT = f\"\"\"\n",
"You have access to a search API that returns recent news articles.\n",
"Generate an array of search queries that are relevant to this question.\n",
"Use a variation of related keywords for the queries, trying to be as general as possible.\n",
"Include as many queries as you can think of, including and excluding terms.\n",
"For example, include queries like ['keyword_1 keyword_2', 'keyword_1', 'keyword_2'].\n",
"Be creative. The more queries you include, the more likely you are to find relevant results.\n",
"\n",
"User question: {USER_QUESTION}\n",
"\n",
"Format: {{\"queries\": [\"query_1\", \"query_2\", \"query_3\"]}}\n",
"\"\"\"\n",
"\n",
"queries = json_gpt(QUERIES_INPUT)[\"queries\"]\n",
"\n",
"# Let's include the original question as well for good measure\n",
"queries.append(USER_QUESTION)\n",
"\n",
"queries"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"The queries look good, so let's run the searches.\n"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "6c750d6e5b2846b6834bad47ea5bef8b",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
" 0%| | 0/21 [00:00Nascar has presence at iconic race for first time since 1976NBA superstar LeBron James waves flag as honorary starterThe crowd chanted “U-S-A! U-S-A!” as Nascar driver lineup for the 24 Hours of Le Mans passed through the city cente…\n",
"Content: The crowd chanted U-S-A! U-S-A! as Nascar driver lineup for the 24 Hours of Le Mans passed through t...\n",
"\n",
"Title: NBA finals predictions: Nuggets or Heat? Our writers share their picks\n",
"Description: Denver or Miami? Our contributors pick the winner, key players and dark horses before the NBA’s grand finale tips offA lot has been made of the importance of a balanced roster with continuity, but, somehow, still not enough. The Nuggets are the prime example …\n",
"Content: The Nuggets are here because \n",
"A lot has been made of the importance of a balanced roster with conti...\n",
"\n",
"Title: Unboxing: Michelob ULTRA and Artist Futura Enshrine the NBA Championship In Custom Hand-Painted Bottles\n",
"Description: As the 2022-2023 NBA Championship nears the end, Michelob ULTRA brings joy to sports fans who will gather to watch the showdown between the Denver Nuggets and Miami Heat. The beermaker teamed up with artist Futura to remix its newly-designed 2023 Champ Bottle…\n",
"Content: As the 2022-2023 NBA Championship nears the end, Michelob ULTRA brings joy to sports fans who will g...\n",
"\n",
"Title: Futura and Michelob ULTRA Toast to the NBA Finals With Abstract Artwork Crafted From the Brand’s 2023 Limited-Edition Championship Bottles\n",
"Description: The sun is out to play, and so is Michelob ULTRA. With the 2022-2023 NBA Finals underway, the beermaker is back with its celebratory NBA Champ Bottles. This year, the self-proclaimed MVP of joy is dropping a limited-edition bottle made in collaboration with a…\n",
"Content: The sun is out to play, and so is Michelob ULTRA. With the 2022-2023 NBA Finals underway, the beerma...\n",
"\n",
"Title: Signed and Delivered, Futura and Michelob ULTRA Will Gift Hand-Painted Bottles to This Year’s NBA Championship Team\n",
"Description: Michelob ULTRA, the MVP of joy and official beer sponsor of the NBA is back to celebrate with basketball lovers and sports fans around the globe as the NBA 2022-2023 season comes to a nail-biting close. In collaboration with artist Futura, Michelob ULTRA will…\n",
"Content: Michelob ULTRA, the MVP of joy and official beer sponsor of the NBA is back to celebrate with basket...\n",
"\n"
]
}
],
"source": [
"def search_news(\n",
" query: str,\n",
" news_api_key: str = news_api_key,\n",
" num_articles: int = 50,\n",
" from_datetime: str = \"2023-06-01\", # the 2023 NBA finals were played in June 2023\n",
" to_datetime: str = \"2023-06-30\",\n",
") -> dict:\n",
" response = requests.get(\n",
" \"https://newsapi.org/v2/everything\",\n",
" params={\n",
" \"q\": query,\n",
" \"apiKey\": news_api_key,\n",
" \"pageSize\": num_articles,\n",
" \"sortBy\": \"relevancy\",\n",
" \"from\": from_datetime,\n",
" \"to\": to_datetime,\n",
" },\n",
" )\n",
"\n",
" return response.json()\n",
"\n",
"\n",
"articles = []\n",
"\n",
"for query in tqdm(queries):\n",
" result = search_news(query)\n",
" if result[\"status\"] == \"ok\":\n",
" articles = articles + result[\"articles\"]\n",
" else:\n",
" raise Exception(result[\"message\"])\n",
"\n",
"# remove duplicates\n",
"articles = list({article[\"url\"]: article for article in articles}.values())\n",
"\n",
"print(\"Total number of articles:\", len(articles))\n",
"print(\"Top 5 articles of query 1:\", \"\\n\")\n",
"\n",
"for article in articles[0:5]:\n",
" print(\"Title:\", article[\"title\"])\n",
" print(\"Description:\", article[\"description\"])\n",
" print(\"Content:\", article[\"content\"][0:100] + \"...\")\n",
" print()\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"As we can see, oftentimes, the search queries will return a large number of results, many of which are not relevant to the original question asked by the user. In order to improve the quality of the final answer, we use embeddings to re-rank and filter the results.\n",
"\n",
"# 2. Re-rank\n",
"\n",
"Drawing inspiration from [HyDE (Gao et al.)](https://arxiv.org/abs/2212.10496), we first generate a hypothetical ideal answer to rerank our compare our results against. This helps prioritize results that look like good answers, rather than those similar to our question. Here’s the prompt we use to generate our hypothetical answer.\n"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'The NBA championship was won by TEAM NAME. The MVP was awarded to PLAYER NAME. The last game was held at STADIUM NAME, where both teams played with great energy and enthusiasm. It was a close game, but in the end, TEAM NAME emerged victorious.'"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"HA_INPUT = f\"\"\"\n",
"Generate a hypothetical answer to the user's question. This answer will be used to rank search results. \n",
"Pretend you have all the information you need to answer, but don't use any actual facts. Instead, use placeholders\n",
"like NAME did something, or NAME said something at PLACE. \n",
"\n",
"User question: {USER_QUESTION}\n",
"\n",
"Format: {{\"hypotheticalAnswer\": \"hypothetical answer text\"}}\n",
"\"\"\"\n",
"\n",
"hypothetical_answer = json_gpt(HA_INPUT)[\"hypotheticalAnswer\"]\n",
"\n",
"hypothetical_answer\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's generate embeddings for the search results and the hypothetical answer. We then calculate the cosine distance between these embeddings, giving us a semantic similarity metric. Note that we can simply calculate the dot product in lieu of doing a full cosine similarity calculation since the OpenAI embeddings are returned normalized in our API.\n"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[0.7854456526852069,\n",
" 0.8086023500072106,\n",
" 0.8002998147018501,\n",
" 0.7961229569526956,\n",
" 0.798354506673743,\n",
" 0.758216458795653,\n",
" 0.7753754083127359,\n",
" 0.7494958338411927,\n",
" 0.804733946801739,\n",
" 0.8405965885235218]"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"hypothetical_answer_embedding = embeddings(hypothetical_answer)[0]\n",
"article_embeddings = embeddings(\n",
" [\n",
" f\"{article['title']} {article['description']} {article['content'][0:100]}\"\n",
" for article in articles\n",
" ]\n",
")\n",
"\n",
"# Calculate cosine similarity\n",
"cosine_similarities = []\n",
"for article_embedding in article_embeddings:\n",
" cosine_similarities.append(dot(hypothetical_answer_embedding, article_embedding))\n",
"\n",
"cosine_similarities[0:10]\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, we use these similarity scores to sort and filter the results.\n"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Top 5 articles: \n",
"\n",
"Title: NBA Finals: Denver Nuggets beat Miami Hea, lift thier first-ever NBA title\n",
"Description: Denver Nuggets won their maiden NBA Championship trophy defeating Miami Heat 94-89 in Game 5 of the NBA Final held on Tuesday at the Ball Arena in Denver\n",
"Content: Denver Nuggets won their maiden NBA Championship trophy defeating Miami Heat 94-89 in Game 5 of the ...\n",
"Score: 0.8445817523602124\n",
"\n",
"Title: Photos: Denver Nuggets celebrate their first NBA title\n",
"Description: The Nuggets capped off an impressive postseason by beating the Miami Heat in the NBA Finals.\n",
"Content: Thousands of supporters watched along the streets of Denver, Colorado as the US National Basketball ...\n",
"Score: 0.842070667753606\n",
"\n",
"Title: Denver Nuggets win first NBA championship title in Game 5 victory over Miami Heat\n",
"Description: The Denver Nuggets won their first NBA championship Monday night, downing the Miami Heat 94-89 at Ball Arena in Denver to take Game 5 of the NBA Finals.\n",
"Content: The Denver Nuggets won their first NBA championship Monday night, downing the Miami Heat 94-89 at Ba...\n",
"Score: 0.8409346078172385\n",
"\n",
"Title: Denver Nuggets Capture Their First NBA Championship Behind Unbreakable Chemistry\n",
"Description: After 47 years of waiting, the Denver Nuggets are NBA champions. Led by Nikola Jokic and Jamal Murray, they reached the mountain top by staying true to themselves.\n",
"Content: DENVER, CO - JUNE 12: Jamal Murray (27) of the Denver Nuggets celebrates as he leaves the court ... ...\n",
"Score: 0.8405965885235218\n",
"\n",
"Title: NBA Finals: Nikola Jokic, Denver Nuggets survive Miami Heat to secure franchise's first NBA championship\n",
"Description: In a rock-fight of a Game 5, the Denver Nuggets reached the NBA mountaintop from the foothills of the Rockies, winning their first-ever championship and setting Nikola Jokic's legacy as an all-timer in stone.\n",
"Content: DENVER, COLORADO - JUNE 12: Jamal Murray #27 of the Denver Nuggets reacts during the fourth quarter ...\n",
"Score: 0.8389716330890262\n",
"\n"
]
}
],
"source": [
"scored_articles = zip(articles, cosine_similarities)\n",
"\n",
"# Sort articles by cosine similarity\n",
"sorted_articles = sorted(scored_articles, key=lambda x: x[1], reverse=True)\n",
"\n",
"# Print top 5 articles\n",
"print(\"Top 5 articles:\", \"\\n\")\n",
"\n",
"for article, score in sorted_articles[0:5]:\n",
" print(\"Title:\", article[\"title\"])\n",
" print(\"Description:\", article[\"description\"])\n",
" print(\"Content:\", article[\"content\"][0:100] + \"...\")\n",
" print(\"Score:\", score)\n",
" print()\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Awesome! These results look a lot more relevant to our original query. Now, let's use the top 5 results to generate a final answer.\n",
"\n",
"## 3. Answer\n"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"data": {
"text/markdown": [
"The Denver Nuggets won their first-ever NBA championship by defeating the Miami Heat 94-89 in Game 5 of the NBA Finals held on Tuesday at the Ball Arena in Denver, according to this [Business Standard article](https://www.business-standard.com/sports/other-sports-news/nba-finals-denver-nuggets-beat-miami-hea-lift-thier-first-ever-nba-title-123061300285_1.html). Nikola Jokic, the Nuggets' center, was named the NBA Finals MVP. In a rock-fight of a Game 5, the Nuggets reached the NBA mountaintop, securing their franchise's first NBA championship and setting Nikola Jokic's legacy as an all-timer in stone, according to this [Yahoo Sports article](https://sports.yahoo.com/nba-finals-nikola-jokic-denver-nuggets-survive-miami-heat-to-secure-franchises-first-nba-championship-030321214.html). For more information and photos of the Nuggets' celebration, check out this [Al Jazeera article](https://www.aljazeera.com/gallery/2023/6/15/photos-denver-nuggets-celebrate-their-first-nba-title) and this [CNN article](https://www.cnn.com/2023/06/12/sport/denver-nuggets-nba-championship-spt-intl?cid=external-feeds_iluminar_yahoo)."
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"formatted_top_results = [\n",
" {\n",
" \"title\": article[\"title\"],\n",
" \"description\": article[\"description\"],\n",
" \"url\": article[\"url\"],\n",
" }\n",
" for article, _score in sorted_articles[0:5]\n",
"]\n",
"\n",
"ANSWER_INPUT = f\"\"\"\n",
"Generate an answer to the user's question based on the given search results. \n",
"TOP_RESULTS: {formatted_top_results}\n",
"USER_QUESTION: {USER_QUESTION}\n",
"\n",
"Include as much information as possible in the answer. Reference the relevant search result urls as markdown links.\n",
"\"\"\"\n",
"\n",
"completion = openai.ChatCompletion.create(\n",
" model=GPT_MODEL,\n",
" messages=[{\"role\": \"user\", \"content\": ANSWER_INPUT}],\n",
" temperature=0.5,\n",
" stream=True,\n",
")\n",
"\n",
"text = \"\"\n",
"for chunk in completion:\n",
" text += chunk.choices[0].delta.get(\"content\", \"\")\n",
" display.clear_output(wait=True)\n",
" display.display(display.Markdown(text))"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.11.0"
},
"orig_nbformat": 4
},
"nbformat": 4,
"nbformat_minor": 2
}