Cassandra / Astra DB demo notebooks: adapt to OpenAI 1.0, add support for Astra DB HTTP API, and other upgrades (#853)
parent
988139d70e
commit
d13dc3b557
@ -0,0 +1,885 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "46589cdf-1ab6-4028-b07c-08b75acd98e5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Philosophy with Vector Embeddings, OpenAI and Astra DB\n",
|
||||
"\n",
|
||||
"### AstraPy version"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b3496d07-f473-4008-9133-1a54b818c8d3",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In this quickstart you will learn how to build a \"philosophy quote finder & generator\" using OpenAI's vector embeddings and DataStax [Astra DB](https://docs.datastax.com/en/astra/home/astra.html) as the vector store for data persistence.\n",
|
||||
"\n",
|
||||
"The basic workflow of this notebook is outlined below. You will evaluate and store the vector embeddings for a number of quotes by famous philosophers, use them to build a powerful search engine and, after that, even a generator of new quotes!\n",
|
||||
"\n",
|
||||
"The notebook exemplifies some of the standard usage patterns of vector search -- while showing how easy is it to get started with [Astra DB](https://docs.datastax.com/en/astra/home/astra.html).\n",
|
||||
"\n",
|
||||
"For a background on using vector search and text embeddings to build a question-answering system, please check out this excellent hands-on notebook: [Question answering using embeddings](https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb).\n",
|
||||
"\n",
|
||||
"Table of contents:\n",
|
||||
"- Setup\n",
|
||||
"- Create vector collection\n",
|
||||
"- Connect to OpenAI\n",
|
||||
"- Load quotes into the Vector Store\n",
|
||||
"- Use case 1: **quote search engine**\n",
|
||||
"- Use case 2: **quote generator**\n",
|
||||
"- Cleanup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "cddf17cc-eef4-4021-b72a-4d3832a9b4a7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### How it works\n",
|
||||
"\n",
|
||||
"**Indexing**\n",
|
||||
"\n",
|
||||
"Each quote is made into an embedding vector with OpenAI's `Embedding`. These are saved in the Vector Store for later use in searching. Some metadata, including the author's name and a few other pre-computed tags, are stored alongside, to allow for search customization.\n",
|
||||
"\n",
|
||||
"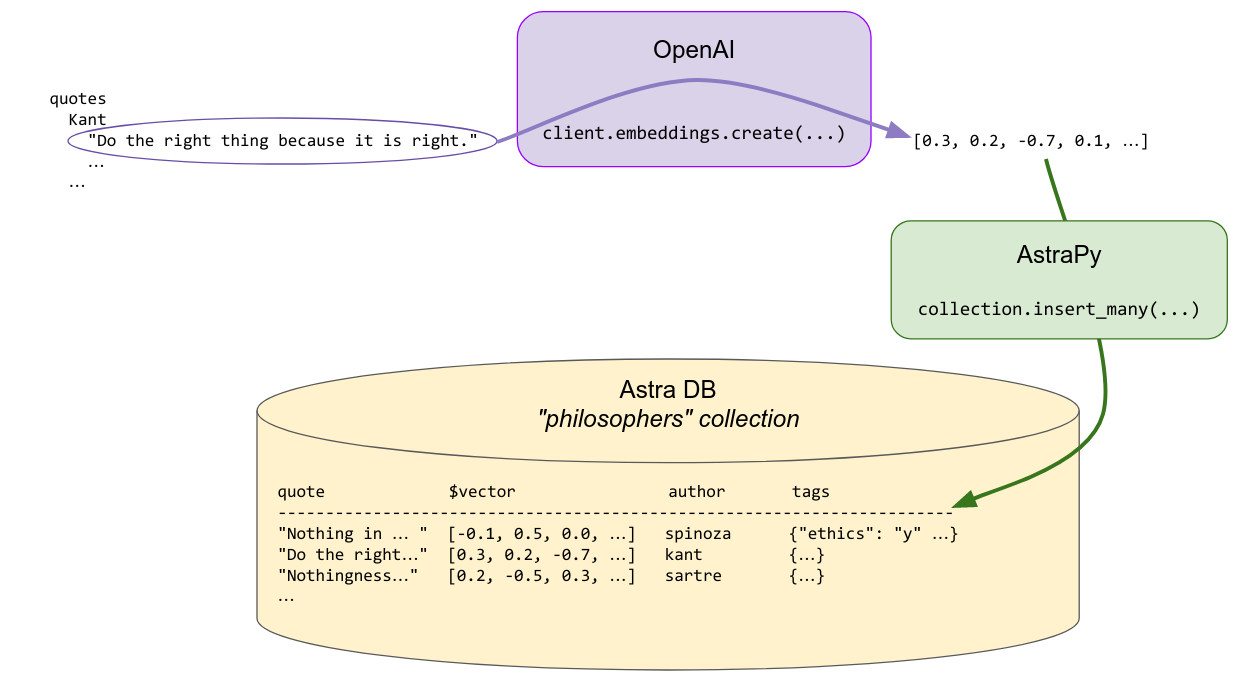\n",
|
||||
"\n",
|
||||
"**Search**\n",
|
||||
"\n",
|
||||
"To find a quote similar to the provided search quote, the latter is made into an embedding vector on the fly, and this vector is used to query the store for similar vectors ... i.e. similar quotes that were previously indexed. The search can optionally be constrained by additional metadata (\"find me quotes by Spinoza similar to this one ...\").\n",
|
||||
"\n",
|
||||
"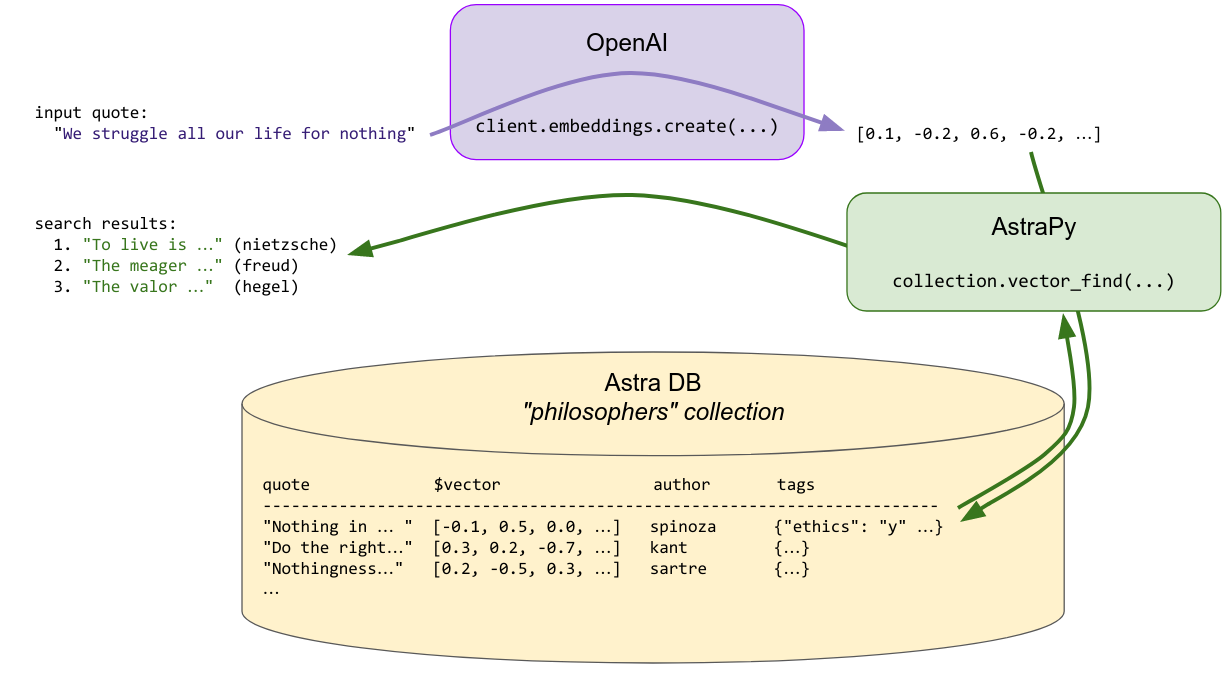\n",
|
||||
"\n",
|
||||
"The key point here is that \"quotes similar in content\" translates, in vector space, to vectors that are metrically close to each other: thus, vector similarity search effectively implements semantic similarity. _This is the key reason vector embeddings are so powerful._\n",
|
||||
"\n",
|
||||
"The sketch below tries to convey this idea. Each quote, once it's made into a vector, is a point in space. Well, in this case it's on a sphere, since OpenAI's embedding vectors, as most others, are normalized to _unit length_. Oh, and the sphere is actually not three-dimensional, rather 1536-dimensional!\n",
|
||||
"\n",
|
||||
"So, in essence, a similarity search in vector space returns the vectors that are closest to the query vector:\n",
|
||||
"\n",
|
||||
"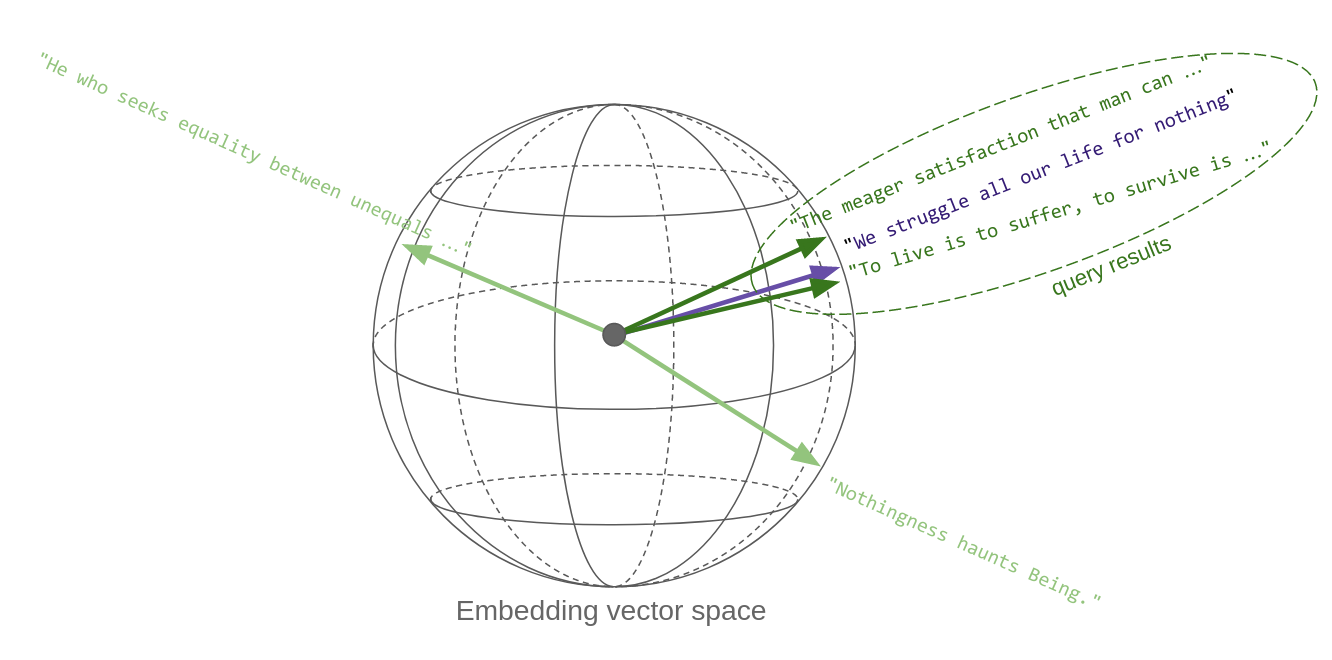\n",
|
||||
"\n",
|
||||
"**Generation**\n",
|
||||
"\n",
|
||||
"Given a suggestion (a topic or a tentative quote), the search step is performed, and the first returned results (quotes) are fed into an LLM prompt which asks the generative model to invent a new text along the lines of the passed examples _and_ the initial suggestion.\n",
|
||||
"\n",
|
||||
"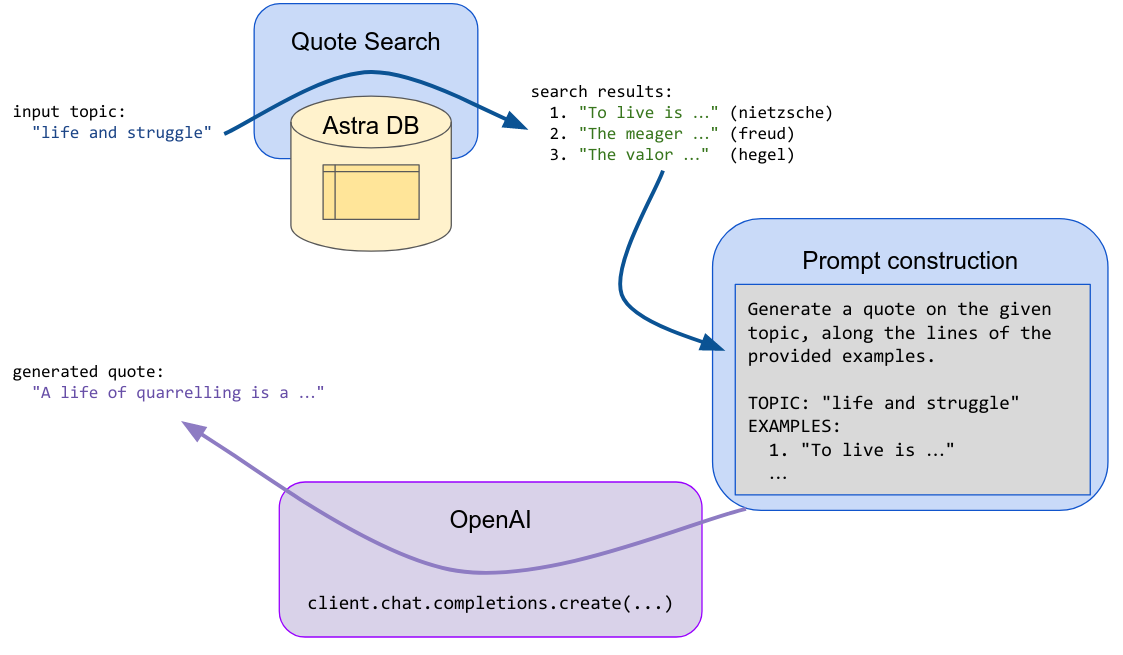"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "10493f44-565d-4f23-8bfd-1a7335392c2b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "44a14f95-4683-4d0c-a251-0df7b43ca975",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Install and import the necessary dependencies:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "39afdb74-56e4-44ff-9c72-ab2669780113",
|
||||
"metadata": {
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install --quiet \"astrapy>=0.6.0\" \"openai>=1.0.0\" datasets"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "9ca6f5c6-30b4-4518-a816-5c732a60e339",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from getpass import getpass\n",
|
||||
"from collections import Counter\n",
|
||||
"\n",
|
||||
"from astrapy.db import AstraDB\n",
|
||||
"import openai\n",
|
||||
"from datasets import load_dataset"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9cb99e33-5cb7-416f-8dca-da18e0cb108d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Connection parameters"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "65a8edc1-4633-491b-9ed3-11163ec24e46",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Please retrieve your database credentials on your Astra dashboard ([info](https://docs.datastax.com/en/astra/astra-db-vector/)): you will supply them momentarily.\n",
|
||||
"\n",
|
||||
"Example values:\n",
|
||||
"\n",
|
||||
"- API Endpoint: `https://01234567-89ab-cdef-0123-456789abcdef-us-east1.apps.astra.datastax.com`\n",
|
||||
"- Token: `AstraCS:6gBhNmsk135...`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "ca5a2f5d-3ff2-43d6-91c0-4a52c0ecd06a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Please enter your API Endpoint: https://4f835778-ec78-42b0-9ae3-29e3cf45b596-us-east1.apps.astra.datastax.com\n",
|
||||
"Please enter your Token ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"ASTRA_DB_API_ENDPOINT = input(\"Please enter your API Endpoint:\")\n",
|
||||
"ASTRA_DB_APPLICATION_TOKEN = getpass(\"Please enter your Token\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f8c4e5ec-2ab2-4d41-b3ec-c946469fed8b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Instantiate an Astra DB client"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "1b526e55-ad2c-413d-94b1-cf651afefd02",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"astra_db = AstraDB(\n",
|
||||
" api_endpoint=ASTRA_DB_API_ENDPOINT,\n",
|
||||
" token=ASTRA_DB_APPLICATION_TOKEN,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "60829851-bd48-4461-9243-974f76304933",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Create vector collection"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "cbcd19dc-0580-42c2-8d45-1cef52050a59",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The only parameter to specify, other than the collection name, is the dimension of the vectors you'll store. Other parameters, notably the similarity metric to use for searches, are optional."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "8db837dc-cd49-41e2-8b5d-edb17ccc470e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"coll_name = \"philosophers_astra_db\"\n",
|
||||
"collection = astra_db.create_collection(coll_name, dimension=1536)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "da86f91a-88a6-4997-b0f8-9da0816f8ece",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Connect to OpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a6b664b5-fd84-492e-a7bd-4dda3863b48a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Set up your secret key"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "37fe7653-dd64-4494-83e1-5702ec41725c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdin",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Please enter your OpenAI API Key: ········\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"OPENAI_API_KEY = getpass(\"Please enter your OpenAI API Key: \")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "847f2821-7f3f-4dcd-8e0c-49aa397e36f4",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### A test call for embeddings\n",
|
||||
"\n",
|
||||
"Quickly check how one can get the embedding vectors for a list of input texts:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "6bf89454-9a55-4202-ab6b-ea15b2048f3d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"client = openai.OpenAI(api_key=OPENAI_API_KEY)\n",
|
||||
"embedding_model_name = \"text-embedding-ada-002\"\n",
|
||||
"\n",
|
||||
"result = client.embeddings.create(\n",
|
||||
" input=[\n",
|
||||
" \"This is a sentence\",\n",
|
||||
" \"A second sentence\"\n",
|
||||
" ],\n",
|
||||
" model=embedding_model_name,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e2841934-7b2a-4a00-b112-b0865c9ec593",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"_Note: the above is the syntax for OpenAI v1.0+. If using previous versions, the code to get the embeddings will look different._"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "50a8e6f0-0aa7-4ffc-94e9-702b68566815",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"len(result.data) = 2\n",
|
||||
"result.data[1].embedding = [-0.0108176339417696, 0.0013546717818826437, 0.00362232...\n",
|
||||
"len(result.data[1].embedding) = 1536\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(f\"len(result.data) = {len(result.data)}\")\n",
|
||||
"print(f\"result.data[1].embedding = {str(result.data[1].embedding)[:55]}...\")\n",
|
||||
"print(f\"len(result.data[1].embedding) = {len(result.data[1].embedding)}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d7f09c42-fff3-4aa2-922b-043739b4b06a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Load quotes into the Vector Store"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "cf0f3d58-74c2-458b-903d-3d12e61b7846",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Get a dataset with the quotes. _(We adapted and augmented the data from [this Kaggle dataset](https://www.kaggle.com/datasets/mertbozkurt5/quotes-by-philosophers), ready to use in this demo.)_"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "aa68f038-3240-4e22-b7c6-a5f214eda381",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"philo_dataset = load_dataset(\"datastax/philosopher-quotes\")[\"train\"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ab6b08b1-e3db-4c7c-9d7c-2ada7c8bc71d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"A quick inspection:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "10b629cf-efd7-434a-9dc6-7f38f35f7cc8",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"An example entry:\n",
|
||||
"{'author': 'aristotle', 'quote': 'Love well, be loved and do something of value.', 'tags': 'love;ethics'}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(\"An example entry:\")\n",
|
||||
"print(philo_dataset[16])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9badaa4d-80ea-462c-bb00-1909c6435eea",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Check the dataset size:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "1b33ac73-f8f2-4b64-8a27-178ac76886a9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Total: 450 quotes. By author:\n",
|
||||
" aristotle : 50 quotes\n",
|
||||
" schopenhauer : 50 quotes\n",
|
||||
" spinoza : 50 quotes\n",
|
||||
" hegel : 50 quotes\n",
|
||||
" freud : 50 quotes\n",
|
||||
" nietzsche : 50 quotes\n",
|
||||
" sartre : 50 quotes\n",
|
||||
" plato : 50 quotes\n",
|
||||
" kant : 50 quotes\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"author_count = Counter(entry[\"author\"] for entry in philo_dataset)\n",
|
||||
"print(f\"Total: {len(philo_dataset)} quotes. By author:\")\n",
|
||||
"for author, count in author_count.most_common():\n",
|
||||
" print(f\" {author:<20}: {count} quotes\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "062157d1-d262-4735-b06c-f3112575b4cc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Write to the vector collection\n",
|
||||
"\n",
|
||||
"You will compute the embeddings for the quotes and save them into the Vector Store, along with the text itself and the metadata you'll use later.\n",
|
||||
"\n",
|
||||
"To optimize speed and reduce the calls, you'll perform batched calls to the embedding OpenAI service.\n",
|
||||
"\n",
|
||||
"To store the quote objects, you will use the `insert_many` method of the collection (one call per batch). When preparing the documents for insertion you will choose suitable field names -- keep in mind, however, that the embedding vector must be the fixed special `$vector` field."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "6ab84ccb-3363-4bdc-9484-0d68c25a58ff",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Starting to store entries: [20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][20][10]\n",
|
||||
"Finished storing entries.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"BATCH_SIZE = 20\n",
|
||||
"\n",
|
||||
"num_batches = ((len(philo_dataset) + BATCH_SIZE - 1) // BATCH_SIZE)\n",
|
||||
"\n",
|
||||
"quotes_list = philo_dataset[\"quote\"]\n",
|
||||
"authors_list = philo_dataset[\"author\"]\n",
|
||||
"tags_list = philo_dataset[\"tags\"]\n",
|
||||
"\n",
|
||||
"print(\"Starting to store entries: \", end=\"\")\n",
|
||||
"for batch_i in range(num_batches):\n",
|
||||
" b_start = batch_i * BATCH_SIZE\n",
|
||||
" b_end = (batch_i + 1) * BATCH_SIZE\n",
|
||||
" # compute the embedding vectors for this batch\n",
|
||||
" b_emb_results = client.embeddings.create(\n",
|
||||
" input=quotes_list[b_start : b_end],\n",
|
||||
" model=embedding_model_name,\n",
|
||||
" )\n",
|
||||
" # prepare the documents for insertion\n",
|
||||
" b_docs = []\n",
|
||||
" for entry_idx, emb_result in zip(range(b_start, b_end), b_emb_results.data):\n",
|
||||
" if tags_list[entry_idx]:\n",
|
||||
" tags = {\n",
|
||||
" tag: True\n",
|
||||
" for tag in tags_list[entry_idx].split(\";\")\n",
|
||||
" }\n",
|
||||
" else:\n",
|
||||
" tags = {}\n",
|
||||
" b_docs.append({\n",
|
||||
" \"quote\": quotes_list[entry_idx],\n",
|
||||
" \"$vector\": emb_result.embedding,\n",
|
||||
" \"author\": authors_list[entry_idx],\n",
|
||||
" \"tags\": tags,\n",
|
||||
" })\n",
|
||||
" # write to the vector collection\n",
|
||||
" collection.insert_many(b_docs)\n",
|
||||
" print(f\"[{len(b_docs)}]\", end=\"\")\n",
|
||||
"\n",
|
||||
"print(\"\\nFinished storing entries.\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "db3ee629-b6b9-4a77-8c58-c3b93403a6a6",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Use case 1: **quote search engine**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "db3b12b3-2557-4826-af5a-16e6cd9a4531",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"For the quote-search functionality, you need first to make the input quote into a vector, and then use it to query the store (besides handling the optional metadata into the search call, that is).\n",
|
||||
"\n",
|
||||
"Encapsulate the search-engine functionality into a function for ease of re-use. At its core is the `vector_find` method of the collection:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "d6fcf182-3ab7-4d28-9472-dce35cc38182",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def find_quote_and_author(query_quote, n, author=None, tags=None):\n",
|
||||
" query_vector = client.embeddings.create(\n",
|
||||
" input=[query_quote],\n",
|
||||
" model=embedding_model_name,\n",
|
||||
" ).data[0].embedding\n",
|
||||
" filter_clause = {}\n",
|
||||
" if author:\n",
|
||||
" filter_clause[\"author\"] = author\n",
|
||||
" if tags:\n",
|
||||
" filter_clause[\"tags\"] = {}\n",
|
||||
" for tag in tags:\n",
|
||||
" filter_clause[\"tags\"][tag] = True\n",
|
||||
" #\n",
|
||||
" results = collection.vector_find(\n",
|
||||
" query_vector,\n",
|
||||
" limit=n,\n",
|
||||
" filter=filter_clause,\n",
|
||||
" fields=[\"quote\", \"author\"]\n",
|
||||
" )\n",
|
||||
" return [\n",
|
||||
" (result[\"quote\"], result[\"author\"])\n",
|
||||
" for result in results\n",
|
||||
" ]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2539262d-100b-4e8d-864d-e9c612a73e91",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Putting search to test"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3634165c-0882-4281-bc60-ab96261a500d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Passing just a quote:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "6722c2c0-3e54-4738-80ce-4d1149e95414",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[('Life to the great majority is only a constant struggle for mere existence, with the certainty of losing it at last.',\n",
|
||||
" 'schopenhauer'),\n",
|
||||
" ('We give up leisure in order that we may have leisure, just as we go to war in order that we may have peace.',\n",
|
||||
" 'aristotle'),\n",
|
||||
" ('Perhaps the gods are kind to us, by making life more disagreeable as we grow older. In the end death seems less intolerable than the manifold burdens we carry',\n",
|
||||
" 'freud')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"find_quote_and_author(\"We struggle all our life for nothing\", 3)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "50828e4c-9bb5-4489-9fe9-87da5fbe1f18",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Search restricted to an author:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"id": "da9c705f-5c12-42b3-a038-202f89a3c6da",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[('To live is to suffer, to survive is to find some meaning in the suffering.',\n",
|
||||
" 'nietzsche'),\n",
|
||||
" ('What makes us heroic?--Confronting simultaneously our supreme suffering and our supreme hope.',\n",
|
||||
" 'nietzsche')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"find_quote_and_author(\"We struggle all our life for nothing\", 2, author=\"nietzsche\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4a3857ea-6dfe-489a-9b86-4e5e0534960f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Search constrained to a tag (out of those saved earlier with the quotes):"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "abcfaec9-8f42-4789-a5ed-1073fa2932c2",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[('He who seeks equality between unequals seeks an absurdity.', 'spinoza'),\n",
|
||||
" ('The people are that part of the state that does not know what it wants.',\n",
|
||||
" 'hegel')]"
|
||||
]
|
||||
},
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"find_quote_and_author(\"We struggle all our life for nothing\", 2, tags=[\"politics\"])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "746fe38f-139f-44a6-a225-a63e40d3ddf5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Cutting out irrelevant results\n",
|
||||
"\n",
|
||||
"The vector similarity search generally returns the vectors that are closest to the query, even if that means results that might be somewhat irrelevant if there's nothing better.\n",
|
||||
"\n",
|
||||
"To keep this issue under control, you can get the actual \"similarity\" between the query and each result, and then implement a cutoff on it, effectively discarding results that are beyond that threshold.\n",
|
||||
"Tuning this threshold correctly is not an easy problem: here, we'll just show you the way.\n",
|
||||
"\n",
|
||||
"To get a feeling on how this works, try the following query and play with the choice of quote and threshold to compare the results. Note that the similarity is returned as the special `$similarity` field in each result document - and it will be returned by default, unless you pass `include_similarity = False` to the search method.\n",
|
||||
"\n",
|
||||
"_Note (for the mathematically inclined): this value is **a rescaling between zero and one** of the cosine difference between the vectors, i.e. of the scalar product divided by the product of the norms of the two vectors. In other words, this is 0 for opposite-facing vectors and +1 for parallel vectors. For other measures of similarity (cosine is the default), check the `metric` parameter in `AstraDB.create_collection` and the [documentation on allowed values](https://docs.datastax.com/en/astra-serverless/docs/develop/dev-with-json.html#metric-types)._"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "b9b43721-a3b0-4ac4-b730-7a6aeec52e70",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"3 quotes within the threshold:\n",
|
||||
" 0. [similarity=0.927] \"The assumption that animals are without rights, and the illusion that ...\"\n",
|
||||
" 1. [similarity=0.922] \"Animals are in possession of themselves; their soul is in possession o...\"\n",
|
||||
" 2. [similarity=0.920] \"At his best, man is the noblest of all animals; separated from law and...\"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"quote = \"Animals are our equals.\"\n",
|
||||
"# quote = \"Be good.\"\n",
|
||||
"# quote = \"This teapot is strange.\"\n",
|
||||
"\n",
|
||||
"metric_threshold = 0.92\n",
|
||||
"\n",
|
||||
"quote_vector = client.embeddings.create(\n",
|
||||
" input=[quote],\n",
|
||||
" model=embedding_model_name,\n",
|
||||
").data[0].embedding\n",
|
||||
"\n",
|
||||
"results_full = collection.vector_find(\n",
|
||||
" quote_vector,\n",
|
||||
" limit=8,\n",
|
||||
" fields=[\"quote\"]\n",
|
||||
")\n",
|
||||
"results = [res for res in results_full if res[\"$similarity\"] >= metric_threshold]\n",
|
||||
"\n",
|
||||
"print(f\"{len(results)} quotes within the threshold:\")\n",
|
||||
"for idx, result in enumerate(results):\n",
|
||||
" print(f\" {idx}. [similarity={result['$similarity']:.3f}] \\\"{result['quote'][:70]}...\\\"\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "71871251-169f-4d3f-a687-65f836a9a8fe",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Use case 2: **quote generator**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b0a9cd63-a131-4819-bf41-c8ffa0b1e1ca",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"For this task you need another component from OpenAI, namely an LLM to generate the quote for us (based on input obtained by querying the Vector Store).\n",
|
||||
"\n",
|
||||
"You also need a template for the prompt that will be filled for the generate-quote LLM completion task."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "a6dd366d-665a-45fd-917b-b6b5312b0865",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"completion_model_name = \"gpt-3.5-turbo\"\n",
|
||||
"\n",
|
||||
"generation_prompt_template = \"\"\"\"Generate a single short philosophical quote on the given topic,\n",
|
||||
"similar in spirit and form to the provided actual example quotes.\n",
|
||||
"Do not exceed 20-30 words in your quote.\n",
|
||||
"\n",
|
||||
"REFERENCE TOPIC: \"{topic}\"\n",
|
||||
"\n",
|
||||
"ACTUAL EXAMPLES:\n",
|
||||
"{examples}\n",
|
||||
"\"\"\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "53073a9e-16de-4e49-9e97-ff31b9b250c2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Like for search, this functionality is best wrapped into a handy function (which internally uses search):"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "397e6ebd-b30e-413b-be63-81a62947a7b8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def generate_quote(topic, n=2, author=None, tags=None):\n",
|
||||
" quotes = find_quote_and_author(query_quote=topic, n=n, author=author, tags=tags)\n",
|
||||
" if quotes:\n",
|
||||
" prompt = generation_prompt_template.format(\n",
|
||||
" topic=topic,\n",
|
||||
" examples=\"\\n\".join(f\" - {quote[0]}\" for quote in quotes),\n",
|
||||
" )\n",
|
||||
" # a little logging:\n",
|
||||
" print(\"** quotes found:\")\n",
|
||||
" for q, a in quotes:\n",
|
||||
" print(f\"** - {q} ({a})\")\n",
|
||||
" print(\"** end of logging\")\n",
|
||||
" #\n",
|
||||
" response = client.chat.completions.create(\n",
|
||||
" model=completion_model_name,\n",
|
||||
" messages=[{\"role\": \"user\", \"content\": prompt}],\n",
|
||||
" temperature=0.7,\n",
|
||||
" max_tokens=320,\n",
|
||||
" )\n",
|
||||
" return response.choices[0].message.content.replace('\"', '').strip()\n",
|
||||
" else:\n",
|
||||
" print(\"** no quotes found.\")\n",
|
||||
" return None"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c13f8488-899b-4d4c-a069-73643a778200",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"_Note: similar to the case of the embedding computation, the code for the Chat Completion API would be slightly different for OpenAI prior to v1.0._"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "63bcc157-e5d4-43ef-8028-d4dcc8a72b9c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"#### Putting quote generation to test"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "fe6b3f38-089d-486d-b32c-e665c725faa8",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Just passing a text (a \"quote\", but one can actually just suggest a topic since its vector embedding will still end up at the right place in the vector space):"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"id": "806ba758-8988-410e-9eeb-b9c6799e6b25",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"** quotes found:\n",
|
||||
"** - Happiness is the reward of virtue. (aristotle)\n",
|
||||
"** - Our moral virtues benefit mainly other people; intellectual virtues, on the other hand, benefit primarily ourselves; therefore the former make us universally popular, the latter unpopular. (schopenhauer)\n",
|
||||
"** end of logging\n",
|
||||
"\n",
|
||||
"A new generated quote:\n",
|
||||
"True politics lies in the virtuous pursuit of justice, for it is through virtue that we build a better world for all.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"q_topic = generate_quote(\"politics and virtue\")\n",
|
||||
"print(\"\\nA new generated quote:\")\n",
|
||||
"print(q_topic)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ca032d30-4538-4d0b-aea1-731fb32d2d4b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Use inspiration from just a single philosopher:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"id": "7c2e2d4e-865f-4b2d-80cd-a695271415d9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"** quotes found:\n",
|
||||
"** - Because Christian morality leaves animals out of account, they are at once outlawed in philosophical morals; they are mere 'things,' mere means to any ends whatsoever. They can therefore be used for vivisection, hunting, coursing, bullfights, and horse racing, and can be whipped to death as they struggle along with heavy carts of stone. Shame on such a morality that is worthy of pariahs, and that fails to recognize the eternal essence that exists in every living thing, and shines forth with inscrutable significance from all eyes that see the sun! (schopenhauer)\n",
|
||||
"** - The assumption that animals are without rights, and the illusion that our treatment of them has no moral significance, is a positively outrageous example of Western crudity and barbarity. Universal compassion is the only guarantee of morality. (schopenhauer)\n",
|
||||
"** end of logging\n",
|
||||
"\n",
|
||||
"A new generated quote:\n",
|
||||
"Excluding animals from ethical consideration reveals a moral blindness that allows for their exploitation and suffering. True morality embraces universal compassion.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"q_topic = generate_quote(\"animals\", author=\"schopenhauer\")\n",
|
||||
"print(\"\\nA new generated quote:\")\n",
|
||||
"print(q_topic)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4bd8368a-9e23-49a5-8694-921728ea9656",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Cleanup\n",
|
||||
"\n",
|
||||
"If you want to remove all resources used for this demo, run this cell (_warning: this will irreversibly delete the collection and its data!_):"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"id": "1eb0fd16-7e15-4742-8fc5-94d9eeeda620",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'status': {'ok': 1}}"
|
||||
]
|
||||
},
|
||||
"execution_count": 22,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"astra_db.delete_collection(coll_name)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.18"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
Loading…
Reference in New Issue