**Description:** This is like the rag-conversation template in many ways. What's different is: - support for a timescale vector store. - support for time-based filters. - support for metadata filters. <!-- Thank you for contributing to LangChain! Replace this entire comment with: - **Description:** a description of the change, - **Issue:** the issue # it fixes (if applicable), - **Dependencies:** any dependencies required for this change, - **Tag maintainer:** for a quicker response, tag the relevant maintainer (see below), - **Twitter handle:** we announce bigger features on Twitter. If your PR gets announced, and you'd like a mention, we'll gladly shout you out! Please make sure your PR is passing linting and testing before submitting. Run `make format`, `make lint` and `make test` to check this locally. See contribution guidelines for more information on how to write/run tests, lint, etc: https://github.com/langchain-ai/langchain/blob/master/.github/CONTRIBUTING.md If you're adding a new integration, please include: 1. a test for the integration, preferably unit tests that do not rely on network access, 2. an example notebook showing its use. It lives in `docs/extras` directory. If no one reviews your PR within a few days, please @-mention one of @baskaryan, @eyurtsev, @hwchase17. --> --------- Co-authored-by: Erick Friis <erick@langchain.dev> |
||
|---|---|---|
| .. | ||
| anthropic-iterative-search | ||
| basic-critique-revise | ||
| cassandra-entomology-rag | ||
| cassandra-synonym-caching | ||
| chat-bot-feedback | ||
| csv-agent | ||
| docs | ||
| elastic-query-generator | ||
| extraction-anthropic-functions | ||
| extraction-openai-functions | ||
| guardrails-output-parser | ||
| hybrid-search-weaviate | ||
| hyde | ||
| llama2-functions | ||
| mongo-parent-document-retrieval | ||
| neo4j-advanced-rag | ||
| neo4j-cypher | ||
| neo4j-cypher-ft | ||
| neo4j-cypher-memory | ||
| neo4j-generation | ||
| neo4j-parent | ||
| neo4j-vector-memory | ||
| openai-functions-agent | ||
| openai-functions-tool-retrieval-agent | ||
| pii-protected-chatbot | ||
| pirate-speak | ||
| pirate-speak-configurable | ||
| plate-chain | ||
| rag-astradb | ||
| rag-aws-bedrock | ||
| rag-aws-kendra | ||
| rag-chroma | ||
| rag-chroma-private | ||
| rag-codellama-fireworks | ||
| rag-conversation | ||
| rag-conversation-zep | ||
| rag-elasticsearch | ||
| rag-fusion | ||
| rag-matching-engine | ||
| rag-momento-vector-index | ||
| rag-mongo | ||
| rag-pinecone | ||
| rag-pinecone-multi-query | ||
| rag-pinecone-rerank | ||
| rag-redis | ||
| rag-semi-structured | ||
| rag-singlestoredb | ||
| rag-supabase | ||
| rag-timescale-conversation | ||
| rag-timescale-hybrid-search-time | ||
| rag-vectara | ||
| rag-vectara-multiquery | ||
| rag-weaviate | ||
| rewrite-retrieve-read | ||
| self-query-qdrant | ||
| self-query-supabase | ||
| solo-performance-prompting-agent | ||
| sql-llama2 | ||
| sql-llamacpp | ||
| sql-ollama | ||
| stepback-qa-prompting | ||
| summarize-anthropic | ||
| xml-agent | ||
| .gitignore | ||
| Makefile | ||
| poetry.lock | ||
| pyproject.toml | ||
| README.md | ||
LangChain Templates
LangChain Templates are the easiest and fastest way to build a production-ready LLM application. These templates serve as a set of reference architectures for a wide variety of popular LLM use cases. They are all in a standard format which make it easy to deploy them with LangServe.
🚩 We will be releasing a hosted version of LangServe for one-click deployments of LangChain applications. Sign up here to get on the waitlist.
Quick Start
To use, first install the LangChain CLI.
pip install -U langchain-cli
Next, create a new LangChain project:
langchain app new my-app
This will create a new directory called my-app with two folders:
app: This is where LangServe code will livepackages: This is where your chains or agents will live
To pull in an existing template as a package, you first need to go into your new project:
cd my-app
And you can the add a template as a project.
In this getting started guide, we will add a simple pirate-speak project.
All this project does is convert user input into pirate speak.
langchain app add pirate-speak
This will pull in the specified template into packages/pirate-speak
You will then be prompted if you want to install it.
This is the equivalent of running pip install -e packages/pirate-speak.
You should generally accept this (or run that same command afterwards).
We install it with -e so that if you modify the template at all (which you likely will) the changes are updated.
After that, it will ask you if you want to generate route code for this project. This is code you need to add to your app to start using this chain. If we accept, we will see the following code generated:
from pirate_speak.chain import chain as pirate_speak_chain
add_routes(app, pirate_speak_chain, path="/pirate-speak")
You can now edit the template you pulled down.
You can change the code files in package/pirate-speak to use a different model, different prompt, different logic.
Note that the above code snippet always expects the final chain to be importable as from pirate_speak.chain import chain,
so you should either keep the structure of the package similar enough to respect that or be prepared to update that code snippet.
Once you have done as much of that as you want, it is
In order to have LangServe use this project, you then need to modify app/server.py.
Specifically, you should add the above code snippet to app/server.py so that file looks like:
from fastapi import FastAPI
from langserve import add_routes
from pirate_speak.chain import chain as pirate_speak_chain
app = FastAPI()
add_routes(app, pirate_speak_chain, path="/pirate-speak")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. LangSmith is currently in private beta, you can sign up here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
For this particular application, we will use OpenAI as the LLM, so we need to export our OpenAI API key:
export OPENAI_API_KEY=sk-...
You can then spin up production-ready endpoints, along with a playground, by running:
langchain serve
This now gives a fully deployed LangServe application. For example, you get a playground out-of-the-box at http://127.0.0.1:8000/pirate-speak/playground/:
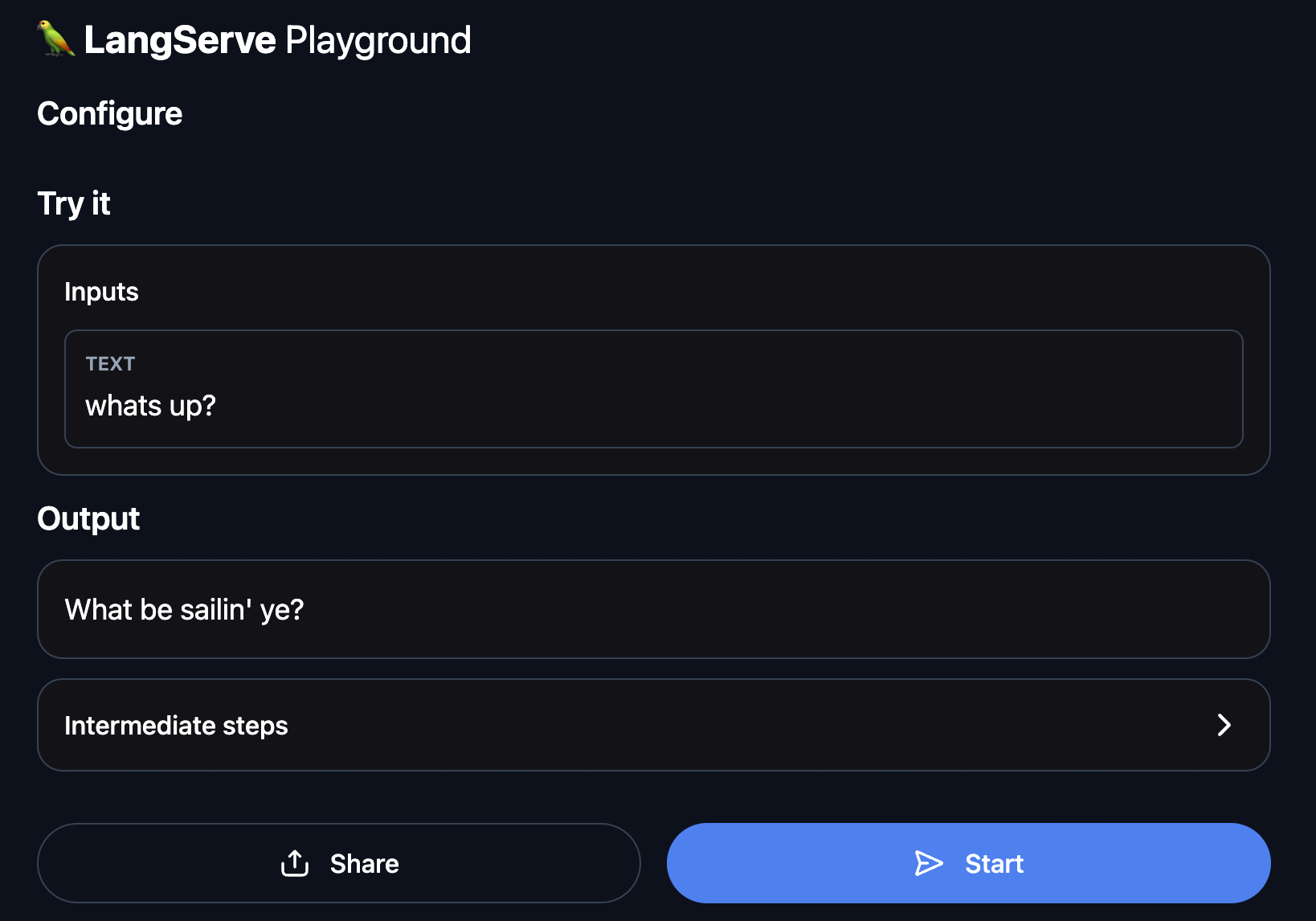
Access API documentation at http://127.0.0.1:8000/docs
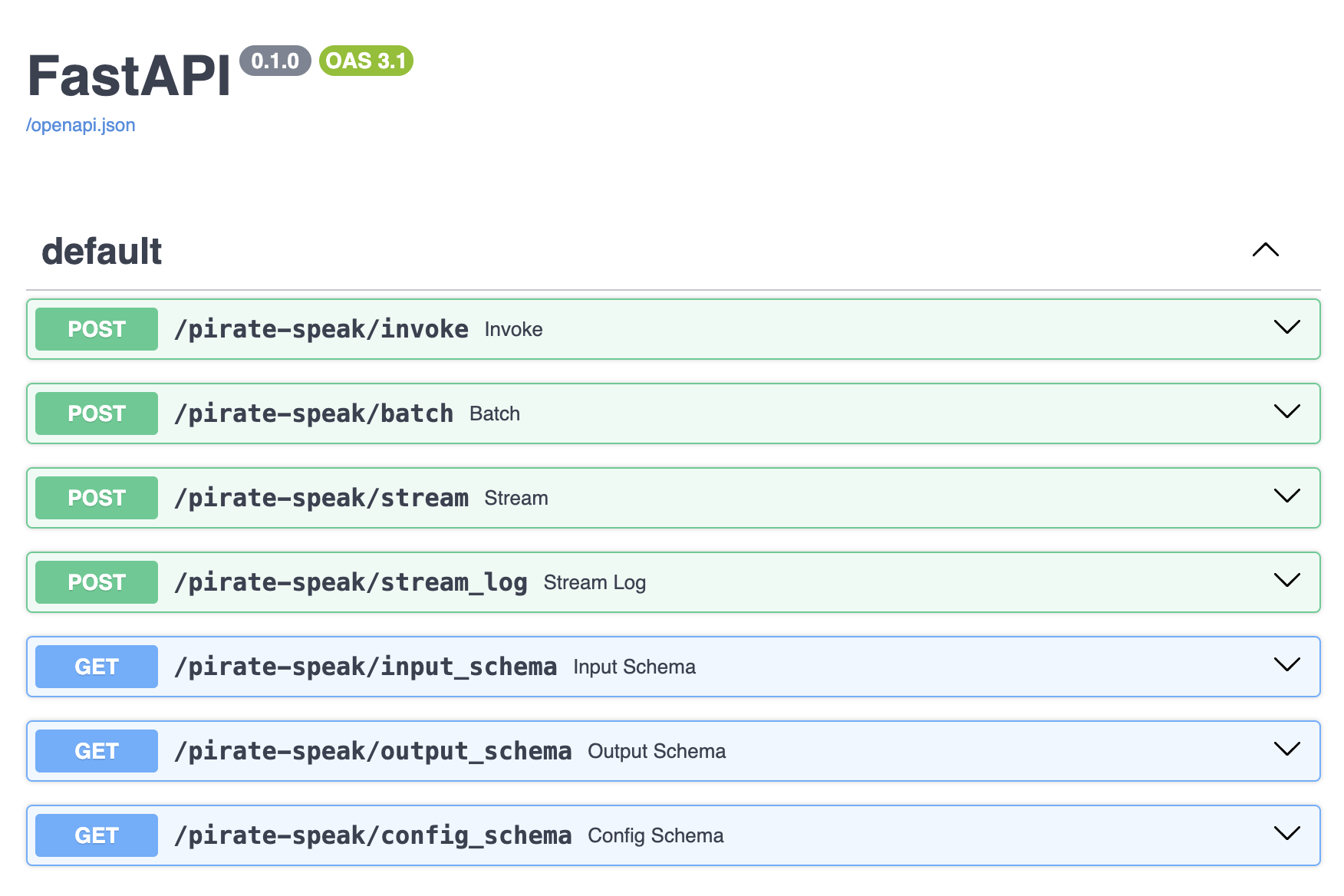
Use the LangServe python or js SDK to interact with the API as if it were a regular Runnable.
from langserve import RemoteRunnable
api = RemoteRunnable("http://127.0.0.1:8000/pirate-speak")
api.invoke({"text": "hi"})
That's it for the quick start! You have successfully downloaded your first template and deployed it with LangServe.
Additional Resources
Index of Templates
Explore the many templates available to use - from advanced RAG to agents.
Contributing
Want to contribute your own template? It's pretty easy! These instructions walk through how to do that.
Launching LangServe from a Package
You can also launch LangServe from a package directly (without having to create a new project). These instructions cover how to do that.