 woo! Co-authored-by: Harrison Chase <hw.chase.17@gmail.com> |
||
|---|---|---|
| .github/workflows | ||
| docs | ||
| examples | ||
| langchain | ||
| tests | ||
| .flake8 | ||
| .gitignore | ||
| LICENSE | ||
| Makefile | ||
| MANIFEST.in | ||
| pyproject.toml | ||
| README.md | ||
| readthedocs.yml | ||
| requirements.txt | ||
| setup.py | ||
| test_requirements.txt | ||
{kind=link}
🦜️🔗 LangChain
⚡ Building applications with LLMs through composability ⚡
![]()
![]()
![]()

Quick Install
pip install langchain
🤔 What is this?
Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. But using these LLMs in isolation is often not enough to create a truly powerful app - the real power comes when you are able to combine them with other sources of computation or knowledge.
This library is aimed at assisting in the development of those types of applications. It aims to create:
- a comprehensive collection of pieces you would ever want to combine
- a flexible interface for combining pieces into a single comprehensive "chain"
- a schema for easily saving and sharing those chains
🔧 Setting up your environment
Besides the installation of this python package, you will also need to install packages and set environment variables depending on which chains you want to use.
Note: the reason these packages are not included in the dependencies by default is that as we imagine scaling this package, we do not want to force dependencies that are not needed.
The following use cases require specific installs and api keys:
- OpenAI:
- Install requirements with
pip install openai - Get an OpenAI api key and either set it as an environment variable (
OPENAI_API_KEY) or pass it to the LLM constructor asopenai_api_key.
- Install requirements with
- Cohere:
- Install requirements with
pip install cohere - Get a Cohere api key and either set it as an environment variable (
COHERE_API_KEY) or pass it to the LLM constructor ascohere_api_key.
- Install requirements with
- HuggingFace Hub
- Install requirements with
pip install huggingface_hub - Get a HuggingFace Hub api token and either set it as an environment variable (
HUGGINGFACEHUB_API_TOKEN) or pass it to the LLM constructor ashuggingfacehub_api_token.
- Install requirements with
- SerpAPI:
- Install requirements with
pip install google-search-results - Get a SerpAPI api key and either set it as an environment variable (
SERPAPI_API_KEY) or pass it to the LLM constructor asserpapi_api_key.
- Install requirements with
- NatBot:
- Install requirements with
pip install playwright
- Install requirements with
- Wikipedia:
- Install requirements with
pip install wikipedia
- Install requirements with
- Elasticsearch:
- Install requirements with
pip install elasticsearch - Set up Elasticsearch backend. If you want to do locally, this is a good guide.
- Install requirements with
- FAISS:
- Install requirements with
pip install faissfor Python 3.7 andpip install faiss-cpufor Python 3.10+.
- Install requirements with
🚀 What can I do with this
This project was largely inspired by a few projects seen on Twitter for which we thought it would make sense to have more explicit tooling. A lot of the initial functionality was done in an attempt to recreate those. Those are:
To recreate this paper, use the following code snippet or checkout the example notebook.
from langchain import SelfAskWithSearchChain, OpenAI, SerpAPIChain
llm = OpenAI(temperature=0)
search = SerpAPIChain()
self_ask_with_search = SelfAskWithSearchChain(llm=llm, search_chain=search)
self_ask_with_search.run("What is the hometown of the reigning men's U.S. Open champion?")
To recreate this example, use the following code snippet or check out the example notebook.
from langchain import OpenAI, LLMMathChain
llm = OpenAI(temperature=0)
llm_math = LLMMathChain(llm=llm)
llm_math.run("How many of the integers between 0 and 99 inclusive are divisible by 8?")
Generic Prompting
You can also use this for simple prompting pipelines, as in the below example and this example notebook.
from langchain import Prompt, OpenAI, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = Prompt(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=OpenAI(temperature=0))
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
llm_chain.predict(question=question)
Embed & Search Documents
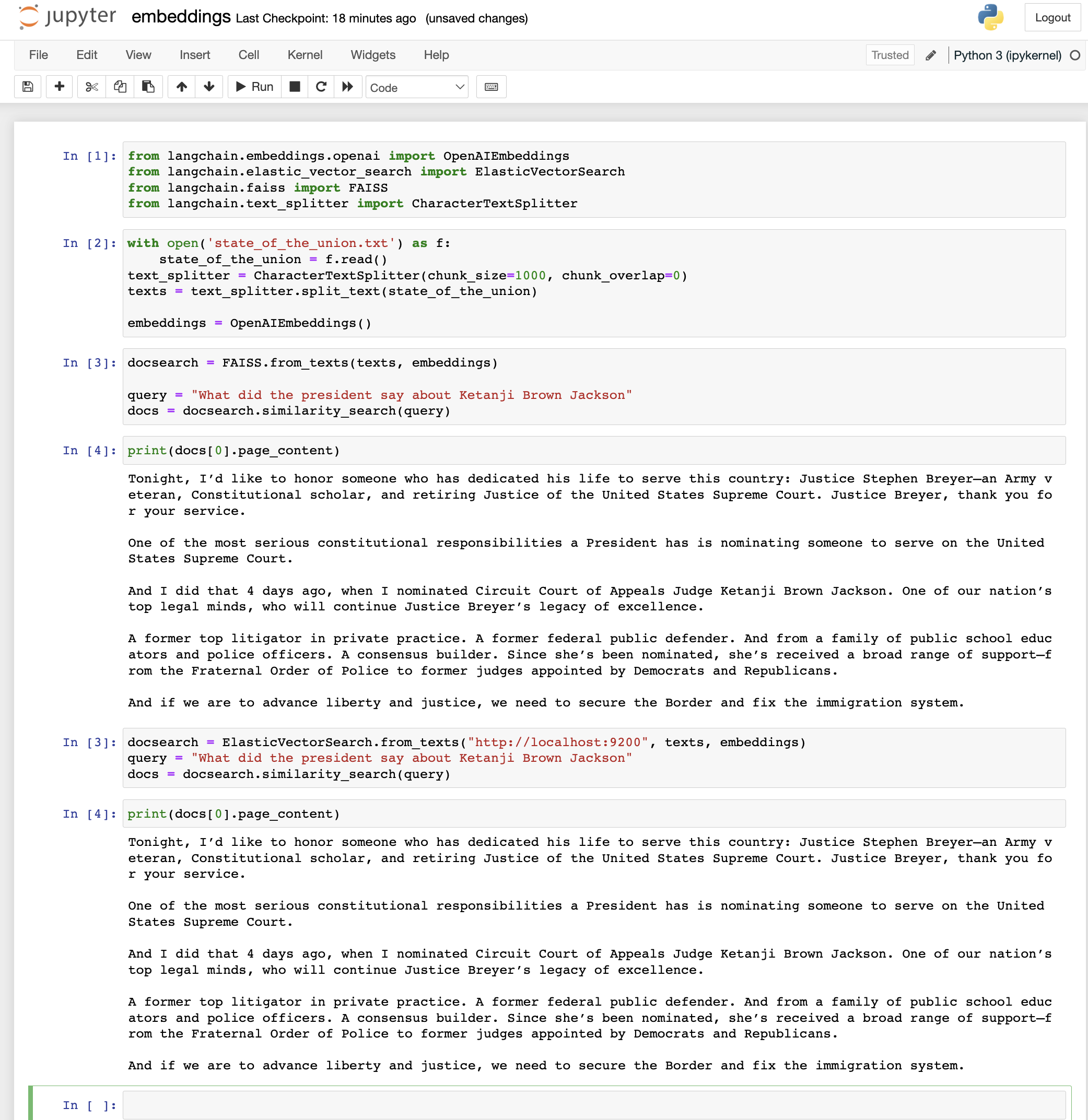
We support two vector databases to store and search embeddings -- FAISS and Elasticsearch. Here's a code snippet showing how to use FAISS to store embeddings and search for text similar to a query. Both database backends are featured in this [example notebook] (https://github.com/hwchase17/langchain/blob/master/notebooks/examples/embeddings.ipynb).
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.faiss import FAISS
from langchain.text_splitter import CharacterTextSplitter
with open('state_of_the_union.txt') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = FAISS.from_texts(texts, embeddings)
query = "What did the president say about Ketanji Brown Jackson"
docs = docsearch.similarity_search(query)
📖 Documentation
The above examples are probably the most user friendly documentation that exists, but full API docs can be found here.
🤖 Developer Guide
To begin developing on this project, first clone to the repo locally.
To install requirements, run pip install -r requirements.txt.
This will install all requirements for running the package, examples, linting, formatting, and tests.
Formatting for this project is a combination of Black and isort.
To run formatting for this project, run make format.
Linting for this project is a combination of Black, isort, flake8, and mypy.
To run linting for this project, run make lint.
We recognize linting can be annoying - if you do not want to do it, please contact a project maintainer and they can help you with it. We do not want this to be a blocker for good code getting contributed.
Unit tests cover modular logic that does not require calls to outside apis.
To run unit tests, run make tests.
If you add new logic, please add a unit test.
Integration tests cover logic that requires making calls to outside APIs (often integration with other services).
To run integration tests, run make integration_tests.
If you add support for a new external API, please add a new integration test.
If you are adding a Jupyter notebook example, you can run pip install -e . to build the langchain package from your local changes, so your new logic can be imported into the notebook.
Docs are largely autogenerated by sphinx from the code. For that reason, we ask that you add good documentation to all classes and methods. Similar to linting, we recognize documentation can be annoying - if you do not want to do it, please contact a project maintainer and they can help you with it. We do not want this to be a blocker for good code getting contributed.