Update imports to use core for the low-hanging fruit changes. Ran
following
```bash
git grep -l 'langchain.schema.runnable' {docs,templates,cookbook} | xargs sed -i '' 's/langchain\.schema\.runnable/langchain_core.runnables/g'
git grep -l 'langchain.schema.output_parser' {docs,templates,cookbook} | xargs sed -i '' 's/langchain\.schema\.output_parser/langchain_core.output_parsers/g'
git grep -l 'langchain.schema.messages' {docs,templates,cookbook} | xargs sed -i '' 's/langchain\.schema\.messages/langchain_core.messages/g'
git grep -l 'langchain.schema.chat_histry' {docs,templates,cookbook} | xargs sed -i '' 's/langchain\.schema\.chat_history/langchain_core.chat_history/g'
git grep -l 'langchain.schema.prompt_template' {docs,templates,cookbook} | xargs sed -i '' 's/langchain\.schema\.prompt_template/langchain_core.prompts/g'
git grep -l 'from langchain.pydantic_v1' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.pydantic_v1/from langchain_core.pydantic_v1/g'
git grep -l 'from langchain.tools.base' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.tools\.base/from langchain_core.tools/g'
git grep -l 'from langchain.chat_models.base' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.chat_models.base/from langchain_core.language_models.chat_models/g'
git grep -l 'from langchain.llms.base' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.llms\.base\ /from langchain_core.language_models.llms\ /g'
git grep -l 'from langchain.embeddings.base' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.embeddings\.base/from langchain_core.embeddings/g'
git grep -l 'from langchain.vectorstores.base' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.vectorstores\.base/from langchain_core.vectorstores/g'
git grep -l 'from langchain.agents.tools' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.agents\.tools/from langchain_core.tools/g'
git grep -l 'from langchain.schema.output' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.schema\.output\ /from langchain_core.outputs\ /g'
git grep -l 'from langchain.schema.embeddings' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.schema\.embeddings/from langchain_core.embeddings/g'
git grep -l 'from langchain.schema.document' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.schema\.document/from langchain_core.documents/g'
git grep -l 'from langchain.schema.agent' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.schema\.agent/from langchain_core.agents/g'
git grep -l 'from langchain.schema.prompt ' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.schema\.prompt\ /from langchain_core.prompt_values /g'
git grep -l 'from langchain.schema.language_model' {docs,templates,cookbook} | xargs sed -i '' 's/from langchain\.schema\.language_model/from langchain_core.language_models/g'
```
|
||
|---|---|---|
| .. | ||
| _images | ||
| rag_mongo | ||
| tests | ||
| ingest.py | ||
| LICENSE | ||
| poetry.lock | ||
| pyproject.toml | ||
| rag_mongo.ipynb | ||
| README.md | ||
rag-mongo
This template performs RAG using MongoDB and OpenAI.
Environment Setup
You should export two environment variables, one being your MongoDB URI, the other being your OpenAI API KEY.
If you do not have a MongoDB URI, see the Setup Mongo section at the bottom for instructions on how to do so.
export MONGO_URI=...
export OPENAI_API_KEY=...
Usage
To use this package, you should first have the LangChain CLI installed:
pip install -U langchain-cli
To create a new LangChain project and install this as the only package, you can do:
langchain app new my-app --package rag-mongo
If you want to add this to an existing project, you can just run:
langchain app add rag-mongo
And add the following code to your server.py file:
from rag_mongo import chain as rag_mongo_chain
add_routes(app, rag_mongo_chain, path="/rag-mongo")
If you want to set up an ingestion pipeline, you can add the following code to your server.py file:
from rag_mongo import ingest as rag_mongo_ingest
add_routes(app, rag_mongo_ingest, path="/rag-mongo-ingest")
(Optional) Let's now configure LangSmith. LangSmith will help us trace, monitor and debug LangChain applications. LangSmith is currently in private beta, you can sign up here. If you don't have access, you can skip this section
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
If you DO NOT already have a Mongo Search Index you want to connect to, see MongoDB Setup section below before proceeding.
If you DO have a MongoDB Search index you want to connect to, edit the connection details in rag_mongo/chain.py
If you are inside this directory, then you can spin up a LangServe instance directly by:
langchain serve
This will start the FastAPI app with a server is running locally at http://localhost:8000
We can see all templates at http://127.0.0.1:8000/docs We can access the playground at http://127.0.0.1:8000/rag-mongo/playground
We can access the template from code with:
from langserve.client import RemoteRunnable
runnable = RemoteRunnable("http://localhost:8000/rag-mongo")
For additional context, please refer to this notebook.
MongoDB Setup
Use this step if you need to setup your MongoDB account and ingest data. We will first follow the standard MongoDB Atlas setup instructions here.
- Create an account (if not already done)
- Create a new project (if not already done)
- Locate your MongoDB URI.
This can be done by going to the deployement overview page and connecting to you database
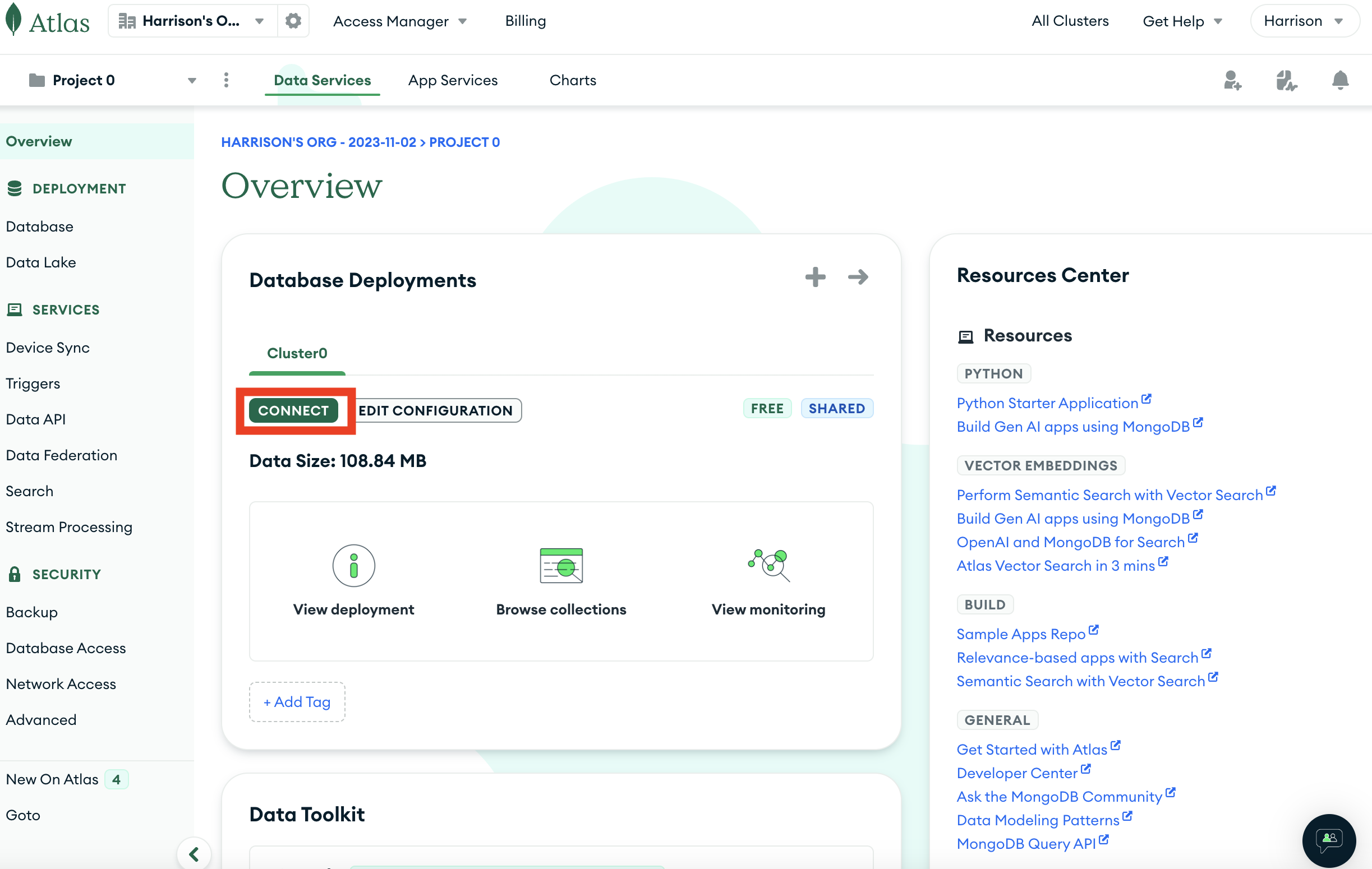
We then look at the drivers available
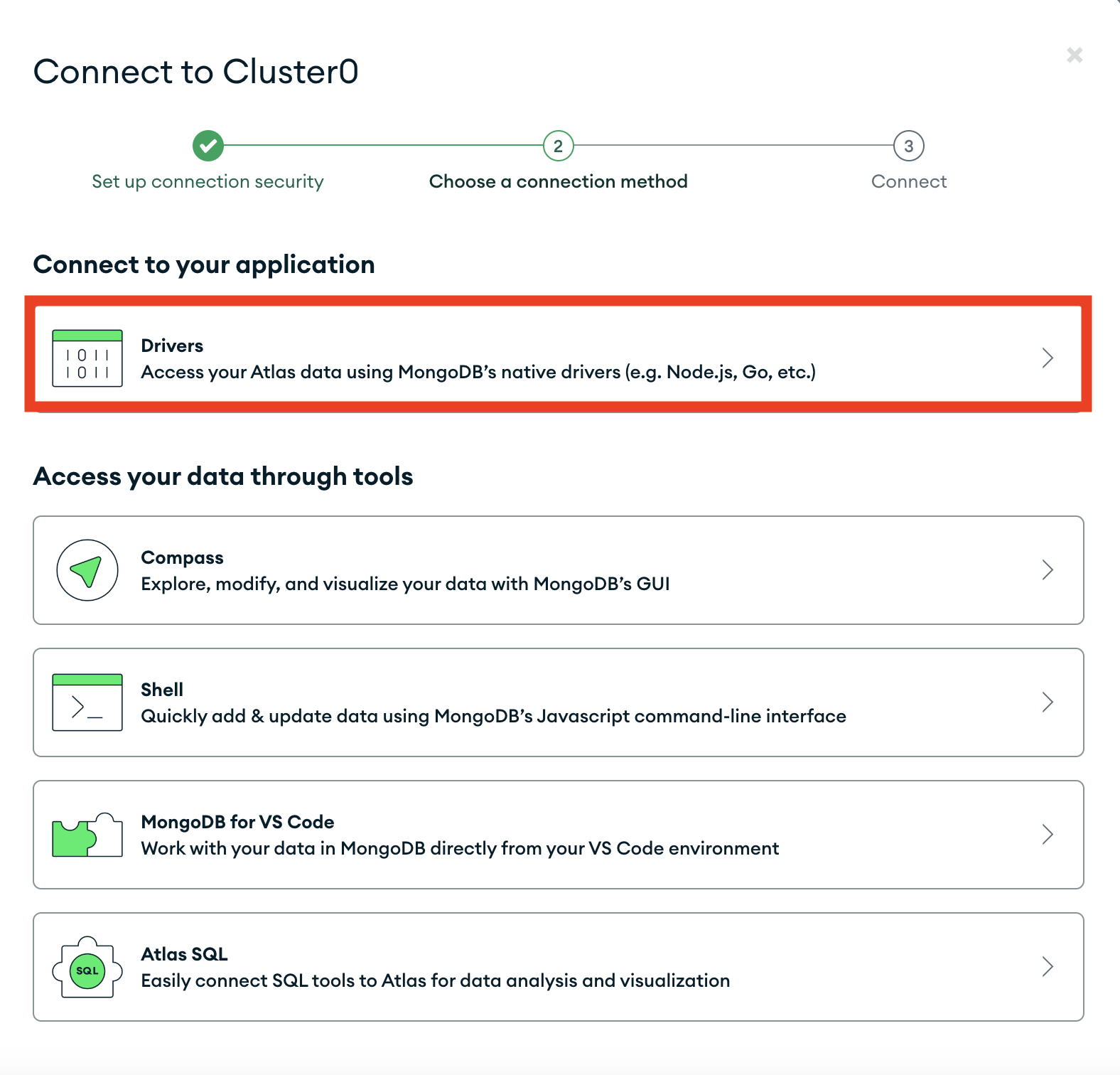
Among which we will see our URI listed
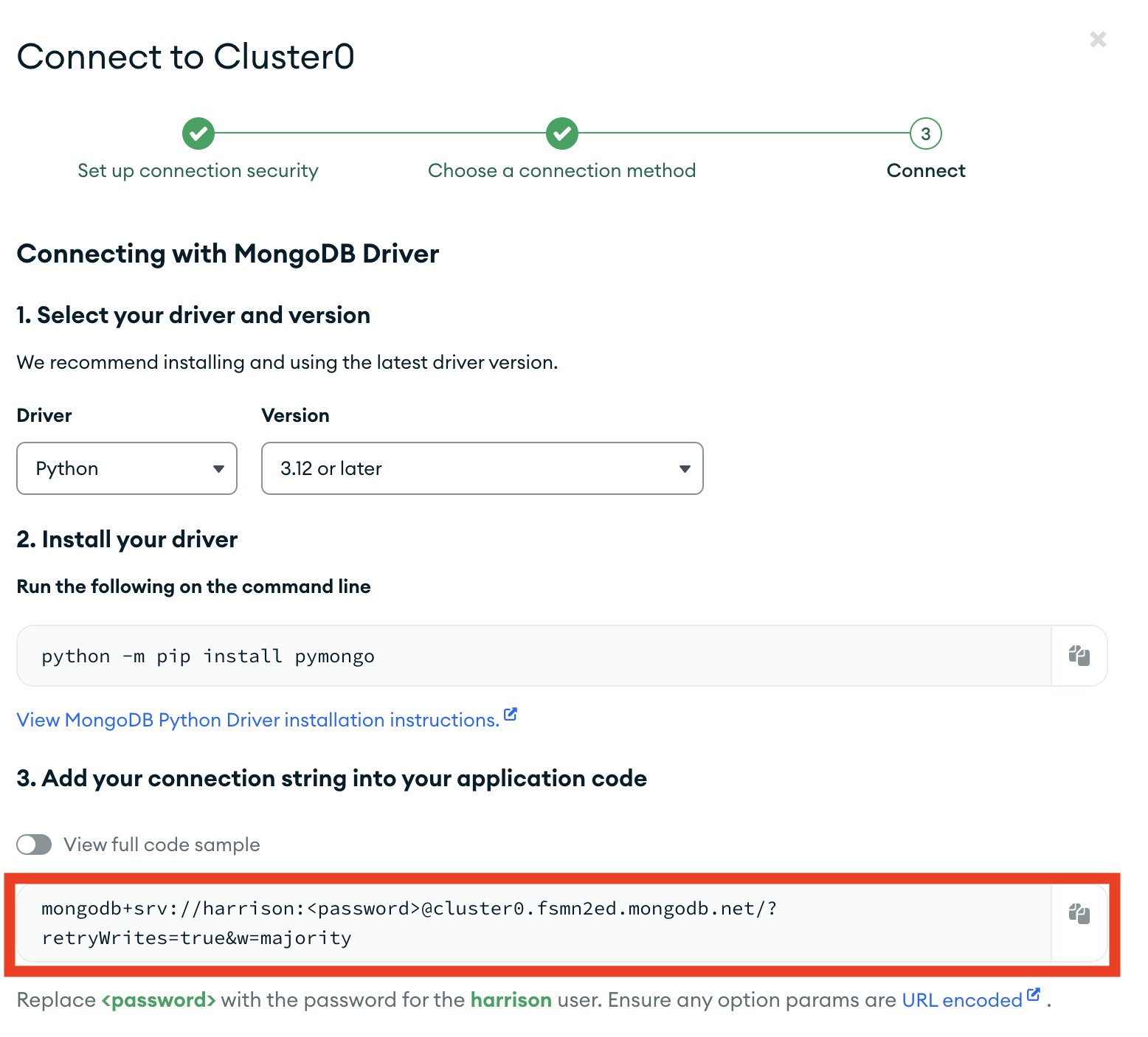
Let's then set that as an environment variable locally:
export MONGO_URI=...
- Let's also set an environment variable for OpenAI (which we will use as an LLM)
export OPENAI_API_KEY=...
- Let's now ingest some data! We can do that by moving into this directory and running the code in
ingest.py, eg:
python ingest.py
Note that you can (and should!) change this to ingest data of your choice
- We now need to set up a vector index on our data.
We can first connect to the cluster where our database lives
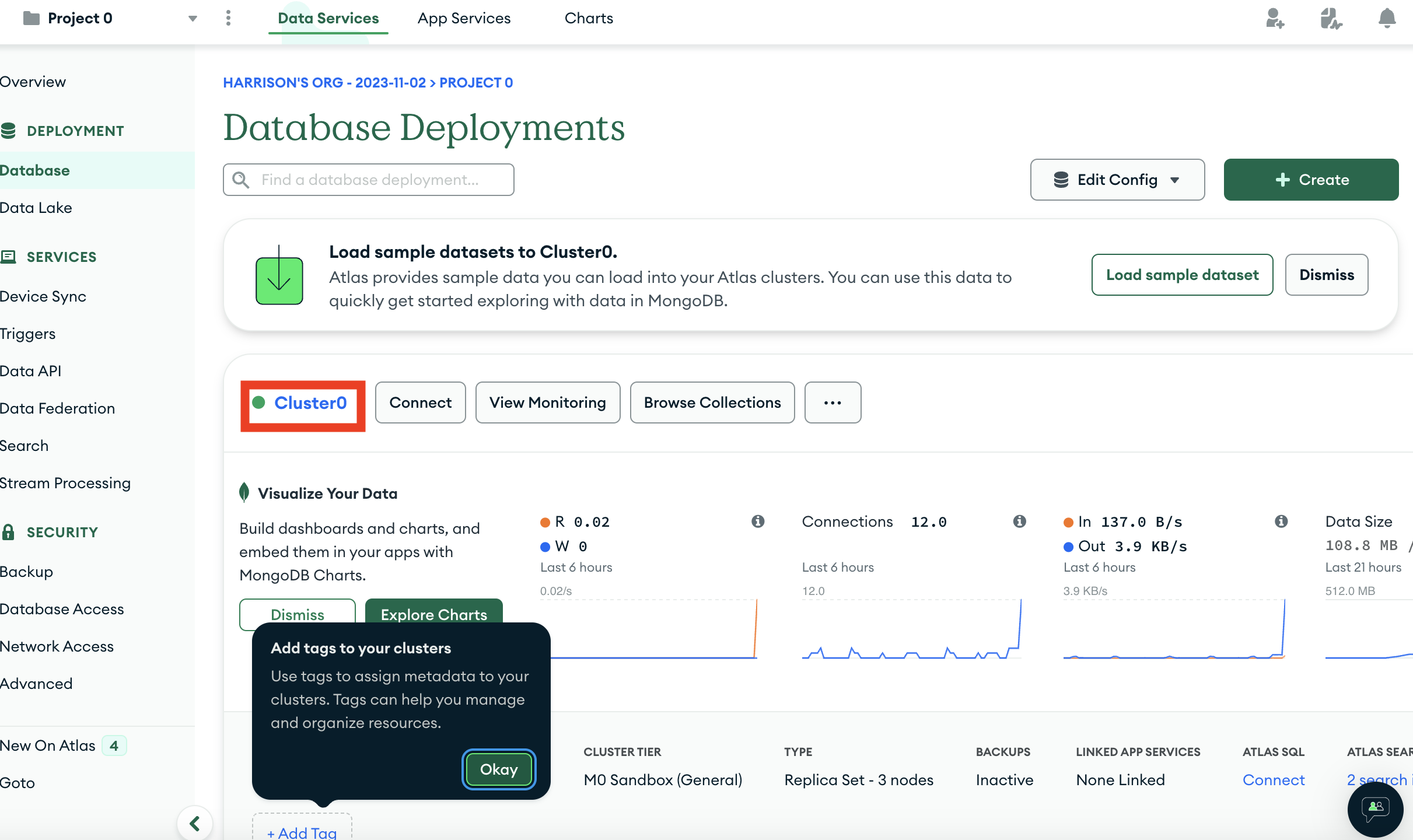
We can then navigate to where all our collections are listed
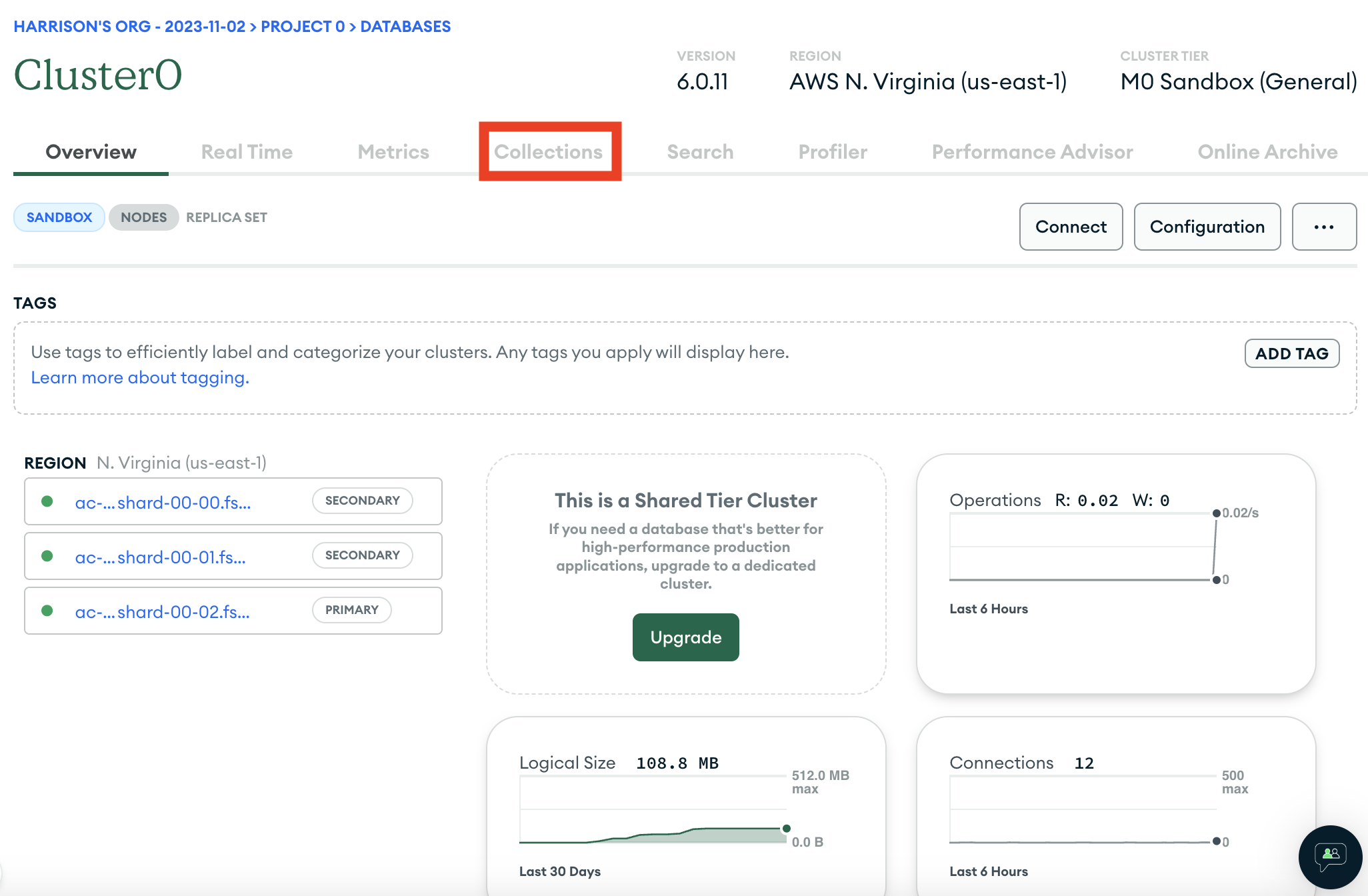
We can then find the collection we want and look at the search indexes for that collection
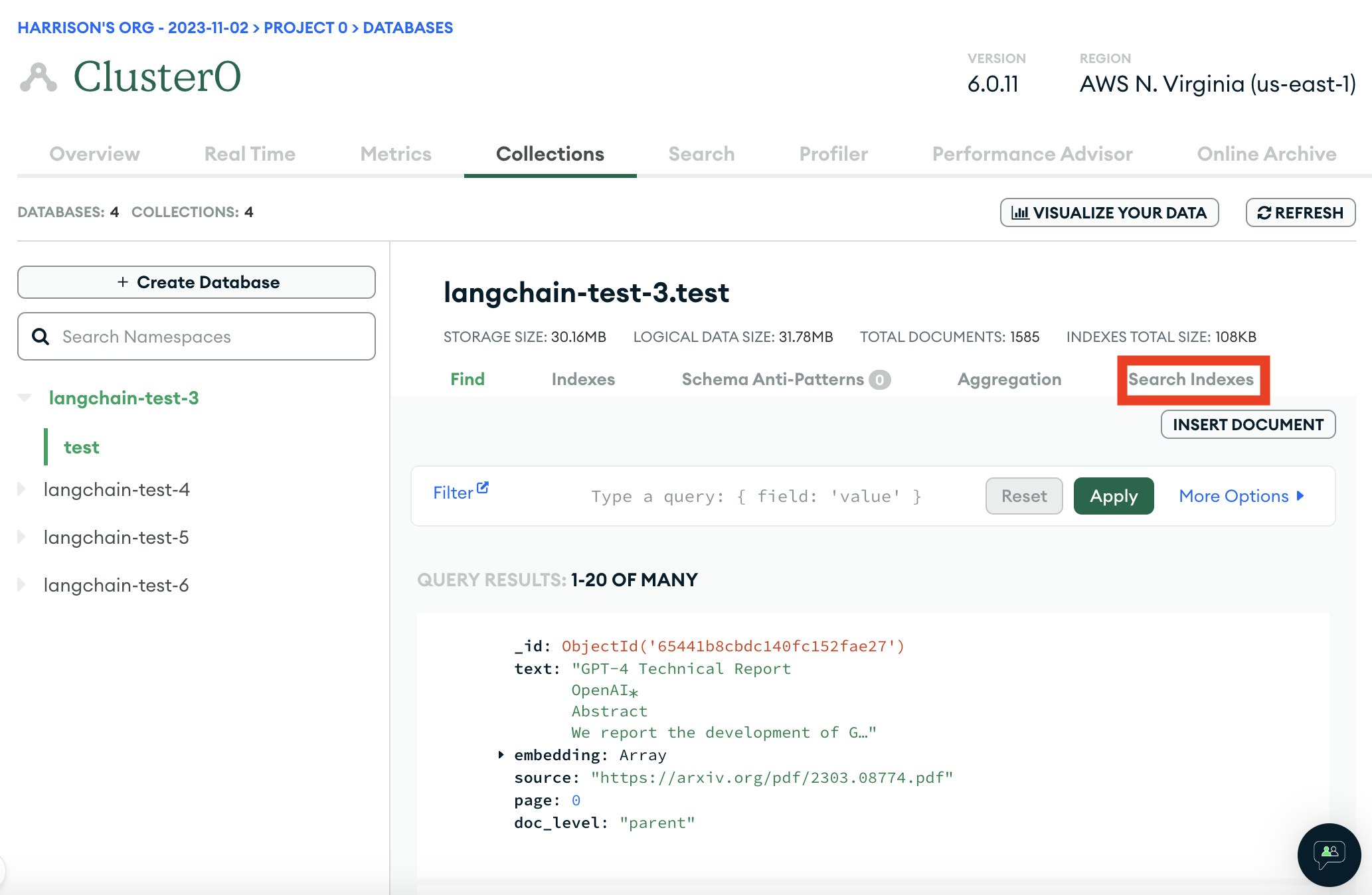
That should likely be empty, and we want to create a new one:
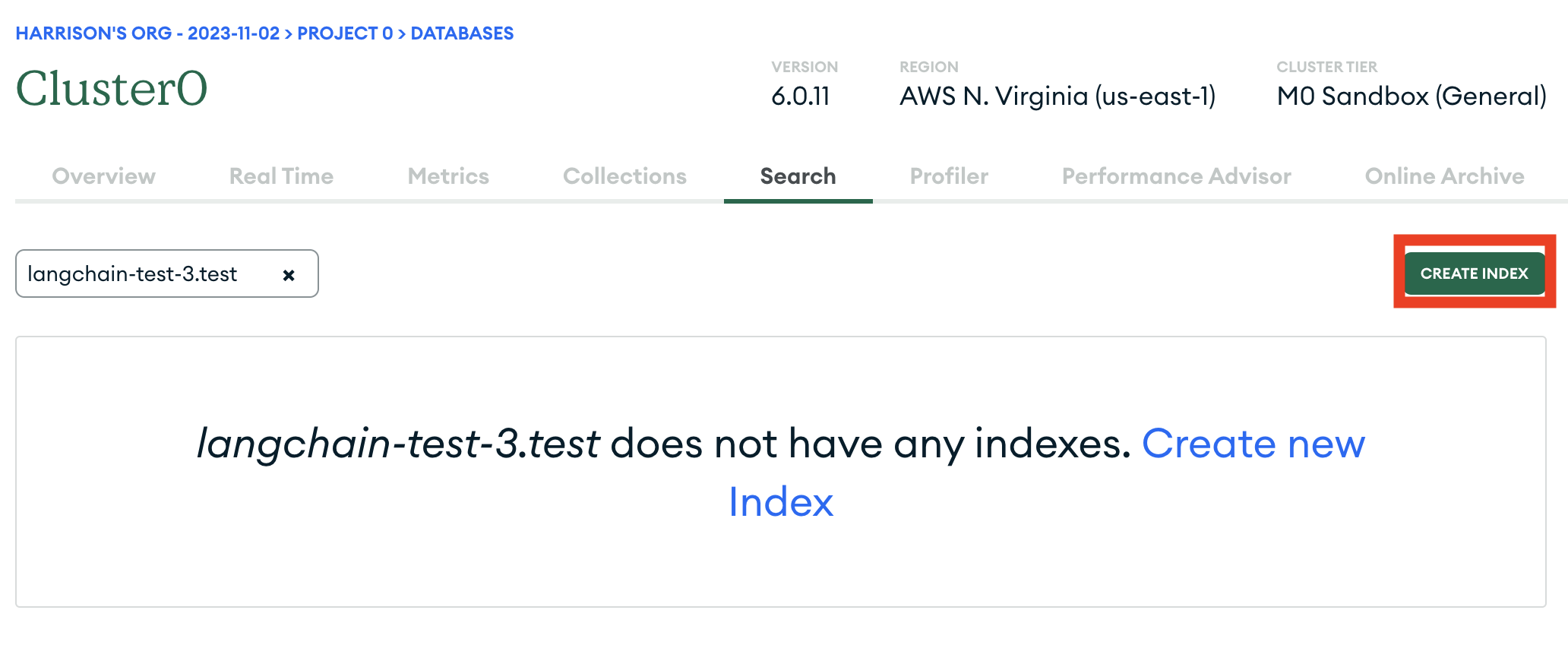
We will use the JSON editor to create it
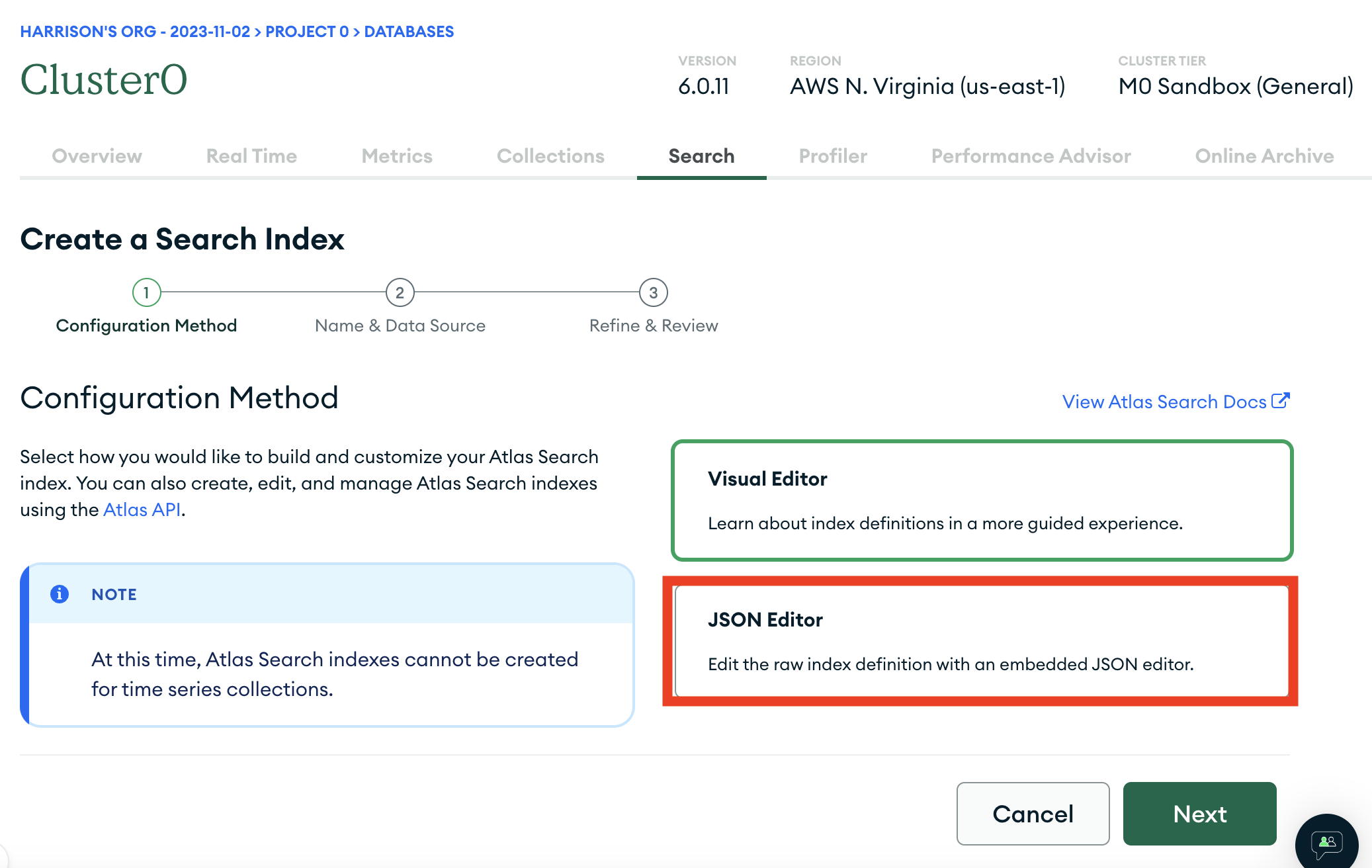
And we will paste the following JSON in:
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 1536,
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
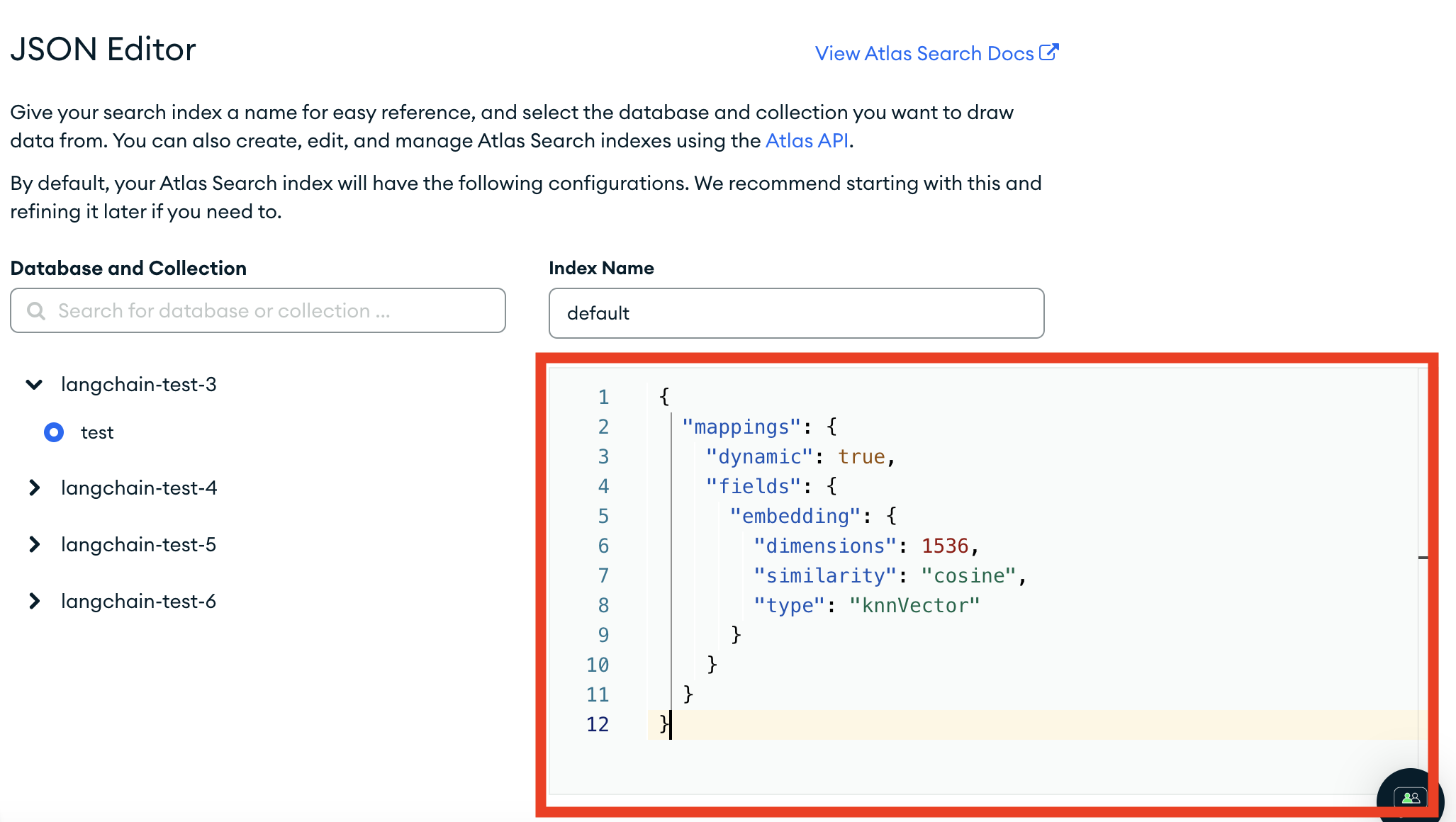
From there, hit "Next" and then "Create Search Index". It will take a little bit but you should then have an index over your data!