mirror of
https://github.com/hwchase17/langchain
synced 2024-11-13 19:10:52 +00:00
Hi there, this PR adds a notebook implementing Anthropic's proposed [Contextual retrieval](https://www.anthropic.com/news/contextual-retrieval) to langchain's cookbook.
1382 lines
54 KiB
Plaintext
1382 lines
54 KiB
Plaintext
{
|
||
"cells": [
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "c6bf25fda89f8656",
|
||
"metadata": {},
|
||
"source": [
|
||
"# Contextual Retrieval\n",
|
||
"\n",
|
||
"In this notebook we will showcase how you can implement Anthropic's [Contextual Retrieval](https://www.anthropic.com/news/contextual-retrieval) using LangChain. Contextual Retrieval addresses the conundrum of traditional RAG approaches by prepending chunk-specific explanatory context to each chunk before embedding.\n",
|
||
"\n",
|
||
"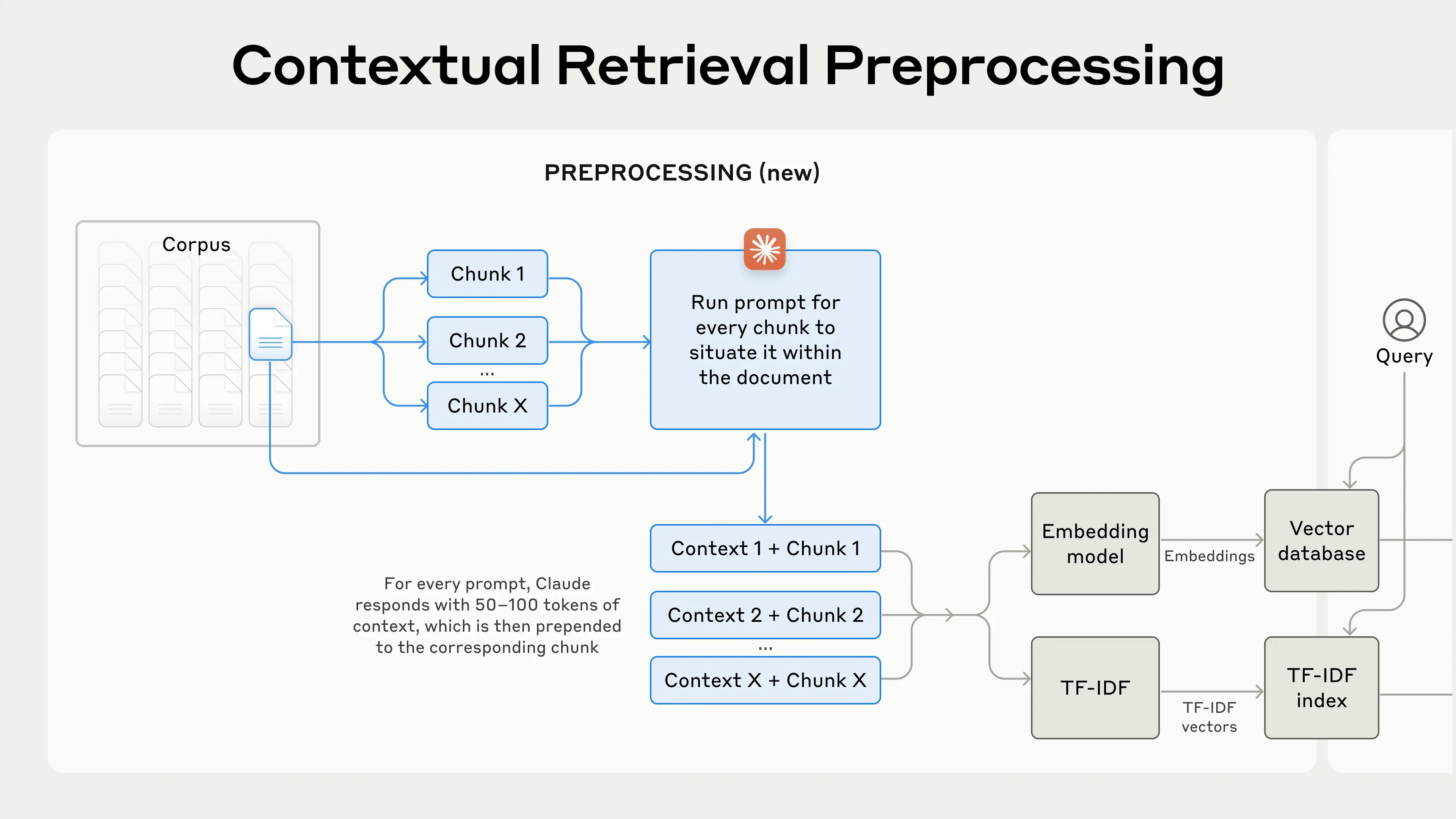"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 59,
|
||
"id": "a4490b37e0479034",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:37.596677Z",
|
||
"start_time": "2024-11-04T20:18:37.594738Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"import logging\n",
|
||
"import os\n",
|
||
"\n",
|
||
"logging.disable(level=logging.INFO)\n",
|
||
"\n",
|
||
"os.environ[\"TOKENIZERS_PARALLELISM\"] = \"true\"\n",
|
||
"\n",
|
||
"os.environ[\"AZURE_OPENAI_API_KEY\"] = \"<YOUR_AZURE_OPENAI_API_KEY>\"\n",
|
||
"os.environ[\"AZURE_OPENAI_ENDPOINT\"] = \"<YOUR_AZURE_OPENAI_ENDPOINT>\"\n",
|
||
"os.environ[\"COHERE_API_KEY\"] = \"<YOUR_COHERE_API_KEY>\""
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 60,
|
||
"id": "baecef6820f63ae5",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:38.261712Z",
|
||
"start_time": "2024-11-04T20:18:37.634673Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"\r\n",
|
||
"\u001B[1m[\u001B[0m\u001B[34;49mnotice\u001B[0m\u001B[1;39;49m]\u001B[0m\u001B[39;49m A new release of pip is available: \u001B[0m\u001B[31;49m24.2\u001B[0m\u001B[39;49m -> \u001B[0m\u001B[32;49m24.3.1\u001B[0m\r\n",
|
||
"\u001B[1m[\u001B[0m\u001B[34;49mnotice\u001B[0m\u001B[1;39;49m]\u001B[0m\u001B[39;49m To update, run: \u001B[0m\u001B[32;49mpip install --upgrade pip\u001B[0m\r\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"!pip install -q langchain langchain-openai langchain-community faiss-cpu rank_bm25 langchain-cohere "
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 61,
|
||
"id": "cdc9006883871d3a",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:38.265682Z",
|
||
"start_time": "2024-11-04T20:18:38.263169Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"from langchain.document_loaders import TextLoader\n",
|
||
"from langchain.prompts import PromptTemplate\n",
|
||
"from langchain.retrievers import BM25Retriever\n",
|
||
"from langchain.vectorstores import FAISS\n",
|
||
"from langchain_cohere import CohereRerank\n",
|
||
"from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "f75da2885a562f6d",
|
||
"metadata": {},
|
||
"source": [
|
||
"## Download Data\n",
|
||
"\n",
|
||
"We will use `Paul Graham Essay` dataset."
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 62,
|
||
"id": "99266f4b27564077",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:38.855105Z",
|
||
"start_time": "2024-11-04T20:18:38.266362Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"--2024-11-04 20:18:38-- https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt\r\n",
|
||
"Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 2606:50c0:8003::154, 2606:50c0:8001::154, 2606:50c0:8002::154, ...\r\n",
|
||
"Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|2606:50c0:8003::154|:443... connected.\r\n",
|
||
"HTTP request sent, awaiting response... 200 OK\r\n",
|
||
"Length: 75042 (73K) [text/plain]\r\n",
|
||
"Saving to: ‘./paul_graham_essay.txt’\r\n",
|
||
"\r\n",
|
||
"./paul_graham_essay 100%[===================>] 73.28K --.-KB/s in 0.04s \r\n",
|
||
"\r\n",
|
||
"2024-11-04 20:18:38 (2.02 MB/s) - ‘./paul_graham_essay.txt’ saved [75042/75042]\r\n",
|
||
"\r\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O './paul_graham_essay.txt'"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "23200549ef2260bb",
|
||
"metadata": {},
|
||
"source": "## Setup LLM and Embedding model"
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 63,
|
||
"id": "bb3cdd9b2aaa304e",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:38.882309Z",
|
||
"start_time": "2024-11-04T20:18:38.856907Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"llm = AzureChatOpenAI(\n",
|
||
" deployment_name=\"gpt-4-32k-0613\",\n",
|
||
" openai_api_version=\"2023-08-01-preview\",\n",
|
||
" temperature=0.0,\n",
|
||
")\n",
|
||
"\n",
|
||
"embeddings = AzureOpenAIEmbeddings(\n",
|
||
" deployment=\"text-embedding-ada-002\",\n",
|
||
" api_version=\"2023-08-01-preview\",\n",
|
||
")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "e29fcd718472faca",
|
||
"metadata": {},
|
||
"source": "## Load Data"
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 64,
|
||
"id": "a429c5e9806687c2",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:38.884826Z",
|
||
"start_time": "2024-11-04T20:18:38.882879Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"loader = TextLoader(\"./paul_graham_essay.txt\")\n",
|
||
"documents = loader.load()\n",
|
||
"WHOLE_DOCUMENT = documents[0].page_content"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "1e8beefd063110bc",
|
||
"metadata": {},
|
||
"source": [
|
||
"## Prompts for creating context for each chunk\n",
|
||
"\n",
|
||
"We will use the following prompts to create chunk-specific explanatory context to each chunk before embedding."
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 65,
|
||
"id": "51131f316c3c4dc1",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:38.887001Z",
|
||
"start_time": "2024-11-04T20:18:38.885430Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"prompt_document = PromptTemplate(\n",
|
||
" input_variables=[\"WHOLE_DOCUMENT\"], template=\"{WHOLE_DOCUMENT}\"\n",
|
||
")\n",
|
||
"prompt_chunk = PromptTemplate(\n",
|
||
" input_variables=[\"CHUNK_CONTENT\"],\n",
|
||
" template=\"Here is the chunk we want to situate within the whole document\\n\\n{CHUNK_CONTENT}\\n\\n\"\n",
|
||
" \"Please give a short succinct context to situate this chunk within the overall document for \"\n",
|
||
" \"the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.\",\n",
|
||
")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "ae226af17efd9663",
|
||
"metadata": {},
|
||
"source": "## Retrievers"
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 66,
|
||
"id": "1565407255685439",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:38.890184Z",
|
||
"start_time": "2024-11-04T20:18:38.887482Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
||
"from langchain_core.documents import BaseDocumentCompressor\n",
|
||
"from langchain_core.retrievers import BaseRetriever\n",
|
||
"\n",
|
||
"\n",
|
||
"def split_text(texts):\n",
|
||
" text_splitter = RecursiveCharacterTextSplitter(chunk_overlap=200)\n",
|
||
" doc_chunks = text_splitter.create_documents(texts)\n",
|
||
" for i, doc in enumerate(doc_chunks):\n",
|
||
" # Append a new Document object with the appropriate doc_id\n",
|
||
" doc.metadata = {\"doc_id\": f\"doc_{i}\"}\n",
|
||
" return doc_chunks\n",
|
||
"\n",
|
||
"\n",
|
||
"def create_embedding_retriever(documents_):\n",
|
||
" vector_store = FAISS.from_documents(documents_, embedding=embeddings)\n",
|
||
" return vector_store.as_retriever(search_kwargs={\"k\": 4})\n",
|
||
"\n",
|
||
"\n",
|
||
"def create_bm25_retriever(documents_):\n",
|
||
" retriever = BM25Retriever.from_documents(documents_, language=\"english\")\n",
|
||
" return retriever\n",
|
||
"\n",
|
||
"\n",
|
||
"# Function to create a combined embedding and BM25 retriever with reranker\n",
|
||
"class EmbeddingBM25RerankerRetriever:\n",
|
||
" def __init__(\n",
|
||
" self,\n",
|
||
" vector_retriever: BaseRetriever,\n",
|
||
" bm25_retriever: BaseRetriever,\n",
|
||
" reranker: BaseDocumentCompressor,\n",
|
||
" ):\n",
|
||
" self.vector_retriever = vector_retriever\n",
|
||
" self.bm25_retriever = bm25_retriever\n",
|
||
" self.reranker = reranker\n",
|
||
"\n",
|
||
" def invoke(self, query: str):\n",
|
||
" vector_docs = self.vector_retriever.invoke(query)\n",
|
||
" bm25_docs = self.bm25_retriever.invoke(query)\n",
|
||
"\n",
|
||
" combined_docs = vector_docs + [\n",
|
||
" doc for doc in bm25_docs if doc not in vector_docs\n",
|
||
" ]\n",
|
||
"\n",
|
||
" reranked_docs = self.reranker.compress_documents(combined_docs, query)\n",
|
||
" return reranked_docs"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "37708e8a15bbef35",
|
||
"metadata": {},
|
||
"source": "### Non-contextual retrievers"
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 67,
|
||
"id": "a85c21f8b344438c",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:18:39.723719Z",
|
||
"start_time": "2024-11-04T20:18:38.890797Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"chunks = split_text([WHOLE_DOCUMENT])\n",
|
||
"\n",
|
||
"embedding_retriever = create_embedding_retriever(chunks)\n",
|
||
"\n",
|
||
"# Define a BM25 retriever\n",
|
||
"bm25_retriever = create_bm25_retriever(chunks)\n",
|
||
"\n",
|
||
"reranker = CohereRerank(top_n=3, model=\"rerank-english-v2.0\")\n",
|
||
"\n",
|
||
"# Create combined retriever\n",
|
||
"embedding_bm25_retriever_rerank = EmbeddingBM25RerankerRetriever(\n",
|
||
" vector_retriever=embedding_retriever,\n",
|
||
" bm25_retriever=bm25_retriever,\n",
|
||
" reranker=reranker,\n",
|
||
")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "8b93626005638acd",
|
||
"metadata": {},
|
||
"source": "### Contextual Retrievers"
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 68,
|
||
"id": "9b9ee0db80ba3e10",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:20:30.134332Z",
|
||
"start_time": "2024-11-04T20:18:39.724296Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"100%|██████████| 21/21 [01:50<00:00, 5.26s/it]\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"import tqdm as tqdm\n",
|
||
"from langchain.docstore.document import Document\n",
|
||
"\n",
|
||
"\n",
|
||
"def create_contextual_chunks(chunks_):\n",
|
||
" # uses a llm to add context to each chunk given the prompts defined above\n",
|
||
" contextual_documents = []\n",
|
||
" for chunk in tqdm.tqdm(chunks_):\n",
|
||
" context = prompt_document.format(WHOLE_DOCUMENT=WHOLE_DOCUMENT)\n",
|
||
" chunk_context = prompt_chunk.format(CHUNK_CONTENT=chunk)\n",
|
||
" llm_response = llm.invoke(context + chunk_context).content\n",
|
||
" page_content = f\"\"\"Text: {chunk.page_content}\\n\\n\\nContext: {llm_response}\"\"\"\n",
|
||
" doc = Document(page_content=page_content, metadata=chunk.metadata)\n",
|
||
" contextual_documents.append(doc)\n",
|
||
" return contextual_documents\n",
|
||
"\n",
|
||
"\n",
|
||
"contextual_documents = create_contextual_chunks(chunks)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 69,
|
||
"id": "e73cc0678c5864af",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:20:30.142210Z",
|
||
"start_time": "2024-11-04T20:20:30.138973Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"Text: I couldn't have put this into words when I was 18. All I knew at the time was that I kept taking philosophy courses and they kept being boring. So I decided to switch to AI.\n",
|
||
"\n",
|
||
"AI was in the air in the mid 1980s, but there were two things especially that made me want to work on it: a novel by Heinlein called The Moon is a Harsh Mistress, which featured an intelligent computer called Mike, and a PBS documentary that showed Terry Winograd using SHRDLU. I haven't tried rereading The Moon is a Harsh Mistress, so I don't know how well it has aged, but when I read it I was drawn entirely into its world. It seemed only a matter of time before we'd have Mike, and when I saw Winograd using SHRDLU, it seemed like that time would be a few years at most. All you had to do was teach SHRDLU more words.\n",
|
||
"\n",
|
||
"There weren't any classes in AI at Cornell then, not even graduate classes, so I started trying to teach myself. Which meant learning Lisp, since in those days Lisp was regarded as the language of AI. The commonly used programming languages then were pretty primitive, and programmers' ideas correspondingly so. The default language at Cornell was a Pascal-like language called PL/I, and the situation was similar elsewhere. Learning Lisp expanded my concept of a program so fast that it was years before I started to have a sense of where the new limits were. This was more like it; this was what I had expected college to do. It wasn't happening in a class, like it was supposed to, but that was ok. For the next couple years I was on a roll. I knew what I was going to do.\n",
|
||
"\n",
|
||
"For my undergraduate thesis, I reverse-engineered SHRDLU. My God did I love working on that program. It was a pleasing bit of code, but what made it even more exciting was my belief — hard to imagine now, but not unique in 1985 — that it was already climbing the lower slopes of intelligence.\n",
|
||
"\n",
|
||
"I had gotten into a program at Cornell that didn't make you choose a major. You could take whatever classes you liked, and choose whatever you liked to put on your degree. I of course chose \"Artificial Intelligence.\" When I got the actual physical diploma, I was dismayed to find that the quotes had been included, which made them read as scare-quotes. At the time this bothered me, but now it seems amusingly accurate, for reasons I was about to discover.\n",
|
||
"\n",
|
||
"I applied to 3 grad schools: MIT and Yale, which were renowned for AI at the time, and Harvard, which I'd visited because Rich Draves went there, and was also home to Bill Woods, who'd invented the type of parser I used in my SHRDLU clone. Only Harvard accepted me, so that was where I went.\n",
|
||
"\n",
|
||
"I don't remember the moment it happened, or if there even was a specific moment, but during the first year of grad school I realized that AI, as practiced at the time, was a hoax. By which I mean the sort of AI in which a program that's told \"the dog is sitting on the chair\" translates this into some formal representation and adds it to the list of things it knows.\n",
|
||
"\n",
|
||
"What these programs really showed was that there's a subset of natural language that's a formal language. But a very proper subset. It was clear that there was an unbridgeable gap between what they could do and actually understanding natural language. It was not, in fact, simply a matter of teaching SHRDLU more words. That whole way of doing AI, with explicit data structures representing concepts, was not going to work. Its brokenness did, as so often happens, generate a lot of opportunities to write papers about various band-aids that could be applied to it, but it was never going to get us Mike.\n",
|
||
"\n",
|
||
"\n",
|
||
"Context: This section of the document discusses the author's journey from studying philosophy to switching to AI during his undergraduate years at Cornell University. He talks about his fascination with AI, his self-learning process, and his undergraduate thesis on reverse-engineering SHRDLU. He also discusses his decision to apply to grad schools, his acceptance at Harvard, and his eventual realization that the AI practices of that time were not going to work. ------------ I couldn't have put this into words when I was 18. All I knew at the time was that I kept taking philosophy courses and they kept being boring. So I decided to switch to AI.\n",
|
||
"\n",
|
||
"AI was in the air in the mid 1980s, but there were two things especially that made me want to work on it: a novel by Heinlein called The Moon is a Harsh Mistress, which featured an intelligent computer called Mike, and a PBS documentary that showed Terry Winograd using SHRDLU. I haven't tried rereading The Moon is a Harsh Mistress, so I don't know how well it has aged, but when I read it I was drawn entirely into its world. It seemed only a matter of time before we'd have Mike, and when I saw Winograd using SHRDLU, it seemed like that time would be a few years at most. All you had to do was teach SHRDLU more words.\n",
|
||
"\n",
|
||
"There weren't any classes in AI at Cornell then, not even graduate classes, so I started trying to teach myself. Which meant learning Lisp, since in those days Lisp was regarded as the language of AI. The commonly used programming languages then were pretty primitive, and programmers' ideas correspondingly so. The default language at Cornell was a Pascal-like language called PL/I, and the situation was similar elsewhere. Learning Lisp expanded my concept of a program so fast that it was years before I started to have a sense of where the new limits were. This was more like it; this was what I had expected college to do. It wasn't happening in a class, like it was supposed to, but that was ok. For the next couple years I was on a roll. I knew what I was going to do.\n",
|
||
"\n",
|
||
"For my undergraduate thesis, I reverse-engineered SHRDLU. My God did I love working on that program. It was a pleasing bit of code, but what made it even more exciting was my belief — hard to imagine now, but not unique in 1985 — that it was already climbing the lower slopes of intelligence.\n",
|
||
"\n",
|
||
"I had gotten into a program at Cornell that didn't make you choose a major. You could take whatever classes you liked, and choose whatever you liked to put on your degree. I of course chose \"Artificial Intelligence.\" When I got the actual physical diploma, I was dismayed to find that the quotes had been included, which made them read as scare-quotes. At the time this bothered me, but now it seems amusingly accurate, for reasons I was about to discover.\n",
|
||
"\n",
|
||
"I applied to 3 grad schools: MIT and Yale, which were renowned for AI at the time, and Harvard, which I'd visited because Rich Draves went there, and was also home to Bill Woods, who'd invented the type of parser I used in my SHRDLU clone. Only Harvard accepted me, so that was where I went.\n",
|
||
"\n",
|
||
"I don't remember the moment it happened, or if there even was a specific moment, but during the first year of grad school I realized that AI, as practiced at the time, was a hoax. By which I mean the sort of AI in which a program that's told \"the dog is sitting on the chair\" translates this into some formal representation and adds it to the list of things it knows.\n",
|
||
"\n",
|
||
"What these programs really showed was that there's a subset of natural language that's a formal language. But a very proper subset. It was clear that there was an unbridgeable gap between what they could do and actually understanding natural language. It was not, in fact, simply a matter of teaching SHRDLU more words. That whole way of doing AI, with explicit data structures representing concepts, was not going to work. Its brokenness did, as so often happens, generate a lot of opportunities to write papers about various band-aids that could be applied to it, but it was never going to get us Mike.\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"print(contextual_documents[1].page_content, \"------------\", chunks[1].page_content)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 70,
|
||
"id": "6ac021069406db1",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:20:31.017725Z",
|
||
"start_time": "2024-11-04T20:20:30.143348Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"contextual_embedding_retriever = create_embedding_retriever(contextual_documents)\n",
|
||
"\n",
|
||
"contextual_bm25_retriever = create_bm25_retriever(contextual_documents)\n",
|
||
"\n",
|
||
"contextual_embedding_bm25_retriever_rerank = EmbeddingBM25RerankerRetriever(\n",
|
||
" vector_retriever=contextual_embedding_retriever,\n",
|
||
" bm25_retriever=contextual_bm25_retriever,\n",
|
||
" reranker=reranker,\n",
|
||
")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "2b04b648230def7d",
|
||
"metadata": {},
|
||
"source": "## Generate Question-Context pairs"
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 71,
|
||
"id": "a1373b118f3cea15",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:20:31.027412Z",
|
||
"start_time": "2024-11-04T20:20:31.018569Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"import json\n",
|
||
"import re\n",
|
||
"import uuid\n",
|
||
"import warnings\n",
|
||
"from typing import Dict, List, Tuple\n",
|
||
"\n",
|
||
"from pydantic import BaseModel\n",
|
||
"from tqdm import tqdm\n",
|
||
"\n",
|
||
"# Prompt to generate questions\n",
|
||
"DEFAULT_QA_GENERATE_PROMPT_TMPL = \"\"\"\\\n",
|
||
"Context information is below.\n",
|
||
"\n",
|
||
"---------------------\n",
|
||
"{context_str}\n",
|
||
"---------------------\n",
|
||
"\n",
|
||
"Given the context information and no prior knowledge.\n",
|
||
"generate only questions based on the below query.\n",
|
||
"\n",
|
||
"You are a Teacher/ Professor. Your task is to setup \\\n",
|
||
"{num_questions_per_chunk} questions for an upcoming \\\n",
|
||
"quiz/examination. The questions should be diverse in nature \\\n",
|
||
"across the document. Restrict the questions to the \\\n",
|
||
"context information provided.\"\n",
|
||
"\"\"\"\n",
|
||
"\n",
|
||
"\n",
|
||
"class QuestionContextEvalDataset(BaseModel):\n",
|
||
" \"\"\"Embedding QA Dataset.\n",
|
||
" Args:\n",
|
||
" queries (Dict[str, str]): Dict id -> query.\n",
|
||
" corpus (Dict[str, str]): Dict id -> string.\n",
|
||
" relevant_docs (Dict[str, List[str]]): Dict query id -> list of doc ids.\n",
|
||
" \"\"\"\n",
|
||
"\n",
|
||
" queries: Dict[str, str] # dict id -> query\n",
|
||
" corpus: Dict[str, str] # dict id -> string\n",
|
||
" relevant_docs: Dict[str, List[str]] # query id -> list of doc ids\n",
|
||
" mode: str = \"text\"\n",
|
||
"\n",
|
||
" @property\n",
|
||
" def query_docid_pairs(self) -> List[Tuple[str, List[str]]]:\n",
|
||
" \"\"\"Get query, relevant doc ids.\"\"\"\n",
|
||
" return [\n",
|
||
" (query, self.relevant_docs[query_id])\n",
|
||
" for query_id, query in self.queries.items()\n",
|
||
" ]\n",
|
||
"\n",
|
||
" def save_json(self, path: str) -> None:\n",
|
||
" \"\"\"Save json.\"\"\"\n",
|
||
" with open(path, \"w\") as f:\n",
|
||
" json.dump(self.dict(), f, indent=4)\n",
|
||
"\n",
|
||
" @classmethod\n",
|
||
" def from_json(cls, path: str) -> \"QuestionContextEvalDataset\":\n",
|
||
" \"\"\"Load json.\"\"\"\n",
|
||
" with open(path) as f:\n",
|
||
" data = json.load(f)\n",
|
||
" return cls(**data)\n",
|
||
"\n",
|
||
"\n",
|
||
"def generate_question_context_pairs(\n",
|
||
" documents: List[Document],\n",
|
||
" llm,\n",
|
||
" qa_generate_prompt_tmpl: str = DEFAULT_QA_GENERATE_PROMPT_TMPL,\n",
|
||
" num_questions_per_chunk: int = 2,\n",
|
||
") -> QuestionContextEvalDataset:\n",
|
||
" \"\"\"Generate evaluation dataset using watsonx LLM and a set of chunks with their chunk_ids\n",
|
||
"\n",
|
||
" Args:\n",
|
||
" documents (List[Document]): chunks of data with chunk_id\n",
|
||
" llm: LLM used for generating questions\n",
|
||
" qa_generate_prompt_tmpl (str): prompt template used for generating questions\n",
|
||
" num_questions_per_chunk (int): number of questions generated per chunk\n",
|
||
"\n",
|
||
" Returns:\n",
|
||
" List[Documents]: List of langchain document objects with page content and metadata\n",
|
||
" \"\"\"\n",
|
||
" doc_dict = {doc.metadata[\"doc_id\"]: doc.page_content for doc in documents}\n",
|
||
" queries = {}\n",
|
||
" relevant_docs = {}\n",
|
||
" for doc_id, text in tqdm(doc_dict.items()):\n",
|
||
" query = qa_generate_prompt_tmpl.format(\n",
|
||
" context_str=text, num_questions_per_chunk=num_questions_per_chunk\n",
|
||
" )\n",
|
||
" response = llm.invoke(query).content\n",
|
||
" result = re.split(r\"\\n+\", response.strip())\n",
|
||
" print(result)\n",
|
||
" questions = [\n",
|
||
" re.sub(r\"^\\d+[\\).\\s]\", \"\", question).strip() for question in result\n",
|
||
" ]\n",
|
||
" questions = [question for question in questions if len(question) > 0][\n",
|
||
" :num_questions_per_chunk\n",
|
||
" ]\n",
|
||
"\n",
|
||
" num_questions_generated = len(questions)\n",
|
||
" if num_questions_generated < num_questions_per_chunk:\n",
|
||
" warnings.warn(\n",
|
||
" f\"Fewer questions generated ({num_questions_generated}) \"\n",
|
||
" f\"than requested ({num_questions_per_chunk}).\"\n",
|
||
" )\n",
|
||
" for question in questions:\n",
|
||
" question_id = str(uuid.uuid4())\n",
|
||
" queries[question_id] = question\n",
|
||
" relevant_docs[question_id] = [doc_id]\n",
|
||
" # construct dataset\n",
|
||
" return QuestionContextEvalDataset(\n",
|
||
" queries=queries, corpus=doc_dict, relevant_docs=relevant_docs\n",
|
||
" )"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 72,
|
||
"id": "49f7a07d9c8a192c",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:21:31.160413Z",
|
||
"start_time": "2024-11-04T20:20:31.028501Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 5%|▍ | 1/21 [00:02<00:59, 2.98s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. Describe the author's early experiences with programming on the IBM 1401. What were some of the challenges he faced and how did the limitations of the technology at the time influence his programming?\", '2. The author initially intended to study philosophy in college but eventually switched to AI. Based on the context, explain the reasons behind this change in his academic direction.']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 10%|▉ | 2/21 [00:06<00:58, 3.10s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. In the context, the author mentions two specific inspirations that led him to pursue AI. Identify these inspirations and explain how they influenced his decision.', '2. The author initially believed that teaching SHRDLU more words would lead to the development of AI. However, he later realized this approach was flawed. Discuss his initial belief and the realization that led him to change his perspective.']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 14%|█▍ | 3/21 [00:09<01:00, 3.37s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. In the context, the author discusses his interest in both computer science and art. Discuss how the author's perspective on the longevity and impact of these two fields influenced his career decisions. Provide specific examples from the text.\", '2. The author mentions his book \"On Lisp\" and his experience of writing it. Based on the context, what challenges did he face while writing this book and how did it contribute to his understanding of Lisp hacking?']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 19%|█▉ | 4/21 [00:12<00:54, 3.21s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. In the context, the author mentions his decision to write his dissertation on the applications of continuations. What reasons does he give for this choice and how does he reflect on this decision in retrospect?', \"2. Describe the author's experience at the Accademia di Belli Arti in Florence. How does he portray the teaching and learning environment at the institution, and what activities did the students engage in during their time there?\"]\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 24%|██▍ | 5/21 [00:15<00:49, 3.11s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. In the context of the document, the author discusses the process of painting still lives and how it differs from painting people. Can you explain this difference and discuss how the author uses this process to create a more realistic representation of the subject?', '2. The author worked at a company called Interleaf, which had incorporated a scripting language into their software. Discuss the challenges the author faced in this job and how it influenced his understanding of programming and software development.']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 29%|██▊ | 6/21 [00:18<00:46, 3.11s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. Based on the author\\'s experience at Interleaf, explain the concept of \"the low end eats the high end\" and how it influenced his later ventures like Viaweb and Y Combinator. ', '2. Discuss the author\\'s perspective on the teaching approach at RISD, particularly in the painting department, and how it contrasts with his expectations. What does he mean by \"signature style\" and how does it relate to the art market?']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 33%|███▎ | 7/21 [00:21<00:40, 2.87s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. In the context, the author mentions his decision to write a book on Lisp. Discuss the author's motivations behind this decision and how it relates to his financial concerns and artistic pursuits.\", '2. Analyze the author\\'s initial business idea of putting art galleries online. Why did it fail according to the author? How did this failure lead to the realization of building an \"internet storefront\"?']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 38%|███▊ | 8/21 [00:23<00:36, 2.80s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. \"Describe the initial challenges faced by the authors while developing the software for online stores and how they overcame them. Also, explain the significance of their idea of running the software on the server.\"', '2. \"Discuss the role of aesthetics and high production values in the success of an online store as mentioned in the context. How did the author\\'s background in art contribute to the development of their online store builder software?\"']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 43%|████▎ | 9/21 [00:26<00:33, 2.76s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. In the context of the document, explain the roles and contributions of Robert and Trevor in the development of the ecommerce software. How did their unique perspectives and skills contribute to the project?', \"2. Based on the author's experiences and observations, discuss the challenges and learnings they encountered in the early stages of ecommerce, particularly in relation to user acquisition and understanding retail. Use specific examples from the text.\"]\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 48%|████▊ | 10/21 [00:30<00:32, 2.98s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. Discuss the significance of growth rate in the success of a startup, as illustrated in the context of Viaweb's journey. How did the author's understanding of this concept evolve over time?\", \"2. Analyze the author's transition from running a startup to working at Yahoo. How did this change impact his personal and professional life, and what led to his decision to leave Yahoo in the summer of 1999?\"]\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 52%|█████▏ | 11/21 [00:32<00:29, 2.95s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. Based on the context, discuss the reasons and circumstances that led the author to leave his job at Yahoo and pursue painting. How did his experiences in California and New York influence his decision to return to the tech industry?', \"2. Analyze the author's idea of building a web app for making web apps. How did he envision this idea to be the future of web applications and what challenges did he face in trying to implement this idea?\"]\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 57%|█████▋ | 12/21 [00:35<00:26, 2.93s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. In the context, the author mentions the creation of a new dialect of Lisp called Arc. Discuss the reasons behind the author's decision to create this new dialect and how it was intended to be used in the development of the Aspra project.\", \"2. The author discusses a significant shift in the publishing industry due to the advent of the internet. Explain how this shift impacted the author's perspective on writing and publishing, and discuss the implications it had for the generation of essays.\"]\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 62%|██████▏ | 13/21 [00:38<00:23, 2.92s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. Based on the author's experiences, discuss the significance of working on projects that lack prestige and how it can indicate the presence of genuine interest and potential for discovery. Provide examples from the text to support your answer.\", \"2. Analyze the author's approach to writing essays and giving talks. How does the author use the prospect of public speaking to stimulate creativity and ensure the content is valuable to the audience? Use specific instances from the text in your response.\"]\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 67%|██████▋ | 14/21 [00:41<00:20, 2.92s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. In the context, the author discusses the formation of Y Combinator. Explain how the unique batch model of Y Combinator was discovered and why it was considered distinctive in the investment world during that time.', \"2. Based on the context, discuss the author's initial hesitation towards angel investing and how his experiences and collaborations led to the creation of his own investment firm. What were some of the novel approaches they took due to their lack of knowledge about being angel investors?\"]\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 71%|███████▏ | 15/21 [00:44<00:17, 2.90s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. \"Discuss the initial structure and strategy of the Summer Founders Program, including its funding model and the benefits it provided to the participating startups. How did this model contribute to the growth and success of Y Combinator?\"', '2. \"Explain the evolution of Hacker News from its initial concept as Startup News to its current form. What was the rationale behind the changes made and how did it align with the overall objectives of Y Combinator?\"']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 76%|███████▌ | 16/21 [00:47<00:14, 2.83s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. In the context provided, the author compares his stress from Hacker News (HN) to a specific situation. Can you explain this analogy and how it reflects his feelings towards HN's impact on his work at Y Combinator (YC)?\", '2. The author mentions a personal event that led to his decision to hand over YC to someone else. What was this event and how did it influence his decision?']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 81%|████████ | 17/21 [00:49<00:10, 2.65s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. Discuss the transition of leadership at YC from the original founders to Sam Altman. What were the reasons behind this change and how was the transition process managed?', '2. Explain the origins and unique characteristics of Lisp as a programming language. How did its initial purpose as a formal model of computation contribute to its power and elegance?']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 86%|████████▌ | 18/21 [00:51<00:07, 2.54s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"['1. \"Discuss the challenges faced by Paul Graham in developing the programming language Bel, and how he overcame them. Provide specific examples from the text.\"', '2. \"Explain the significance of McCarthy\\'s axiomatic approach in the development of Lisp and Bel. How did the evolution of computer power over time influence this process?\"']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 90%|█████████ | 19/21 [00:54<00:05, 2.65s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. In the context, the author mentions a transition from batch processing to microcomputers, skipping a step in the evolution of computers. What was this skipped step and how did it impact the author's perception of microcomputers?\", '2. The author discusses his experience living in Florence and walking to the Accademia. Describe the route he took and the various conditions he experienced during his walks. How did this experience contribute to his understanding and appreciation of the city?']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
" 95%|█████████▌| 20/21 [00:57<00:02, 2.64s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. In the context of the document, explain the significance of the name change from Cambridge Seed to Y Combinator and the choice of the color orange for the logo. What does this reflect about the organization's approach and target audience?\", '2. Discuss the author\\'s perspective on the term \"deal flow\" in relation to startups. How does this view align with the purpose of Y Combinator?']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"100%|██████████| 21/21 [01:00<00:00, 2.86s/it]"
|
||
]
|
||
},
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"[\"1. In the given context, the author uses the concept of space aliens to differentiate between 'invented' and 'discovered'. Explain this concept in detail and discuss how it applies to the Pythagorean theorem and Lisp in McCarthy's 1960 paper.\", '2. The author mentions a significant change in their personal and professional life, which is leaving YC and not working with Jessica anymore. Discuss the metaphor used by the author to describe this change and explain its significance.']\n"
|
||
]
|
||
},
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"qa_pairs = generate_question_context_pairs(chunks, llm, num_questions_per_chunk=2)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "45bbeb3ef1c0c45e",
|
||
"metadata": {},
|
||
"source": "## Evaluate"
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 73,
|
||
"id": "11c7abff478ba921",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:21:31.166152Z",
|
||
"start_time": "2024-11-04T20:21:31.161839Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"def compute_hit_rate(expected_ids, retrieved_ids):\n",
|
||
" \"\"\"\n",
|
||
" Args:\n",
|
||
" expected_ids List[str]: The ground truth doc_id\n",
|
||
" retrieved_ids List[str]: The doc_id from retrieved chunks\n",
|
||
"\n",
|
||
" Returns:\n",
|
||
" float: hit rate as a decimal\n",
|
||
" \"\"\"\n",
|
||
" if retrieved_ids is None or expected_ids is None:\n",
|
||
" raise ValueError(\"Retrieved ids and expected ids must be provided\")\n",
|
||
" is_hit = any(id in expected_ids for id in retrieved_ids)\n",
|
||
" return 1.0 if is_hit else 0.0\n",
|
||
"\n",
|
||
"\n",
|
||
"def compute_mrr(expected_ids, retrieved_ids):\n",
|
||
" \"\"\"\n",
|
||
" Args:\n",
|
||
" expected_ids List[str]: The ground truth doc_id\n",
|
||
" retrieved_ids List[str]: The doc_id from retrieved chunks\n",
|
||
"\n",
|
||
" Returns:\n",
|
||
" float: MRR score as a decimal\n",
|
||
" \"\"\"\n",
|
||
" if retrieved_ids is None or expected_ids is None:\n",
|
||
" raise ValueError(\"Retrieved ids and expected ids must be provided\")\n",
|
||
" for i, id in enumerate(retrieved_ids):\n",
|
||
" if id in expected_ids:\n",
|
||
" return 1.0 / (i + 1)\n",
|
||
" return 0.0\n",
|
||
"\n",
|
||
"\n",
|
||
"def compute_ndcg(expected_ids, retrieved_ids):\n",
|
||
" \"\"\"\n",
|
||
" Args:\n",
|
||
" expected_ids List[str]: The ground truth doc_id\n",
|
||
" retrieved_ids List[str]: The doc_id from retrieved chunks\n",
|
||
"\n",
|
||
" Returns:\n",
|
||
" float: nDCG score as a decimal\n",
|
||
" \"\"\"\n",
|
||
" if retrieved_ids is None or expected_ids is None:\n",
|
||
" raise ValueError(\"Retrieved ids and expected ids must be provided\")\n",
|
||
" dcg = 0.0\n",
|
||
" idcg = 0.0\n",
|
||
" for i, id in enumerate(retrieved_ids):\n",
|
||
" if id in expected_ids:\n",
|
||
" dcg += 1.0 / (i + 1)\n",
|
||
" idcg += 1.0 / (i + 1)\n",
|
||
" return dcg / idcg"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 74,
|
||
"id": "21527aa54b2317d",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:21:31.170867Z",
|
||
"start_time": "2024-11-04T20:21:31.167012Z"
|
||
}
|
||
},
|
||
"outputs": [],
|
||
"source": [
|
||
"import numpy as np\n",
|
||
"import pandas as pd\n",
|
||
"\n",
|
||
"\n",
|
||
"def extract_queries(dataset):\n",
|
||
" values = []\n",
|
||
" for value in dataset.queries.values():\n",
|
||
" values.append(value)\n",
|
||
" return values\n",
|
||
"\n",
|
||
"\n",
|
||
"def extract_doc_ids(documents_):\n",
|
||
" doc_ids = []\n",
|
||
" for doc in documents_:\n",
|
||
" doc_ids.append(f\"{doc.metadata['doc_id']}\")\n",
|
||
" return doc_ids\n",
|
||
"\n",
|
||
"\n",
|
||
"def evaluate(retriever, dataset):\n",
|
||
" mrr_result = []\n",
|
||
" hit_rate_result = []\n",
|
||
" ndcg_result = []\n",
|
||
"\n",
|
||
" # Loop over dataset\n",
|
||
" for i in tqdm(range(len(dataset.queries))):\n",
|
||
" context = retriever.invoke(extract_queries(dataset)[i])\n",
|
||
"\n",
|
||
" expected_ids = dataset.relevant_docs[list(dataset.queries.keys())[i]]\n",
|
||
" retrieved_ids = extract_doc_ids(context)\n",
|
||
" # compute metrics\n",
|
||
" mrr = compute_mrr(expected_ids=expected_ids, retrieved_ids=retrieved_ids)\n",
|
||
" hit_rate = compute_hit_rate(\n",
|
||
" expected_ids=expected_ids, retrieved_ids=retrieved_ids\n",
|
||
" )\n",
|
||
" ndgc = compute_ndcg(expected_ids=expected_ids, retrieved_ids=retrieved_ids)\n",
|
||
" # append results\n",
|
||
" mrr_result.append(mrr)\n",
|
||
" hit_rate_result.append(hit_rate)\n",
|
||
" ndcg_result.append(ndgc)\n",
|
||
"\n",
|
||
" array2D = np.array([mrr_result, hit_rate_result, ndcg_result])\n",
|
||
" mean_results = np.mean(array2D, axis=1)\n",
|
||
" results_df = pd.DataFrame(mean_results)\n",
|
||
" results_df.index = [\"MRR\", \"Hit Rate\", \"nDCG\"]\n",
|
||
" return results_df"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 75,
|
||
"id": "9f9c76d4f00fc8b",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:21:50.212361Z",
|
||
"start_time": "2024-11-04T20:21:31.171699Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"100%|██████████| 42/42 [00:19<00:00, 2.21it/s]\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"embedding_bm25_rerank_results = evaluate(embedding_bm25_retriever_rerank, qa_pairs)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 76,
|
||
"id": "48446a2a806329db",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:22:08.024314Z",
|
||
"start_time": "2024-11-04T20:21:50.213597Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"100%|██████████| 42/42 [00:17<00:00, 2.36it/s]\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"contextual_embedding_bm25_rerank_results = evaluate(\n",
|
||
" contextual_embedding_bm25_retriever_rerank, qa_pairs\n",
|
||
")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 77,
|
||
"id": "5f15b680db1e2a4c",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:22:10.838380Z",
|
||
"start_time": "2024-11-04T20:22:08.026152Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"100%|██████████| 42/42 [00:02<00:00, 14.96it/s]\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"embedding_retriever_results = evaluate(embedding_retriever, qa_pairs)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 78,
|
||
"id": "9abc2f5386eea350",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:22:13.538817Z",
|
||
"start_time": "2024-11-04T20:22:10.839183Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"100%|██████████| 42/42 [00:02<00:00, 15.57it/s]\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"contextual_embedding_retriever_results = evaluate(\n",
|
||
" contextual_embedding_retriever, qa_pairs\n",
|
||
")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 79,
|
||
"id": "21a7886c219437f2",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:22:13.556293Z",
|
||
"start_time": "2024-11-04T20:22:13.539422Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"100%|██████████| 42/42 [00:00<00:00, 2934.59it/s]\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"bm25_results = evaluate(bm25_retriever, qa_pairs)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 80,
|
||
"id": "226c01c4fb0441e8",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:22:13.573494Z",
|
||
"start_time": "2024-11-04T20:22:13.557066Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"name": "stderr",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"100%|██████████| 42/42 [00:00<00:00, 3022.46it/s]\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"contextual_bm25_results = evaluate(contextual_bm25_retriever, qa_pairs)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 81,
|
||
"id": "b0f932b2b804e38a",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:22:13.578465Z",
|
||
"start_time": "2024-11-04T20:22:13.574085Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"data": {
|
||
"text/html": [
|
||
"<div>\n",
|
||
"<style scoped>\n",
|
||
" .dataframe tbody tr th:only-of-type {\n",
|
||
" vertical-align: middle;\n",
|
||
" }\n",
|
||
"\n",
|
||
" .dataframe tbody tr th {\n",
|
||
" vertical-align: top;\n",
|
||
" }\n",
|
||
"\n",
|
||
" .dataframe thead th {\n",
|
||
" text-align: right;\n",
|
||
" }\n",
|
||
"</style>\n",
|
||
"<table border=\"1\" class=\"dataframe\">\n",
|
||
" <thead>\n",
|
||
" <tr style=\"text-align: right;\">\n",
|
||
" <th></th>\n",
|
||
" <th>Retrievers</th>\n",
|
||
" <th>MRR</th>\n",
|
||
" <th>Hit Rate</th>\n",
|
||
" <th>nDCG</th>\n",
|
||
" </tr>\n",
|
||
" </thead>\n",
|
||
" <tbody>\n",
|
||
" <tr>\n",
|
||
" <th>0</th>\n",
|
||
" <td>Embedding Retriever</td>\n",
|
||
" <td>0.797619</td>\n",
|
||
" <td>0.904762</td>\n",
|
||
" <td>0.382857</td>\n",
|
||
" </tr>\n",
|
||
" <tr>\n",
|
||
" <th>1</th>\n",
|
||
" <td>BM25 Retriever</td>\n",
|
||
" <td>0.865079</td>\n",
|
||
" <td>0.928571</td>\n",
|
||
" <td>0.415238</td>\n",
|
||
" </tr>\n",
|
||
" <tr>\n",
|
||
" <th>2</th>\n",
|
||
" <td>Embedding + BM25 Retriever + Reranker</td>\n",
|
||
" <td>0.960317</td>\n",
|
||
" <td>1.000000</td>\n",
|
||
" <td>0.523810</td>\n",
|
||
" </tr>\n",
|
||
" </tbody>\n",
|
||
"</table>\n",
|
||
"</div>"
|
||
],
|
||
"text/plain": [
|
||
" Retrievers MRR Hit Rate nDCG\n",
|
||
"0 Embedding Retriever 0.797619 0.904762 0.382857\n",
|
||
"1 BM25 Retriever 0.865079 0.928571 0.415238\n",
|
||
"2 Embedding + BM25 Retriever + Reranker 0.960317 1.000000 0.523810"
|
||
]
|
||
},
|
||
"execution_count": 81,
|
||
"metadata": {},
|
||
"output_type": "execute_result"
|
||
}
|
||
],
|
||
"source": [
|
||
"def display_results(name, eval_results):\n",
|
||
" \"\"\"Display results from evaluate.\"\"\"\n",
|
||
"\n",
|
||
" metrics = [\"MRR\", \"Hit Rate\", \"nDCG\"]\n",
|
||
"\n",
|
||
" columns = {\n",
|
||
" \"Retrievers\": [name],\n",
|
||
" **{metric: val for metric, val in zip(metrics, eval_results.values)},\n",
|
||
" }\n",
|
||
"\n",
|
||
" metric_df = pd.DataFrame(columns)\n",
|
||
"\n",
|
||
" return metric_df\n",
|
||
"\n",
|
||
"\n",
|
||
"pd.concat(\n",
|
||
" [\n",
|
||
" display_results(\"Embedding Retriever\", embedding_retriever_results),\n",
|
||
" display_results(\"BM25 Retriever\", bm25_results),\n",
|
||
" display_results(\n",
|
||
" \"Embedding + BM25 Retriever + Reranker\",\n",
|
||
" embedding_bm25_rerank_results,\n",
|
||
" ),\n",
|
||
" ],\n",
|
||
" ignore_index=True,\n",
|
||
" axis=0,\n",
|
||
")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 82,
|
||
"id": "ede2c131b792589b",
|
||
"metadata": {
|
||
"ExecuteTime": {
|
||
"end_time": "2024-11-04T20:22:13.582297Z",
|
||
"start_time": "2024-11-04T20:22:13.579076Z"
|
||
}
|
||
},
|
||
"outputs": [
|
||
{
|
||
"data": {
|
||
"text/html": [
|
||
"<div>\n",
|
||
"<style scoped>\n",
|
||
" .dataframe tbody tr th:only-of-type {\n",
|
||
" vertical-align: middle;\n",
|
||
" }\n",
|
||
"\n",
|
||
" .dataframe tbody tr th {\n",
|
||
" vertical-align: top;\n",
|
||
" }\n",
|
||
"\n",
|
||
" .dataframe thead th {\n",
|
||
" text-align: right;\n",
|
||
" }\n",
|
||
"</style>\n",
|
||
"<table border=\"1\" class=\"dataframe\">\n",
|
||
" <thead>\n",
|
||
" <tr style=\"text-align: right;\">\n",
|
||
" <th></th>\n",
|
||
" <th>Retrievers</th>\n",
|
||
" <th>MRR</th>\n",
|
||
" <th>Hit Rate</th>\n",
|
||
" <th>nDCG</th>\n",
|
||
" </tr>\n",
|
||
" </thead>\n",
|
||
" <tbody>\n",
|
||
" <tr>\n",
|
||
" <th>0</th>\n",
|
||
" <td>Contextual Embedding Retriever</td>\n",
|
||
" <td>0.785714</td>\n",
|
||
" <td>0.904762</td>\n",
|
||
" <td>0.377143</td>\n",
|
||
" </tr>\n",
|
||
" <tr>\n",
|
||
" <th>1</th>\n",
|
||
" <td>Contextual BM25 Retriever</td>\n",
|
||
" <td>0.908730</td>\n",
|
||
" <td>0.976190</td>\n",
|
||
" <td>0.436190</td>\n",
|
||
" </tr>\n",
|
||
" <tr>\n",
|
||
" <th>2</th>\n",
|
||
" <td>Contextual Embedding + BM25 Retriever + Reranker</td>\n",
|
||
" <td>0.984127</td>\n",
|
||
" <td>1.000000</td>\n",
|
||
" <td>0.536797</td>\n",
|
||
" </tr>\n",
|
||
" </tbody>\n",
|
||
"</table>\n",
|
||
"</div>"
|
||
],
|
||
"text/plain": [
|
||
" Retrievers MRR Hit Rate \\\n",
|
||
"0 Contextual Embedding Retriever 0.785714 0.904762 \n",
|
||
"1 Contextual BM25 Retriever 0.908730 0.976190 \n",
|
||
"2 Contextual Embedding + BM25 Retriever + Reranker 0.984127 1.000000 \n",
|
||
"\n",
|
||
" nDCG \n",
|
||
"0 0.377143 \n",
|
||
"1 0.436190 \n",
|
||
"2 0.536797 "
|
||
]
|
||
},
|
||
"execution_count": 82,
|
||
"metadata": {},
|
||
"output_type": "execute_result"
|
||
}
|
||
],
|
||
"source": [
|
||
"pd.concat(\n",
|
||
" [\n",
|
||
" display_results(\n",
|
||
" \"Contextual Embedding Retriever\", contextual_embedding_retriever_results\n",
|
||
" ),\n",
|
||
" display_results(\"Contextual BM25 Retriever\", contextual_bm25_results),\n",
|
||
" display_results(\n",
|
||
" \"Contextual Embedding + BM25 Retriever + Reranker\",\n",
|
||
" contextual_embedding_bm25_rerank_results,\n",
|
||
" ),\n",
|
||
" ],\n",
|
||
" ignore_index=True,\n",
|
||
" axis=0,\n",
|
||
")"
|
||
]
|
||
}
|
||
],
|
||
"metadata": {
|
||
"kernelspec": {
|
||
"display_name": "Python 3",
|
||
"language": "python",
|
||
"name": "python3"
|
||
},
|
||
"language_info": {
|
||
"codemirror_mode": {
|
||
"name": "ipython",
|
||
"version": 2
|
||
},
|
||
"file_extension": ".py",
|
||
"mimetype": "text/x-python",
|
||
"name": "python",
|
||
"nbconvert_exporter": "python",
|
||
"pygments_lexer": "ipython2",
|
||
"version": "2.7.6"
|
||
}
|
||
},
|
||
"nbformat": 4,
|
||
"nbformat_minor": 5
|
||
}
|