# Add documentation for Databricks integration
This is a follow-up of https://github.com/hwchase17/langchain/pull/4702
It documents the details of how to integrate Databricks using langchain.
It also provides examples in a notebook.
## Who can review?
@dev2049 @hwchase17 since you are aware of the context. We will promote
the integration after this doc is ready. Thanks in advance!
# Remove autoreload in examples
Remove the `autoreload` in examples since it is not necessary for most
users:
```
%load_ext autoreload,
%autoreload 2
```
This PR adds support for Databricks runtime and Databricks SQL by using
[Databricks SQL Connector for
Python](https://docs.databricks.com/dev-tools/python-sql-connector.html).
As a cloud data platform, accessing Databricks requires a URL as follows
`databricks://token:{api_token}@{hostname}?http_path={http_path}&catalog={catalog}&schema={schema}`.
**The URL is **complicated** and it may take users a while to figure it
out**. Since the fields `api_token`/`hostname`/`http_path` fields are
known in the Databricks notebook, I am proposing a new method
`from_databricks` to simplify the connection to Databricks.
## In Databricks Notebook
After changes, Databricks users only need to specify the `catalog` and
`schema` field when using langchain.
<img width="881" alt="image"
src="https://github.com/hwchase17/langchain/assets/1097932/984b4c57-4c2d-489d-b060-5f4918ef2f37">
## In Jupyter Notebook
The method can be used on the local setup as well:
<img width="678" alt="image"
src="https://github.com/hwchase17/langchain/assets/1097932/142e8805-a6ef-4919-b28e-9796ca31ef19">
# Added another helpful way for developers who want to set OpenAI API
Key dynamically
Previous methods like exporting environment variables are good for
project-wide settings.
But many use cases need to assign API keys dynamically, recently.
```python
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="OPENAI_API_KEY")
```
## Before submitting
```bash
export OPENAI_API_KEY="..."
```
Or,
```python
import os
os.environ["OPENAI_API_KEY"] = "..."
```
<hr>
Thank you.
Cheers,
Bongsang
- Added links to the vectorstore providers
- Added installation code (it is not clear that we have to go to the
`LangChan Ecosystem` page to get installation instructions.)
My attempt at improving the `Chain`'s `Getting Started` docs and
`LLMChain` docs. Might need some proof-reading as English is not my
first language.
In LLM examples, I replaced the example use case when a simpler one
(shorter LLM output) to reduce cognitive load.
Have seen questions about whether or not the `SQLDatabaseChain` supports
more than just sqlite, which was unclear in the docs, so tried to
clarify that and how to connect to other dialects.
`combine_docs` does not go through the standard chain call path which
means that chain callbacks won't be triggered, meaning QA chains won't
be traced properly, this fixes that.
Also fix several errors in the chat_vector_db notebook
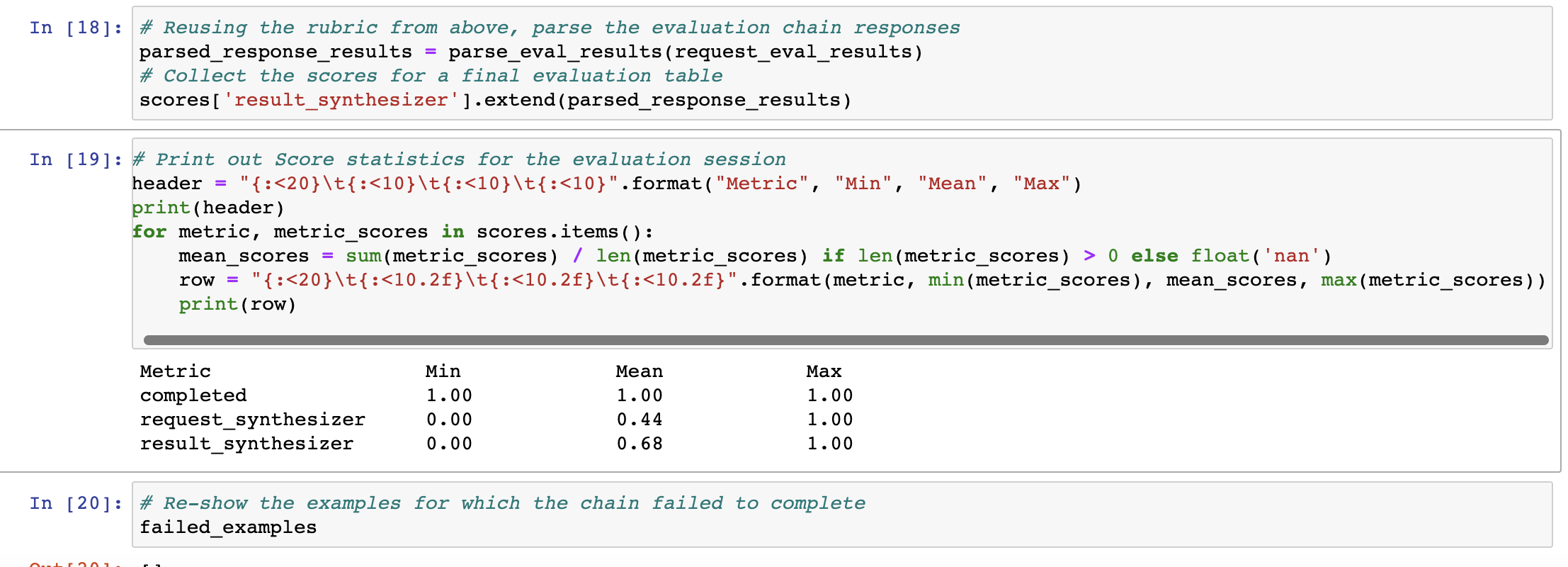
Evaluation so far has shown that agents do a reasonable job of emitting
`json` blocks as arguments when cued (instead of typescript), and `json`
permits the `strict=False` flag to permit control characters, which are
likely to appear in the response in particular.
This PR makes this change to the request and response synthesizer
chains, and fixes the temperature to the OpenAI agent in the eval
notebook. It also adds a `raise_error = False` flag in the notebook to
facilitate debugging
This still doesn't handle the following
- non-JSON media types
- anyOf, allOf, oneOf's
And doesn't emit the typescript definitions for referred types yet, but
that can be saved for a separate PR.
Also, we could have better support for Swagger 2.0 specs and OpenAPI
3.0.3 (can use the same lib for the latter) recommend offline conversion
for now.
{kind=link}
{kind=link}