This PR adds a LangChain implementation of CAMEL role-playing example:
https://github.com/lightaime/camel.
I am sorry that I am not that familiar with LangChain. So I only
implement it in a naive way. There may be a better way to implement it.
**Description**
Add custom vector field name and text field name while indexing and
querying for OpenSearch
**Issues**
https://github.com/hwchase17/langchain/issues/2500
Signed-off-by: Naveen Tatikonda <navtat@amazon.com>
Hi,
just wanted to mention that I added `langchain` to
[conda-forge](https://github.com/conda-forge/langchain-feedstock), so
that it can be installed with `conda`/`mamba` etc.
This makes it available to some corporate users with custom
conda-servers and people who like to manage their python envs with
conda.
Took me a bit to find the proper places to get the API keys. The link
earlier provided to setup search is still good, but why not provide
direct link to the Google cloud tools that give you ability to create
keys?
`combine_docs` does not go through the standard chain call path which
means that chain callbacks won't be triggered, meaning QA chains won't
be traced properly, this fixes that.
Also fix several errors in the chat_vector_db notebook
Adds a new pdf loader using the existing dependency on PDFMiner.
The new loader can be helpful for chunking texts semantically into
sections as the output html content can be parsed via `BeautifulSoup` to
get more structured and rich information about font size, page numbers,
pdf headers/footers, etc. which may not be available otherwise with
other pdf loaders
Improvements to Deep Lake Vector Store
- much faster view loading of embeddings after filters with
`fetch_chunks=True`
- 2x faster ingestion
- use np.float32 for embeddings to save 2x storage, LZ4 compression for
text and metadata storage (saves up to 4x storage for text data)
- user defined functions as filters
Docs
- Added retriever full example for analyzing twitter the-algorithm
source code with GPT4
- Added a use case for code analysis (please let us know your thoughts
how we can improve it)
---------
Co-authored-by: Davit Buniatyan <d@activeloop.ai>
## Why this PR?
Fixes#2624
There's a missing import statement in AzureOpenAI embeddings example.
## What's new in this PR?
- Import `OpenAIEmbeddings` before creating it's object.
## How it's tested?
- By running notebook and creating embedding object.
Signed-off-by: letmerecall <girishsharma001@gmail.com>
Right now, eval chains require an answer for every question. It's
cumbersome to collect this ground truth so getting around this issue
with 2 things:
* Adding a context param in `ContextQAEvalChain` and simply evaluating
if the question is answered accurately from context
* Adding chain of though explanation prompting to improve the accuracy
of this w/o GT.
This also gets to feature parity with openai/evals which has the same
contextual eval w/o GT.
TODO in follow-up:
* Better prompt inheritance. No need for seperate prompt for CoT
reasoning. How can we merge them together
---------
Co-authored-by: Vashisht Madhavan <vashishtmadhavan@Vashs-MacBook-Pro.local>
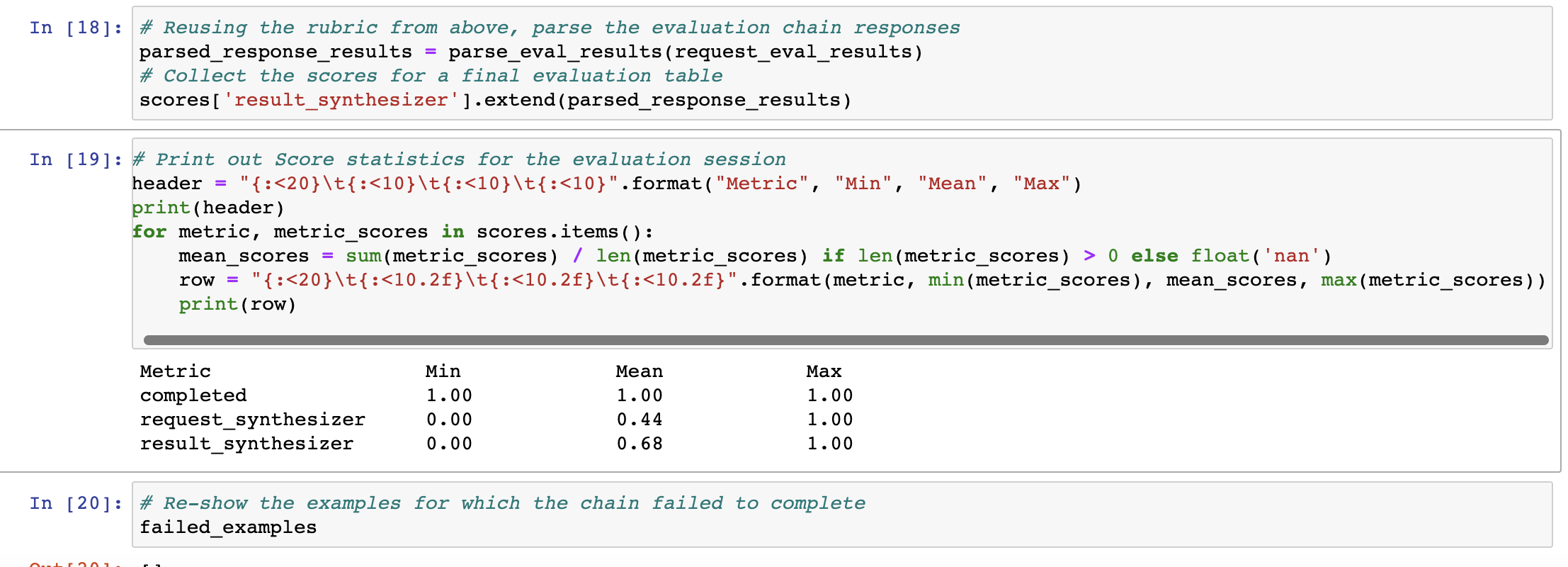
Evaluation so far has shown that agents do a reasonable job of emitting
`json` blocks as arguments when cued (instead of typescript), and `json`
permits the `strict=False` flag to permit control characters, which are
likely to appear in the response in particular.
This PR makes this change to the request and response synthesizer
chains, and fixes the temperature to the OpenAI agent in the eval
notebook. It also adds a `raise_error = False` flag in the notebook to
facilitate debugging
This still doesn't handle the following
- non-JSON media types
- anyOf, allOf, oneOf's
And doesn't emit the typescript definitions for referred types yet, but
that can be saved for a separate PR.
Also, we could have better support for Swagger 2.0 specs and OpenAPI
3.0.3 (can use the same lib for the latter) recommend offline conversion
for now.
### Features include
- Metadata based embedding search
- Choice of distance metric function (`L2` for Euclidean, `L1` for
Nuclear, `max` L-infinity distance, `cos` for cosine similarity, 'dot'
for dot product. Defaults to `L2`
- Returning scores
- Max Marginal Relevance Search
- Deleting samples from the dataset
### Notes
- Added numerous tests, let me know if you would like to shorten them or
make smarter
---------
Co-authored-by: Davit Buniatyan <d@activeloop.ai>
{kind=link}