MHTML is a very interesting format since it's used both for emails but
also for archived webpages. Some scraping projects want to store pages
in disk to process them later, mhtml is perfect for that use case.
This is heavily inspired from the beautifulsoup html loader, but
extracting the html part from the mhtml file.
---------
Co-authored-by: rlm <pexpresss31@gmail.com>
# Add caching to BaseChatModel
Fixes#1644
(Sidenote: While testing, I noticed we have multiple implementations of
Fake LLMs, used for testing. I consolidated them.)
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
Models
- @hwchase17
- @agola11
Twitter: [@UmerHAdil](https://twitter.com/@UmerHAdil) | Discord:
RicChilligerDude#7589
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Fixes#5456
This PR removes the `callbacks` argument from a tool's schema when
creating a `Tool` or `StructuredTool` with the `from_function` method
and `infer_schema` is set to `True`. The `callbacks` argument is now
removed in the `create_schema_from_function` and `_get_filtered_args`
methods. As suggested by @vowelparrot, this fix provides a
straightforward solution that minimally affects the existing
implementation.
A test was added to verify that this change enables the expected use of
`Tool` and `StructuredTool` when using a `CallbackManager` and inferring
the tool's schema.
- @hwchase17
A new implementation of `StreamlitCallbackHandler`. It formats Agent
thoughts into Streamlit expanders.
You can see the handler in action here:
https://langchain-mrkl.streamlit.app/
Per a discussion with Harrison, we'll be adding a
`StreamlitCallbackHandler` implementation to an upcoming
[Streamlit](https://github.com/streamlit/streamlit) release as well, and
will be updating it as we add new LLM- and LangChain-specific features
to Streamlit.
The idea with this PR is that the LangChain `StreamlitCallbackHandler`
will "auto-update" in a way that keeps it forward- (and backward-)
compatible with Streamlit. If the user has an older Streamlit version
installed, the LangChain `StreamlitCallbackHandler` will be used; if
they have a newer Streamlit version that has an updated
`StreamlitCallbackHandler`, that implementation will be used instead.
(I'm opening this as a draft to get the conversation going and make sure
we're on the same page. We're really excited to land this into
LangChain!)
#### Who can review?
@agola11, @hwchase17
Already supported in the reverse operation in
`_convert_message_to_dict()`, this just provides parity.
@hwchase17
@agola11
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
W.r.t recent changes, ChatPromptTemplate does not accepting partial
variables. This PR should fix that issue.
Fixes#6431
#### Who can review?
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Throwing ToolException when incorrect arguments are passed to tools so
that that agent can course correct them.
# Incorrect argument count handling
I was facing an error where the agent passed incorrect arguments to
tools. As per the discussions going around, I started throwing
ToolException to allow the model to course correct.
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
#### Before submitting
Add memory support for `OpenAIFunctionsAgent` like
`StructuredChatAgent`.
#### Who can review?
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
In LangChain, all module classes are enumerated in the `__init__.py`
file of the correspondent module. But some classes were missed and were
not included in the module `__init__.py`
This PR:
- added the missed classes to the module `__init__.py` files
- `__init__.py:__all_` variable value (a list of the class names) was
sorted
- `langchain.tools.sql_database.tool.QueryCheckerTool` was renamed into
the `QuerySQLCheckerTool` because it conflicted with
`langchain.tools.spark_sql.tool.QueryCheckerTool`
- changes to `pyproject.toml`:
- added `pgvector` to `pyproject.toml:extended_testing`
- added `pandas` to
`pyproject.toml:[tool.poetry.group.test.dependencies]`
- commented out the `streamlit` from `collbacks/__init__.py`, It is
because now the `streamlit` requires Python >=3.7, !=3.9.7
- fixed duplicate names in `tools`
- fixed correspondent ut-s
#### Who can review?
@hwchase17
@dev2049
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
## Add Solidity programming language support for code splitter.
Twitter: @0xjord4n_
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @hwchase17
VectorStores / Retrievers / Memory
- @dev2049
-->
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Fixes (not reported) an error that may occur in some cases in the
RecursiveCharacterTextSplitter.
An empty `new_separators` array ([]) would end up in the else path of
the condition below and used in a function where it is expected to be
non empty.
```python
if new_separators is None:
...
else:
# _split_text() expects this array to be non-empty!
other_info = self._split_text(s, new_separators)
```
resulting in an `IndexError`
```python
def _split_text(self, text: str, separators: List[str]) -> List[str]:
"""Split incoming text and return chunks."""
final_chunks = []
# Get appropriate separator to use
> separator = separators[-1]
E IndexError: list index out of range
langchain/text_splitter.py:425: IndexError
```
#### Who can review?
@hwchase17 @eyurtsev
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
#### Add start index to metadata in TextSplitter
- Modified method `create_documents` to track start position of each
chunk
- The `start_index` is included in the metadata if the `add_start_index`
parameter in the class constructor is set to `True`
This enables referencing back to the original document, particularly
useful when a specific chunk is retrieved.
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@eyurtsev @agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
This introduces the `YoutubeAudioLoader`, which will load blobs from a
YouTube url and write them. Blobs are then parsed by
`OpenAIWhisperParser()`, as show in this
[PR](https://github.com/hwchase17/langchain/pull/5580), but we extend
the parser to split audio such that each chuck meets the 25MB OpenAI
size limit. As shown in the notebook, this enables a very simple UX:
```
# Transcribe the video to text
loader = GenericLoader(YoutubeAudioLoader([url],save_dir),OpenAIWhisperParser())
docs = loader.load()
```
Tested on full set of Karpathy lecture videos:
```
# Karpathy lecture videos
urls = ["https://youtu.be/VMj-3S1tku0"
"https://youtu.be/PaCmpygFfXo",
"https://youtu.be/TCH_1BHY58I",
"https://youtu.be/P6sfmUTpUmc",
"https://youtu.be/q8SA3rM6ckI",
"https://youtu.be/t3YJ5hKiMQ0",
"https://youtu.be/kCc8FmEb1nY"]
# Directory to save audio files
save_dir = "~/Downloads/YouTube"
# Transcribe the videos to text
loader = GenericLoader(YoutubeAudioLoader(urls,save_dir),OpenAIWhisperParser())
docs = loader.load()
```
# What does this PR do?
Change the HTML tags so that a tag with attributes can be found.
## Before submitting
- [x] Tests added
- [x] CI/CD validated
### Who can review?
Anyone in the community is free to review the PR once the tests have
passed. Feel free to tag
members/contributors who may be interested in your PR.
- Remove the client implementation (this breaks backwards compatibility
for existing testers. I could keep the stub in that file if we want, but
not many people are using it yet
- Add SDK as dependency
- Update the 'run_on_dataset' method to be a function that optionally
accepts a client as an argument
- Remove the langchain plus server implementation (you get it for free
with the SDK now)
We could make the SDK optional for now, but the plan is to use w/in the
tracer so it would likely become a hard dependency at some point.
Fixes#5614
#### Issue
The `***` combination produces an exception when used as a seperator in
`re.split`. Instead `\*\*\*` should be used for regex exprations.
#### Who can review?
@eyurtsev
# OpenAIWhisperParser
This PR creates a new parser, `OpenAIWhisperParser`, that uses the
[OpenAI Whisper
model](https://platform.openai.com/docs/guides/speech-to-text/quickstart)
to perform transcription of audio files to text (`Documents`). Please
see the notebook for usage.
Zep now supports persisting custom metadata with messages and hybrid
search across both message embeddings and structured metadata. This PR
implements custom metadata and enhancements to the
`ZepChatMessageHistory` and `ZepRetriever` classes to implement this
support.
Tag maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
---------
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
# Check if generated Cypher code is wrapped in backticks
Some LLMs like the VertexAI like to explain how they generated the
Cypher statement and wrap the actual code in three backticks:
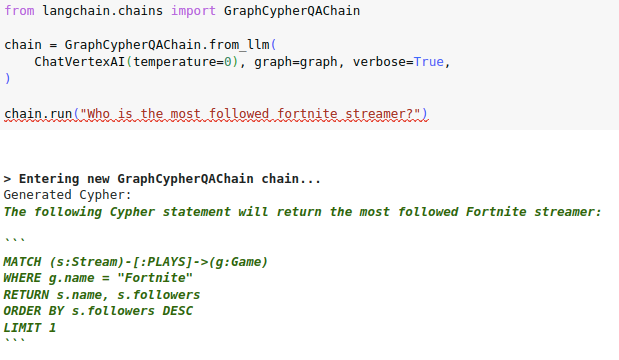
I have observed a similar pattern with OpenAI chat models in a
conversational settings, where multiple user and assistant message are
provided to the LLM to generate Cypher statements, where then the LLM
wants to maybe apologize for previous steps or explain its thoughts.
Interestingly, both OpenAI and VertexAI wrap the code in three backticks
if they are doing any explaining or apologizing. Checking if the
generated cypher is wrapped in backticks seems like a low-hanging fruit
to expand the cypher search to other LLMs and conversational settings.
Raises exception if OutputParsers receive a response with both a valid
action and a final answer
Currently, if an OutputParser receives a response which includes both an
action and a final answer, they return a FinalAnswer object. This allows
the parser to accept responses which propose an action and hallucinate
an answer without the action being parsed or taken by the agent.
This PR changes the logic to:
1. store a variable checking whether a response contains the
`FINAL_ANSWER_ACTION` (this is the easier condition to check).
2. store a variable checking whether the response contains a valid
action
3. if both are present, raise a new exception stating that both are
present
4. if an action is present, return an AgentAction
5. if an answer is present, return an AgentAnswer
6. if neither is present, raise the relevant exception based around the
action format (these have been kept consistent with the prior exception
messages)
Disclaimer:
* Existing mock data included strings which did include an action and an
answer. This might indicate that prioritising returning AgentAnswer was
always correct, and I am patching out desired behaviour? @hwchase17 to
advice. Curious if there are allowed cases where this is not
hallucinating, and we do want the LLM to output an action which isn't
taken.
* I have not passed `send_to_llm` through this new exception
Fixes#5601
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@hwchase17 - project lead
@vowelparrot
# Fixes SQLAlchemy truncating the result if you have a big/text column
with many chars.
SQLAlchemy truncates columns if you try to convert a Row or Sequence to
a string directly
For comparison:
- Before:
```[('Harrison', 'That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio ... (2 characters truncated) ... hat is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio ')]```
- After:
```[('Harrison', 'That is my Bio That is my Bio That is my Bio That is
my Bio That is my Bio That is my Bio That is my Bio That is my Bio That
is my Bio That is my Bio That is my Bio That is my Bio That is my Bio
That is my Bio That is my Bio That is my Bio That is my Bio That is my
Bio That is my Bio That is my Bio ')]```
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
I'm not sure who to tag for chains, maybe @vowelparrot ?
when the LLMs output 'yes|no',BooleanOutputParser can parse it to
'True|False', fix the ValueError in parse().
<!--
when use the BooleanOutputParser in the chain_filter.py, the LLMs output
'yes|no',the function 'parse' will throw ValueError。
-->
Fixes # (issue)
#5396https://github.com/hwchase17/langchain/issues/5396
---------
Co-authored-by: gaofeng27692 <gaofeng27692@hundsun.com>
# Add maximal relevance search to SKLearnVectorStore
This PR implements the maximum relevance search in SKLearnVectorStore.
Twitter handle: jtolgyesi (I submitted also the original implementation
of SKLearnVectorStore)
## Before submitting
Unit tests are included.
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Handles the edge scenario in which the action input is a well formed
SQL query which ends with a quoted column
There may be a cleaner option here (or indeed other edge scenarios) but
this seems to robustly determine if the action input is likely to be a
well formed SQL query in which we don't want to arbitrarily trim off `"`
characters
Fixes#5423
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Agents / Tools / Toolkits
- @vowelparrot
As the title says, I added more code splitters.
The implementation is trivial, so i don't add separate tests for each
splitter.
Let me know if any concerns.
Fixes # (issue)
https://github.com/hwchase17/langchain/issues/5170
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev @hwchase17
---------
Signed-off-by: byhsu <byhsu@linkedin.com>
Co-authored-by: byhsu <byhsu@linkedin.com>
# Creates GitHubLoader (#5257)
GitHubLoader is a DocumentLoader that loads issues and PRs from GitHub.
Fixes#5257
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Added New Trello loader class and documentation
Simple Loader on top of py-trello wrapper.
With a board name you can pull cards and to do some field parameter
tweaks on load operation.
I included documentation and examples.
Included unit test cases using patch and a fixture for py-trello client
class.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Add ToolException that a tool can throw
This is an optional exception that tool throws when execution error
occurs.
When this exception is thrown, the agent will not stop working,but will
handle the exception according to the handle_tool_error variable of the
tool,and the processing result will be returned to the agent as
observation,and printed in pink on the console.It can be used like this:
```python
from langchain.schema import ToolException
from langchain import LLMMathChain, SerpAPIWrapper, OpenAI
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI
from langchain.tools import BaseTool, StructuredTool, Tool, tool
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0)
llm_math_chain = LLMMathChain(llm=llm, verbose=True)
class Error_tool:
def run(self, s: str):
raise ToolException('The current search tool is not available.')
def handle_tool_error(error) -> str:
return "The following errors occurred during tool execution:"+str(error)
search_tool1 = Error_tool()
search_tool2 = SerpAPIWrapper()
tools = [
Tool.from_function(
func=search_tool1.run,
name="Search_tool1",
description="useful for when you need to answer questions about current events.You should give priority to using it.",
handle_tool_error=handle_tool_error,
),
Tool.from_function(
func=search_tool2.run,
name="Search_tool2",
description="useful for when you need to answer questions about current events",
return_direct=True,
)
]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True,
handle_tool_errors=handle_tool_error)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
```

## Who can review?
- @vowelparrot
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Implemented appending arbitrary messages to the base chat message
history, the in-memory and cosmos ones.
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
As discussed this is the alternative way instead of #4480, with a
add_message method added that takes a BaseMessage as input, so that the
user can control what is in the base message like kwargs.
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Fix lost mimetype when using Blob.from_data method
The mimetype is lost due to a typo in the class attribue name
Fixes # - (no issue opened but I can open one if needed)
## Changes
* Fixed typo in name
* Added unit-tests to validate the output Blob
## Review
@eyurtsev
# Add path validation to DirectoryLoader
This PR introduces a minor adjustment to the DirectoryLoader by adding
validation for the path argument. Previously, if the provided path
didn't exist or wasn't a directory, DirectoryLoader would return an
empty document list due to the behavior of the `glob` method. This could
potentially cause confusion for users, as they might expect a
file-loading error instead.
So, I've added two validations to the load method of the
DirectoryLoader:
- Raise a FileNotFoundError if the provided path does not exist
- Raise a ValueError if the provided path is not a directory
Due to the relatively small scope of these changes, a new issue was not
created.
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev
# Add SKLearnVectorStore
This PR adds SKLearnVectorStore, a simply vector store based on
NearestNeighbors implementations in the scikit-learn package. This
provides a simple drop-in vector store implementation with minimal
dependencies (scikit-learn is typically installed in a data scientist /
ml engineer environment). The vector store can be persisted and loaded
from json, bson and parquet format.
SKLearnVectorStore has soft (dynamic) dependency on the scikit-learn,
numpy and pandas packages. Persisting to bson requires the bson package,
persisting to parquet requires the pyarrow package.
## Before submitting
Integration tests are provided under
`tests/integration_tests/vectorstores/test_sklearn.py`
Sample usage notebook is provided under
`docs/modules/indexes/vectorstores/examples/sklear.ipynb`
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
zep-python's sync methods no longer need an asyncio wrapper. This was
causing issues with FastAPI deployment.
Zep also now supports putting and getting of arbitrary message metadata.
Bump zep-python version to v0.30
Remove nest-asyncio from Zep example notebooks.
Modify tests to include metadata.
---------
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
Co-authored-by: Daniel Chalef <131175+danielchalef@users.noreply.github.com>
# Bibtex integration
Wrap bibtexparser to retrieve a list of docs from a bibtex file.
* Get the metadata from the bibtex entries
* `page_content` get from the local pdf referenced in the `file` field
of the bibtex entry using `pymupdf`
* If no valid pdf file, `page_content` set to the `abstract` field of
the bibtex entry
* Support Zotero flavour using regex to get the file path
* Added usage example in
`docs/modules/indexes/document_loaders/examples/bibtex.ipynb`
---------
Co-authored-by: Sébastien M. Popoff <sebastien.popoff@espci.fr>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
## Description
The html structure of readthedocs can differ. Currently, the html tag is
hardcoded in the reader, and unable to fit into some cases. This pr
includes the following changes:
1. Replace `find_all` with `find` because we just want one tag.
2. Provide `custom_html_tag` to the loader.
3. Add tests for readthedoc loader
4. Refactor code
## Issues
See more in https://github.com/hwchase17/langchain/pull/2609. The
problem was not completely fixed in that pr.
---------
Signed-off-by: byhsu <byhsu@linkedin.com>
Co-authored-by: byhsu <byhsu@linkedin.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# OpanAI finetuned model giving zero tokens cost
Very simple fix to the previously committed solution to allowing
finetuned Openai models.
Improves #5127
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Add AzureCognitiveServicesToolkit to call Azure Cognitive Services
API: achieve some multimodal capabilities
This PR adds a toolkit named AzureCognitiveServicesToolkit which bundles
the following tools:
- AzureCogsImageAnalysisTool: calls Azure Cognitive Services image
analysis API to extract caption, objects, tags, and text from images.
- AzureCogsFormRecognizerTool: calls Azure Cognitive Services form
recognizer API to extract text, tables, and key-value pairs from
documents.
- AzureCogsSpeech2TextTool: calls Azure Cognitive Services speech to
text API to transcribe speech to text.
- AzureCogsText2SpeechTool: calls Azure Cognitive Services text to
speech API to synthesize text to speech.
This toolkit can be used to process image, document, and audio inputs.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Improve TextSplitter.split_documents, collect page_content and
metadata in one iteration
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev In the case where documents is a generator that can only be
iterated once making this change is a huge help. Otherwise a silent
issue happens where metadata is empty for all documents when documents
is a generator. So we expand the argument from `List[Document]` to
`Union[Iterable[Document], Sequence[Document]]`
---------
Co-authored-by: Steven Tartakovsky <tartakovsky.developer@gmail.com>
# Add Mastodon toots loader.
Loader works either with public toots, or Mastodon app credentials. Toot
text and user info is loaded.
I've also added integration test for this new loader as it works with
public data, and a notebook with example output run now.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# PowerBI major refinement in working of tool and tweaks in the rest
I've gained some experience with more complex sets and the earlier
implementation had too many tries by the agent to create DAX, so
refactored the code to run the LLM to create dax based on a question and
then immediately run the same against the dataset, with retries and a
prompt that includes the error for the retry. This works much better!
Also did some other refactoring of the inner workings, making things
clearer, more concise and faster.
# Row-wise cosine similarity between two equal-width matrices and return
the max top_k score and index, the score all greater than
threshold_score.
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This is a highly optimized update to the pull request
https://github.com/hwchase17/langchain/pull/3269
Summary:
1) Added ability to MRKL agent to self solve the ValueError(f"Could not
parse LLM output: `{llm_output}`") error, whenever llm (especially
gpt-3.5-turbo) does not follow the format of MRKL Agent, while returning
"Action:" & "Action Input:".
2) The way I am solving this error is by responding back to the llm with
the messages "Invalid Format: Missing 'Action:' after 'Thought:'" &
"Invalid Format: Missing 'Action Input:' after 'Action:'" whenever
Action: and Action Input: are not present in the llm output
respectively.
For a detailed explanation, look at the previous pull request.
New Updates:
1) Since @hwchase17 , requested in the previous PR to communicate the
self correction (error) message, using the OutputParserException, I have
added new ability to the OutputParserException class to store the
observation & previous llm_output in order to communicate it to the next
Agent's prompt. This is done, without breaking/modifying any of the
functionality OutputParserException previously performs (i.e.
OutputParserException can be used in the same way as before, without
passing any observation & previous llm_output too).
---------
Co-authored-by: Deepak S V <svdeepak99@users.noreply.github.com>
Update to pull request https://github.com/hwchase17/langchain/pull/3215
Summary:
1) Improved the sanitization of query (using regex), by removing python
command (since gpt-3.5-turbo sometimes assumes python console as a
terminal, and runs python command first which causes error). Also
sometimes 1 line python codes contain single backticks.
2) Added 7 new test cases.
For more details, view the previous pull request.
---------
Co-authored-by: Deepak S V <svdeepak99@users.noreply.github.com>
Extract the methods specific to running an LLM or Chain on a dataset to
separate utility functions.
This simplifies the client a bit and lets us separate concerns of LCP
details from running examples (e.g., for evals)
# Improve Evernote Document Loader
When exporting from Evernote you may export more than one note.
Currently the Evernote loader concatenates the content of all notes in
the export into a single document and only attaches the name of the
export file as metadata on the document.
This change ensures that each note is loaded as an independent document
and all available metadata on the note e.g. author, title, created,
updated are added as metadata on each document.
It also uses an existing optional dependency of `html2text` instead of
`pypandoc` to remove the need to download the pandoc application via
`download_pandoc()` to be able to use the `pypandoc` python bindings.
Fixes#4493
Co-authored-by: Mike McGarry <mike.mcgarry@finbourne.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Powerbi API wrapper bug fix + integration tests
- Bug fix by removing `TYPE_CHECKING` in in utilities/powerbi.py
- Added integration test for power bi api in
utilities/test_powerbi_api.py
- Added integration test for power bi agent in
agent/test_powerbi_agent.py
- Edited .env.examples to help set up power bi related environment
variables
- Updated demo notebook with working code in
docs../examples/powerbi.ipynb - AzureOpenAI -> ChatOpenAI
Notes:
Chat models (gpt3.5, gpt4) are much more capable than davinci at writing
DAX queries, so that is important to getting the agent to work properly.
Interestingly, gpt3.5-turbo needed the examples=DEFAULT_FEWSHOT_EXAMPLES
to write consistent DAX queries, so gpt4 seems necessary as the smart
llm.
Fixes#4325
## Before submitting
Azure-core and Azure-identity are necessary dependencies
check integration tests with the following:
`pytest tests/integration_tests/utilities/test_powerbi_api.py`
`pytest tests/integration_tests/agent/test_powerbi_agent.py`
You will need a power bi account with a dataset id + table name in order
to test. See .env.examples for details.
## Who can review?
@hwchase17
@vowelparrot
---------
Co-authored-by: aditya-pethe <adityapethe1@gmail.com>
# Add Spark SQL support
* Add Spark SQL support. It can connect to Spark via building a
local/remote SparkSession.
* Include a notebook example
I tried some complicated queries (window function, table joins), and the
tool works well.
Compared to the [Spark Dataframe
agent](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/spark.html),
this tool is able to generate queries across multiple tables.
---------
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Gengliang Wang <gengliang@apache.org>
Co-authored-by: Mike W <62768671+skcoirz@users.noreply.github.com>
Co-authored-by: Eugene Yurtsev <eyurtsev@gmail.com>
Co-authored-by: UmerHA <40663591+UmerHA@users.noreply.github.com>
Co-authored-by: 张城铭 <z@hyperf.io>
Co-authored-by: assert <zhangchengming@kkguan.com>
Co-authored-by: blob42 <spike@w530>
Co-authored-by: Yuekai Zhang <zhangyuekai@foxmail.com>
Co-authored-by: Richard He <he.yucheng@outlook.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Co-authored-by: Leonid Ganeline <leo.gan.57@gmail.com>
Co-authored-by: Alexey Nominas <60900649+Chae4ek@users.noreply.github.com>
Co-authored-by: elBarkey <elbarkey@gmail.com>
Co-authored-by: Davis Chase <130488702+dev2049@users.noreply.github.com>
Co-authored-by: Jeffrey D <1289344+verygoodsoftwarenotvirus@users.noreply.github.com>
Co-authored-by: so2liu <yangliu35@outlook.com>
Co-authored-by: Viswanadh Rayavarapu <44315599+vishwa-rn@users.noreply.github.com>
Co-authored-by: Chakib Ben Ziane <contact@blob42.xyz>
Co-authored-by: Daniel Chalef <131175+danielchalef@users.noreply.github.com>
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
Co-authored-by: Jari Bakken <jari.bakken@gmail.com>
Co-authored-by: escafati <scafatieugenio@gmail.com>
# Zep Retriever - Vector Search Over Chat History with the Zep Long-term
Memory Service
More on Zep: https://github.com/getzep/zep
Note: This PR is related to and relies on
https://github.com/hwchase17/langchain/pull/4834. I did not want to
modify the `pyproject.toml` file to add the `zep-python` dependency a
second time.
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
# TextLoader auto detect encoding and enhanced exception handling
- Add an option to enable encoding detection on `TextLoader`.
- The detection is done using `chardet`
- The loading is done by trying all detected encodings by order of
confidence or raise an exception otherwise.
### New Dependencies:
- `chardet`
Fixes#4479
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
- @eyurtsev
---------
Co-authored-by: blob42 <spike@w530>
# Add bs4 html parser
* Some minor refactors
* Extract the bs4 html parsing code from the bs html loader
* Move some tests from integration tests to unit tests
# Add generic document loader
* This PR adds a generic document loader which can assemble a loader
from a blob loader and a parser
* Adds a registry for parsers
* Populate registry with a default mimetype based parser
## Expected changes
- Parsing involves loading content via IO so can be sped up via:
* Threading in sync
* Async
- The actual parsing logic may be computatinoally involved: may need to
figure out to add multi-processing support
- May want to add suffix based parser since suffixes are easier to
specify in comparison to mime types
## Before submitting
No notebooks yet, we first need to get a few of the basic parsers up
(prior to advertising the interface)
Previously, the client expected a strict 'prompt' or 'messages' format
and wouldn't permit running a chat model or llm on prompts or messages
(respectively).
Since many datasets may want to specify custom key: string , relax this
requirement.
Also, add support for running a chat model on raw prompts and LLM on
chat messages through their respective fallbacks.
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
**Feature**: This PR adds `from_template_file` class method to
BaseStringMessagePromptTemplate. This is useful to help user to create
message prompt templates directly from template files, including
`ChatMessagePromptTemplate`, `HumanMessagePromptTemplate`,
`AIMessagePromptTemplate` & `SystemMessagePromptTemplate`.
**Tests**: Unit tests have been added in this PR.
Co-authored-by: charosen <charosen@bupt.cn>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Adds some basic unit tests for the ConfluenceLoader that can be extended
later. Ports this [PR from
llama-hub](https://github.com/emptycrown/llama-hub/pull/208) and adapts
it to `langchain`.
@Jflick58 and @zywilliamli adding you here as potential reviewers
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Fix Telegram API loader + add tests.
I was testing this integration and it was broken with next error:
```python
message_threads = loader._get_message_threads(df)
KeyError: False
```
Also, this particular loader didn't have any tests / related group in
poetry, so I added those as well.
@hwchase17 / @eyurtsev please take a look on this fix PR.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>