# Scores in Vectorestores' Docs Are Explained
Following vectorestores can return scores with similar documents by
using `similarity_search_with_score`:
- chroma
- docarray_hnsw
- docarray_in_memory
- faiss
- myscale
- qdrant
- supabase
- vectara
- weaviate
However, in documents, these scores were either not explained at all or
explained in a way that could lead to misunderstandings (e.g., FAISS).
For instance in FAISS document: if we consider the score returned by the
function as a similarity score, we understand that a document returning
a higher score is more similar to the source document. However, since
the scores returned by the function are distance scores, we should
understand that smaller scores correspond to more similar documents.
For the libraries other than Vectara, I wrote the scores they use by
investigating from the source libraries. Since I couldn't be certain
about the score metric used by Vectara, I didn't make any changes in its
documentation. The links mentioned in Vectara's documentation became
broken due to updates, so I replaced them with working ones.
VectorStores / Retrievers / Memory
- @dev2049
my twitter: [berkedilekoglu](https://twitter.com/berkedilekoglu)
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Added an overview of LangChain modules
Aimed at introducing newcomers to LangChain's main modules :)
Twitter handle is @edrick_dch
## Who can review?
@eyurtsev
Fixes#5614
#### Issue
The `***` combination produces an exception when used as a seperator in
`re.split`. Instead `\*\*\*` should be used for regex exprations.
#### Who can review?
@eyurtsev
Fixes#5699
#### Who can review?
Tag maintainers/contributors who might be interested:
@woodworker @LeSphax @johannhartmann
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
…719)
A minor update to retry Cohore API call in case of errors using tenacity
as it is done for OpenAI LLMs.
#### Who can review?
@hwchase17, @agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Sagar Sapkota <22609549+sagar-spkt@users.noreply.github.com>
Aviary is an open source toolkit for evaluating and deploying open
source LLMs. You can find out more about it on
[http://github.com/ray-project/aviary). You can try it out at
[http://aviary.anyscale.com](aviary.anyscale.com).
This code adds support for Aviary in LangChain. To minimize
dependencies, it connects directly to the HTTP endpoint.
The current implementation is not accelerated and uses the default
implementation of `predict` and `generate`.
It includes a test and a simple example.
@hwchase17 and @agola11 could you have a look at this?
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
Adding a class attribute "return_generated_question" to class
"BaseConversationalRetrievalChain". If set to `True`, the chain's output
has a key "generated_question" with the question generated by the
sub-chain `question_generator` as the value. This way the generated
question can be logged.
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@dev2049 @vowelparrot
# OpenAIWhisperParser
This PR creates a new parser, `OpenAIWhisperParser`, that uses the
[OpenAI Whisper
model](https://platform.openai.com/docs/guides/speech-to-text/quickstart)
to perform transcription of audio files to text (`Documents`). Please
see the notebook for usage.
Fixed python deprecation warning:
DeprecationWarning: invalid escape sequence '`'
backticks (`) do not have special meaning in python strings and should
not be escaped.
-- @spazm on twitter
### Who can review:
@nfcampos ported this change from javascript, @hwchase17 wrote the
original STRUCTURED_FORMAT_INSTRUCTIONS,
Zep now supports persisting custom metadata with messages and hybrid
search across both message embeddings and structured metadata. This PR
implements custom metadata and enhancements to the
`ZepChatMessageHistory` and `ZepRetriever` classes to implement this
support.
Tag maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
---------
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
# Check if generated Cypher code is wrapped in backticks
Some LLMs like the VertexAI like to explain how they generated the
Cypher statement and wrap the actual code in three backticks:
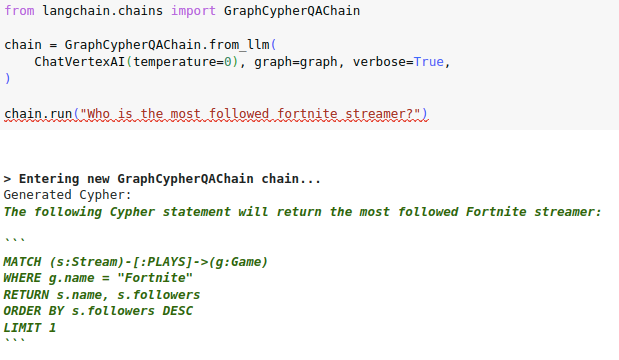
I have observed a similar pattern with OpenAI chat models in a
conversational settings, where multiple user and assistant message are
provided to the LLM to generate Cypher statements, where then the LLM
wants to maybe apologize for previous steps or explain its thoughts.
Interestingly, both OpenAI and VertexAI wrap the code in three backticks
if they are doing any explaining or apologizing. Checking if the
generated cypher is wrapped in backticks seems like a low-hanging fruit
to expand the cypher search to other LLMs and conversational settings.
# Adding support to save multiple memories at a time. Cuts save time by
more then half
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
-
VectorStores / Retrievers / Memory
- @dev2049
-->
@dev2049
@vowelparrot
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Fixes#5720.
A more in-depth discussion is in my comment here:
https://github.com/hwchase17/langchain/issues/5720#issuecomment-1577047018
In a nutshell, there has been a subtle change in the latest version of
GPT4Alls Python bindings. The change I submitted yesterday is compatible
with this version, however, this version is as of yet unreleased and
thus the code change breaks Langchain's wrapper under the currently
released version of GPT4All.
This pull request proposes a backwards-compatible solution.
fix for the sqlalchemy deprecated declarative_base import :
```
MovedIn20Warning: The ``declarative_base()`` function is now available as sqlalchemy.orm.declarative_base(). (deprecated since: 2.0) (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9)
Base = declarative_base() # type: Any
```
Import is wrapped in an try catch Block to fallback to the old import if
needed.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Token text splitter for sentence transformers
The current TokenTextSplitter only works with OpenAi models via the
`tiktoken` package. This is not clear from the name `TokenTextSplitter`.
In this (first PR) a token based text splitter for sentence transformer
models is added. In the future I think we should work towards injecting
a tokenizer into the TokenTextSplitter to make ti more flexible.
Could perhaps be reviewed by @dev2049
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Raises exception if OutputParsers receive a response with both a valid
action and a final answer
Currently, if an OutputParser receives a response which includes both an
action and a final answer, they return a FinalAnswer object. This allows
the parser to accept responses which propose an action and hallucinate
an answer without the action being parsed or taken by the agent.
This PR changes the logic to:
1. store a variable checking whether a response contains the
`FINAL_ANSWER_ACTION` (this is the easier condition to check).
2. store a variable checking whether the response contains a valid
action
3. if both are present, raise a new exception stating that both are
present
4. if an action is present, return an AgentAction
5. if an answer is present, return an AgentAnswer
6. if neither is present, raise the relevant exception based around the
action format (these have been kept consistent with the prior exception
messages)
Disclaimer:
* Existing mock data included strings which did include an action and an
answer. This might indicate that prioritising returning AgentAnswer was
always correct, and I am patching out desired behaviour? @hwchase17 to
advice. Curious if there are allowed cases where this is not
hallucinating, and we do want the LLM to output an action which isn't
taken.
* I have not passed `send_to_llm` through this new exception
Fixes#5601
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@hwchase17 - project lead
@vowelparrot
All the queries to the database are done based on the SessionId
property, this will optimize how Mongo retrieves all messages from a
session
#### Who can review?
Tag maintainers/contributors who might be interested:
@dev2049
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes#5638. Retitles "Amazon Bedrock" page to "Bedrock" so that the
Integrations section of the left nav is properly sorted in alphabetical
order.
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@vowelparrot:
Minor change to the SQL agent:
Tells agent to introspect the schema of the most relevant tables, I
found this to dramatically decrease the chance that the agent wastes
times guessing column names.
Fixes https://github.com/hwchase17/langchain/issues/5067
Verified the following code now works correctly:
```
db = Chroma(persist_directory=index_directory(index_name), embedding_function=embeddings)
retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.4})
docs = retriever.get_relevant_documents(query)
```
## Improve Error Messaging for APOC Procedure Failure in Neo4jGraph
This commit revises the error message provided when the
'apoc.meta.data()' procedure fails. Previously, the message simply
instructed the user to install the APOC plugin in Neo4j. The new error
message is more specific.
Also removed an unnecessary newline in the Cypher statement variable:
`node_properties_query`.
Fixes#5545
## Who can review?
- @vowelparrot
- @dev2049
This commit addresses a ValueError occurring when the YoutubeLoader
class tries to add datetime metadata from a YouTube video's publish
date. The error was happening because the ChromaDB metadata validation
only accepts str, int, or float data types.
In the `_get_video_info` method of the `YoutubeLoader` class, the
publish date retrieved from the YouTube video was of datetime type. This
commit fixes the issue by converting the datetime object to a string
before adding it to the metadata dictionary.
Additionally, this commit introduces error handling in the
`_get_video_info` method to ensure that all metadata fields have valid
values. If a metadata field is found to be None, a default value is
assigned. This prevents potential errors during metadata validation when
metadata fields are None.
The file modified in this commit is youtube.py.
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# refactor BaseStringMessagePromptTemplate from_template method
Refactor the `from_template` method of the
`BaseStringMessagePromptTemplate` class to allow passing keyword
arguments to the `from_template` method of `PromptTemplate`.
Enable the usage of arguments like `template_format`.
In my scenario, I intend to utilize Jinja2 for formatting the human
message prompt in the chat template.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Models
- @hwchase17
- @agola11
- @jonasalexander
-->
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# like
[StdoutCallbackHandler](https://github.com/hwchase17/langchain/blob/master/langchain/callbacks/stdout.py),
but writes to a file
When running experiments I have found myself wanting to log the outputs
of my chains in a more lightweight way than using WandB tracing. This PR
contributes a callback handler that writes to file what
`StdoutCallbackHandler` would print.
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
## Example Notebook
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
See the included `filecallbackhandler.ipynb` notebook for usage. Would
it be better to include this notebook under `modules/callbacks` or under
`integrations/`?
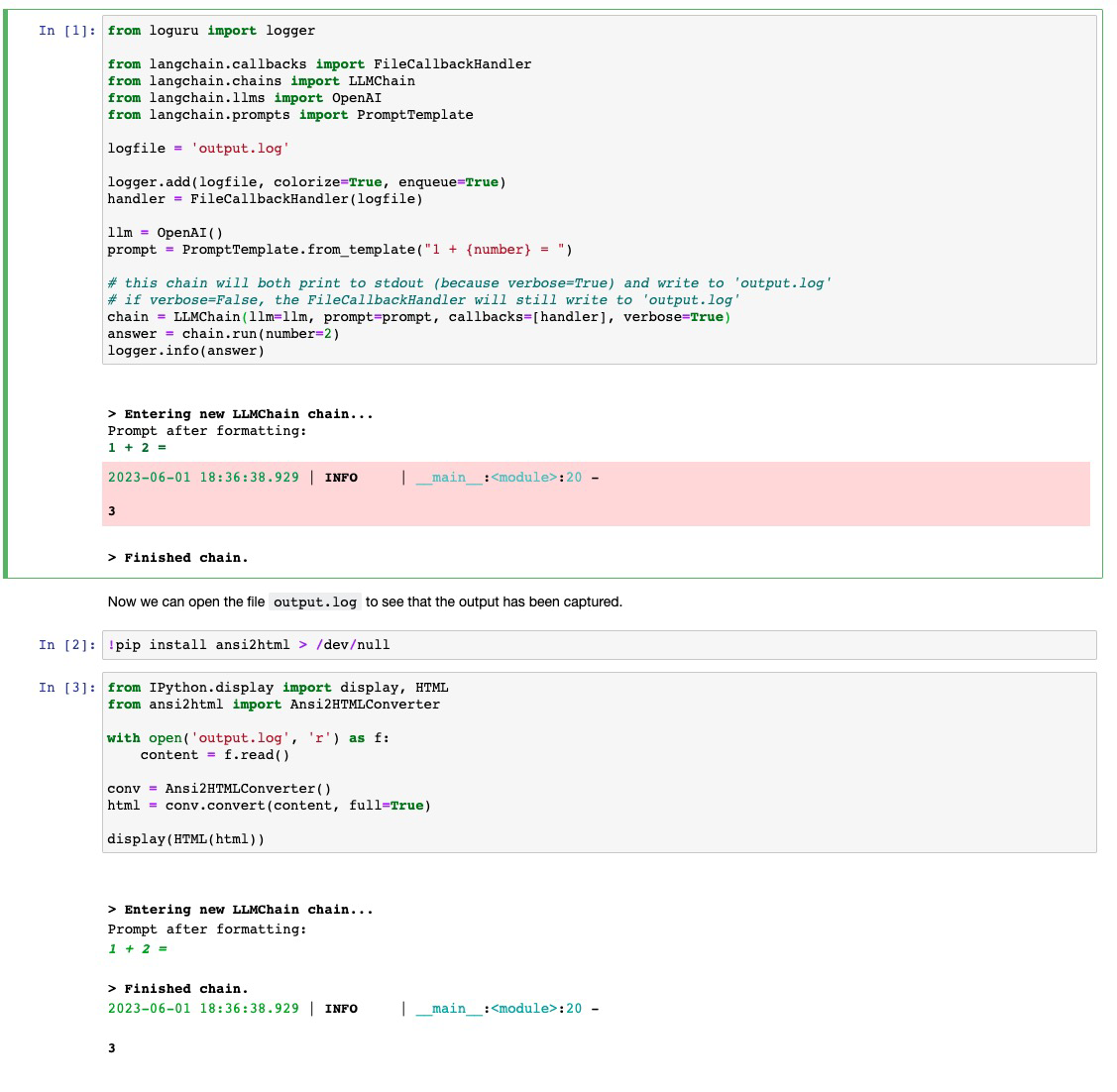
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Created fix for 5475
Currently in PGvector, we do not have any function that returns the
instance of an existing store. The from_documents always adds embeddings
and then returns the store. This fix is to add a function that will
return the instance of an existing store
Also changed the jupyter example for PGVector to show the example of
using the function
<!-- Remove if not applicable -->
Fixes # 5475
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
@dev2049
@hwchase17
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: rajib76 <rajib76@yahoo.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This PR corrects a minor typo in the Momento chat message history
notebook and also expands the title from "Momento" to "Momento Chat
History", inline with other chat history storage providers.
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
cc @dev2049 who reviewed the original integration
# Your PR Title (What it does)
Fixes the pgvector python example notebook : one of the variables was
not referencing anything
## Before submitting
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
# Ensure parameters are used by vertexai chat models (PaLM2)
The current version of the google aiplatform contains a bug where
parameters for a chat model are not used as intended.
See https://github.com/googleapis/python-aiplatform/issues/2263
Params can be passed both to start_chat() and send_message(); however,
the parameters passed to start_chat() will not be used if send_message()
is called without the overrides. This is due to the defaults in
send_message() being global values rather than None (there is code in
send_message() which would use the params from start_chat() if the param
passed to send_message() evaluates to False, but that won't happen as
the defaults are global values).
Fixes # 5531
@hwchase17
@agola11
# Make FinalStreamingStdOutCallbackHandler more robust by ignoring new
lines & white spaces
`FinalStreamingStdOutCallbackHandler` doesn't work out of the box with
`ChatOpenAI`, as it tokenized slightly differently than `OpenAI`. The
response of `OpenAI` contains the tokens `["\nFinal", " Answer", ":"]`
while `ChatOpenAI` contains `["Final", " Answer", ":"]`.
This PR make `FinalStreamingStdOutCallbackHandler` more robust by
ignoring new lines & white spaces when determining if the answer prefix
has been reached.
Fixes#5433
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
Tracing / Callbacks
- @agola11
Twitter: [@UmerHAdil](https://twitter.com/@UmerHAdil) | Discord:
RicChilligerDude#7589