# Token text splitter for sentence transformers
The current TokenTextSplitter only works with OpenAi models via the
`tiktoken` package. This is not clear from the name `TokenTextSplitter`.
In this (first PR) a token based text splitter for sentence transformer
models is added. In the future I think we should work towards injecting
a tokenizer into the TokenTextSplitter to make ti more flexible.
Could perhaps be reviewed by @dev2049
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes#5638. Retitles "Amazon Bedrock" page to "Bedrock" so that the
Integrations section of the left nav is properly sorted in alphabetical
order.
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# like
[StdoutCallbackHandler](https://github.com/hwchase17/langchain/blob/master/langchain/callbacks/stdout.py),
but writes to a file
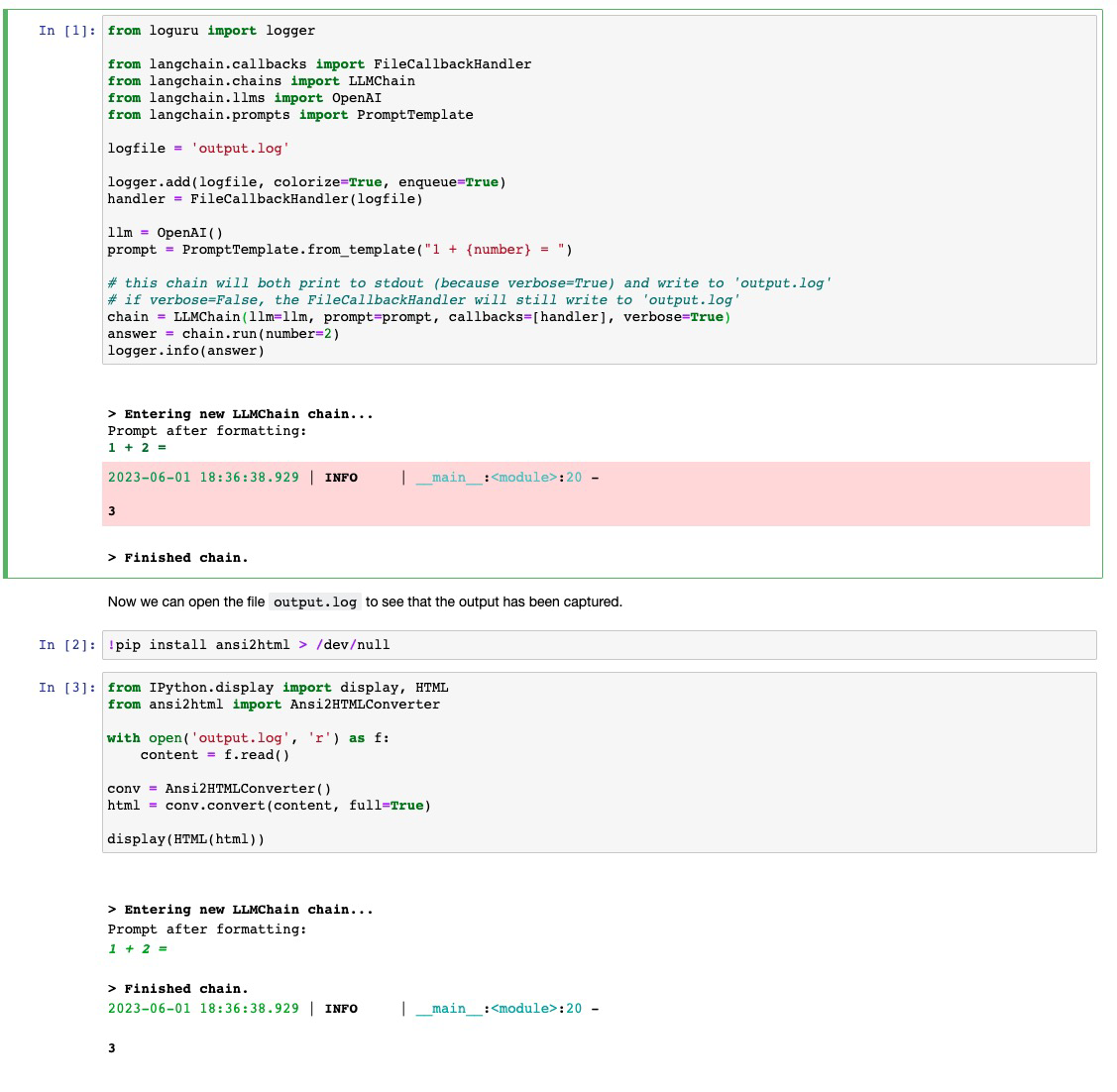
When running experiments I have found myself wanting to log the outputs
of my chains in a more lightweight way than using WandB tracing. This PR
contributes a callback handler that writes to file what
`StdoutCallbackHandler` would print.
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
## Example Notebook
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
See the included `filecallbackhandler.ipynb` notebook for usage. Would
it be better to include this notebook under `modules/callbacks` or under
`integrations/`?
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Created fix for 5475
Currently in PGvector, we do not have any function that returns the
instance of an existing store. The from_documents always adds embeddings
and then returns the store. This fix is to add a function that will
return the instance of an existing store
Also changed the jupyter example for PGVector to show the example of
using the function
<!-- Remove if not applicable -->
Fixes # 5475
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
@dev2049
@hwchase17
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: rajib76 <rajib76@yahoo.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This PR corrects a minor typo in the Momento chat message history
notebook and also expands the title from "Momento" to "Momento Chat
History", inline with other chat history storage providers.
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
cc @dev2049 who reviewed the original integration
# Your PR Title (What it does)
Fixes the pgvector python example notebook : one of the variables was
not referencing anything
## Before submitting
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
# Make FinalStreamingStdOutCallbackHandler more robust by ignoring new
lines & white spaces
`FinalStreamingStdOutCallbackHandler` doesn't work out of the box with
`ChatOpenAI`, as it tokenized slightly differently than `OpenAI`. The
response of `OpenAI` contains the tokens `["\nFinal", " Answer", ":"]`
while `ChatOpenAI` contains `["Final", " Answer", ":"]`.
This PR make `FinalStreamingStdOutCallbackHandler` more robust by
ignoring new lines & white spaces when determining if the answer prefix
has been reached.
Fixes#5433
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
Tracing / Callbacks
- @agola11
Twitter: [@UmerHAdil](https://twitter.com/@UmerHAdil) | Discord:
RicChilligerDude#7589
# Implements support for Personal Access Token Authentication in the
ConfluenceLoader
Fixes#5191
Implements a new optional parameter for the ConfluenceLoader: `token`.
This allows the use of personal access authentication when using the
on-prem server version of Confluence.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev @Jflick58
Twitter Handle: felipe_yyc
---------
Co-authored-by: Felipe <feferreira@ea.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# minor refactor of GenerativeAgentMemory
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
- refactor `format_memories_detail` to be more reusable
- modified prompts for getting topics for reflection and for generating
insights
- update `characters.ipynb` to reflect changes
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@vowelparrot
@hwchase17
@dev2049
# docs: modules pages simplified
Fixied #5627 issue
Merged several repetitive sections in the `modules` pages. Some texts,
that were hard to understand, were also simplified.
## Who can review?
@hwchase17
@dev2049
# Fixed multi input prompt for MapReduceChain
Added `kwargs` support for inner chains of `MapReduceChain` via
`from_params` method
Currently the `from_method` method of intialising `MapReduceChain` chain
doesn't work if prompt has multiple inputs. It happens because it uses
`StuffDocumentsChain` and `MapReduceDocumentsChain` underneath, both of
them require specifying `document_variable_name` if `prompt` of their
`llm_chain` has more than one `input`.
With this PR, I have added support for passing their respective `kwargs`
via the `from_params` method.
## Fixes https://github.com/hwchase17/langchain/issues/4752
## Who can review?
@dev2049 @hwchase17 @agola11
---------
Co-authored-by: imeckr <chandanroutray2012@gmail.com>
# Unstructured Excel Loader
Adds an `UnstructuredExcelLoader` class for `.xlsx` and `.xls` files.
Works with `unstructured>=0.6.7`. A plain text representation of the
Excel file will be available under the `page_content` attribute in the
doc. If you use the loader in `"elements"` mode, an HTML representation
of the Excel file will be available under the `text_as_html` metadata
key. Each sheet in the Excel document is its own document.
### Testing
```python
from langchain.document_loaders import UnstructuredExcelLoader
loader = UnstructuredExcelLoader(
"example_data/stanley-cups.xlsx",
mode="elements"
)
docs = loader.load()
```
## Who can review?
@hwchase17
@eyurtsev
Co-authored-by: Alvaro Bartolome <alvarobartt@gmail.com>
Co-authored-by: Daniel Vila Suero <daniel@argilla.io>
Co-authored-by: Tom Aarsen <37621491+tomaarsen@users.noreply.github.com>
Co-authored-by: Tom Aarsen <Cubiegamedev@gmail.com>
# Create elastic_vector_search.ElasticKnnSearch class
This extends `langchain/vectorstores/elastic_vector_search.py` by adding
a new class `ElasticKnnSearch`
Features:
- Allow creating an index with the `dense_vector` mapping compataible
with kNN search
- Store embeddings in index for use with kNN search (correct mapping
creates HNSW data structure)
- Perform approximate kNN search
- Perform hybrid BM25 (`query{}`) + kNN (`knn{}`) search
- perform knn search by either providing a `query_vector` or passing a
hosted `model_id` to use query_vector_builder to automatically generate
a query_vector at search time
Connection options
- Using `cloud_id` from Elastic Cloud
- Passing elasticsearch client object
search options
- query
- k
- query_vector
- model_id
- size
- source
- knn_boost (hybrid search)
- query_boost (hybrid search)
- fields
This also adds examples to
`docs/modules/indexes/vectorstores/examples/elasticsearch.ipynb`
Fixes # [5346](https://github.com/hwchase17/langchain/issues/5346)
cc: @dev2049
-->
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Lint sphinx documentation and fix broken links
This PR lints multiple warnings shown in generation of the project
documentation (using "make docs_linkcheck" and "make docs_build").
Additionally documentation internal links to (now?) non-existent files
are modified to point to existing documents as it seemed the new correct
target.
The documentation is not updated content wise.
There are no source code changes.
Fixes # (issue)
- broken documentation links to other files within the project
- sphinx formatting (linting)
## Before submitting
No source code changes, so no new tests added.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# docs: `ecosystem_integrations` update 3
Next cycle of updating the `ecosystem/integrations`
* Added an integration `template` file
* Added missed integration files
* Fixed several document_loaders/notebooks
## Who can review?
Is it possible to assign somebody to review PRs on docs? Thanks.
# Fix wrong class instantiation in docs MMR example
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
When looking at the Maximal Marginal Relevance ExampleSelector example
at
https://python.langchain.com/en/latest/modules/prompts/example_selectors/examples/mmr.html,
I noticed that there seems to be an error. Initially, the
`MaxMarginalRelevanceExampleSelector` class is used as an
`example_selector` argument to the `FewShotPromptTemplate` class. Then,
according to the text, a comparison is made to regular similarity
search. However, the `FewShotPromptTemplate` still uses the
`MaxMarginalRelevanceExampleSelector` class, so the output is the same.
To fix it, I added an instantiation of the
`SemanticSimilarityExampleSelector` class, because this seems to be what
is intended.
## Who can review?
@hwchase17
# Update Unstructured docs to remove the `detectron2` install
instructions
Removes `detectron2` installation instructions from the Unstructured
docs because installing `detectron2` is no longer required for
`unstructured>=0.7.0`. The `detectron2` model now runs using the ONNX
runtime.
## Who can review?
@hwchase17
@eyurtsev
# Add Managed Motorhead
This change enabled MotorheadMemory to utilize Metal's managed version
of Motorhead. We can easily enable this by passing in a `api_key` and
`client_id` in order to hit the managed url and access the memory api on
Metal.
Twitter: [@softboyjimbo](https://twitter.com/softboyjimbo)
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@dev2049 @hwchase17
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# added DeepLearing.AI course link
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
not @hwchase17 - hehe
# Bedrock LLM and Embeddings
This PR adds a new LLM and an Embeddings class for the
[Bedrock](https://aws.amazon.com/bedrock) service. The PR also includes
example notebooks for using the LLM class in a conversation chain and
embeddings usage in creating an embedding for a query and document.
**Note**: AWS is doing a private release of the Bedrock service on
05/31/2023; users need to request access and added to an allowlist in
order to start using the Bedrock models and embeddings. Please use the
[Bedrock Home Page](https://aws.amazon.com/bedrock) to request access
and to learn more about the models available in Bedrock.
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# Support Qdrant filters
Qdrant has an [extensive filtering
system](https://qdrant.tech/documentation/concepts/filtering/) with rich
type support. This PR makes it possible to use the filters in Langchain
by passing an additional param to both the
`similarity_search_with_score` and `similarity_search` methods.
## Who can review?
@dev2049 @hwchase17
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# SQLite-backed Entity Memory
Following the initiative of
https://github.com/hwchase17/langchain/pull/2397 I think it would be
helpful to be able to persist Entity Memory on disk by default
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This PR adds a new method `from_es_connection` to the
`ElasticsearchEmbeddings` class allowing users to use Elasticsearch
clusters outside of Elastic Cloud.
Users can create an Elasticsearch Client object and pass that to the new
function.
The returned object is identical to the one returned by calling
`from_credentials`
```
# Create Elasticsearch connection
es_connection = Elasticsearch(
hosts=['https://es_cluster_url:port'],
basic_auth=('user', 'password')
)
# Instantiate ElasticsearchEmbeddings using es_connection
embeddings = ElasticsearchEmbeddings.from_es_connection(
model_id,
es_connection,
)
```
I also added examples to the elasticsearch jupyter notebook
Fixes # https://github.com/hwchase17/langchain/issues/5239
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
As the title says, I added more code splitters.
The implementation is trivial, so i don't add separate tests for each
splitter.
Let me know if any concerns.
Fixes # (issue)
https://github.com/hwchase17/langchain/issues/5170
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev @hwchase17
---------
Signed-off-by: byhsu <byhsu@linkedin.com>
Co-authored-by: byhsu <byhsu@linkedin.com>
# Creates GitHubLoader (#5257)
GitHubLoader is a DocumentLoader that loads issues and PRs from GitHub.
Fixes#5257
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>