# OpenAIWhisperParser
This PR creates a new parser, `OpenAIWhisperParser`, that uses the
[OpenAI Whisper
model](https://platform.openai.com/docs/guides/speech-to-text/quickstart)
to perform transcription of audio files to text (`Documents`). Please
see the notebook for usage.
# Token text splitter for sentence transformers
The current TokenTextSplitter only works with OpenAi models via the
`tiktoken` package. This is not clear from the name `TokenTextSplitter`.
In this (first PR) a token based text splitter for sentence transformer
models is added. In the future I think we should work towards injecting
a tokenizer into the TokenTextSplitter to make ti more flexible.
Could perhaps be reviewed by @dev2049
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes#5638. Retitles "Amazon Bedrock" page to "Bedrock" so that the
Integrations section of the left nav is properly sorted in alphabetical
order.
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
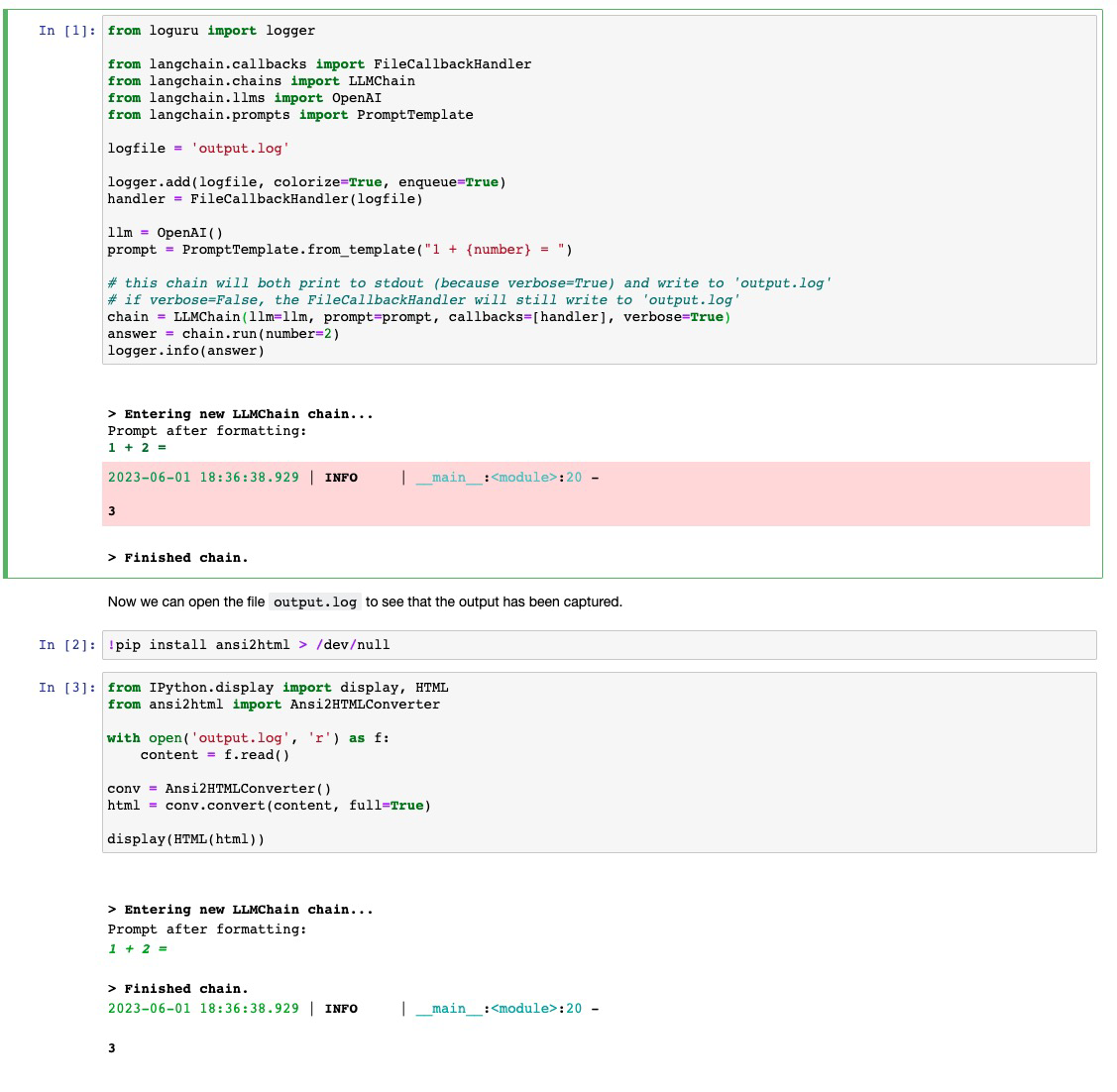
# like
[StdoutCallbackHandler](https://github.com/hwchase17/langchain/blob/master/langchain/callbacks/stdout.py),
but writes to a file
When running experiments I have found myself wanting to log the outputs
of my chains in a more lightweight way than using WandB tracing. This PR
contributes a callback handler that writes to file what
`StdoutCallbackHandler` would print.
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
## Example Notebook
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
See the included `filecallbackhandler.ipynb` notebook for usage. Would
it be better to include this notebook under `modules/callbacks` or under
`integrations/`?
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Created fix for 5475
Currently in PGvector, we do not have any function that returns the
instance of an existing store. The from_documents always adds embeddings
and then returns the store. This fix is to add a function that will
return the instance of an existing store
Also changed the jupyter example for PGVector to show the example of
using the function
<!-- Remove if not applicable -->
Fixes # 5475
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
@dev2049
@hwchase17
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: rajib76 <rajib76@yahoo.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This PR corrects a minor typo in the Momento chat message history
notebook and also expands the title from "Momento" to "Momento Chat
History", inline with other chat history storage providers.
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
cc @dev2049 who reviewed the original integration
# Your PR Title (What it does)
Fixes the pgvector python example notebook : one of the variables was
not referencing anything
## Before submitting
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
# Make FinalStreamingStdOutCallbackHandler more robust by ignoring new
lines & white spaces
`FinalStreamingStdOutCallbackHandler` doesn't work out of the box with
`ChatOpenAI`, as it tokenized slightly differently than `OpenAI`. The
response of `OpenAI` contains the tokens `["\nFinal", " Answer", ":"]`
while `ChatOpenAI` contains `["Final", " Answer", ":"]`.
This PR make `FinalStreamingStdOutCallbackHandler` more robust by
ignoring new lines & white spaces when determining if the answer prefix
has been reached.
Fixes#5433
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
Tracing / Callbacks
- @agola11
Twitter: [@UmerHAdil](https://twitter.com/@UmerHAdil) | Discord:
RicChilligerDude#7589
# Implements support for Personal Access Token Authentication in the
ConfluenceLoader
Fixes#5191
Implements a new optional parameter for the ConfluenceLoader: `token`.
This allows the use of personal access authentication when using the
on-prem server version of Confluence.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev @Jflick58
Twitter Handle: felipe_yyc
---------
Co-authored-by: Felipe <feferreira@ea.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# minor refactor of GenerativeAgentMemory
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
- refactor `format_memories_detail` to be more reusable
- modified prompts for getting topics for reflection and for generating
insights
- update `characters.ipynb` to reflect changes
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@vowelparrot
@hwchase17
@dev2049
# docs: modules pages simplified
Fixied #5627 issue
Merged several repetitive sections in the `modules` pages. Some texts,
that were hard to understand, were also simplified.
## Who can review?
@hwchase17
@dev2049
# Fixed multi input prompt for MapReduceChain
Added `kwargs` support for inner chains of `MapReduceChain` via
`from_params` method
Currently the `from_method` method of intialising `MapReduceChain` chain
doesn't work if prompt has multiple inputs. It happens because it uses
`StuffDocumentsChain` and `MapReduceDocumentsChain` underneath, both of
them require specifying `document_variable_name` if `prompt` of their
`llm_chain` has more than one `input`.
With this PR, I have added support for passing their respective `kwargs`
via the `from_params` method.
## Fixes https://github.com/hwchase17/langchain/issues/4752
## Who can review?
@dev2049 @hwchase17 @agola11
---------
Co-authored-by: imeckr <chandanroutray2012@gmail.com>
# Unstructured Excel Loader
Adds an `UnstructuredExcelLoader` class for `.xlsx` and `.xls` files.
Works with `unstructured>=0.6.7`. A plain text representation of the
Excel file will be available under the `page_content` attribute in the
doc. If you use the loader in `"elements"` mode, an HTML representation
of the Excel file will be available under the `text_as_html` metadata
key. Each sheet in the Excel document is its own document.
### Testing
```python
from langchain.document_loaders import UnstructuredExcelLoader
loader = UnstructuredExcelLoader(
"example_data/stanley-cups.xlsx",
mode="elements"
)
docs = loader.load()
```
## Who can review?
@hwchase17
@eyurtsev
Co-authored-by: Alvaro Bartolome <alvarobartt@gmail.com>
Co-authored-by: Daniel Vila Suero <daniel@argilla.io>
Co-authored-by: Tom Aarsen <37621491+tomaarsen@users.noreply.github.com>
Co-authored-by: Tom Aarsen <Cubiegamedev@gmail.com>
# Create elastic_vector_search.ElasticKnnSearch class
This extends `langchain/vectorstores/elastic_vector_search.py` by adding
a new class `ElasticKnnSearch`
Features:
- Allow creating an index with the `dense_vector` mapping compataible
with kNN search
- Store embeddings in index for use with kNN search (correct mapping
creates HNSW data structure)
- Perform approximate kNN search
- Perform hybrid BM25 (`query{}`) + kNN (`knn{}`) search
- perform knn search by either providing a `query_vector` or passing a
hosted `model_id` to use query_vector_builder to automatically generate
a query_vector at search time
Connection options
- Using `cloud_id` from Elastic Cloud
- Passing elasticsearch client object
search options
- query
- k
- query_vector
- model_id
- size
- source
- knn_boost (hybrid search)
- query_boost (hybrid search)
- fields
This also adds examples to
`docs/modules/indexes/vectorstores/examples/elasticsearch.ipynb`
Fixes # [5346](https://github.com/hwchase17/langchain/issues/5346)
cc: @dev2049
-->
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Lint sphinx documentation and fix broken links
This PR lints multiple warnings shown in generation of the project
documentation (using "make docs_linkcheck" and "make docs_build").
Additionally documentation internal links to (now?) non-existent files
are modified to point to existing documents as it seemed the new correct
target.
The documentation is not updated content wise.
There are no source code changes.
Fixes # (issue)
- broken documentation links to other files within the project
- sphinx formatting (linting)
## Before submitting
No source code changes, so no new tests added.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# docs: `ecosystem_integrations` update 3
Next cycle of updating the `ecosystem/integrations`
* Added an integration `template` file
* Added missed integration files
* Fixed several document_loaders/notebooks
## Who can review?
Is it possible to assign somebody to review PRs on docs? Thanks.
# Fix wrong class instantiation in docs MMR example
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
When looking at the Maximal Marginal Relevance ExampleSelector example
at
https://python.langchain.com/en/latest/modules/prompts/example_selectors/examples/mmr.html,
I noticed that there seems to be an error. Initially, the
`MaxMarginalRelevanceExampleSelector` class is used as an
`example_selector` argument to the `FewShotPromptTemplate` class. Then,
according to the text, a comparison is made to regular similarity
search. However, the `FewShotPromptTemplate` still uses the
`MaxMarginalRelevanceExampleSelector` class, so the output is the same.
To fix it, I added an instantiation of the
`SemanticSimilarityExampleSelector` class, because this seems to be what
is intended.
## Who can review?
@hwchase17
# Update Unstructured docs to remove the `detectron2` install
instructions
Removes `detectron2` installation instructions from the Unstructured
docs because installing `detectron2` is no longer required for
`unstructured>=0.7.0`. The `detectron2` model now runs using the ONNX
runtime.
## Who can review?
@hwchase17
@eyurtsev
# Add Managed Motorhead
This change enabled MotorheadMemory to utilize Metal's managed version
of Motorhead. We can easily enable this by passing in a `api_key` and
`client_id` in order to hit the managed url and access the memory api on
Metal.
Twitter: [@softboyjimbo](https://twitter.com/softboyjimbo)
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@dev2049 @hwchase17
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# added DeepLearing.AI course link
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
not @hwchase17 - hehe
# Bedrock LLM and Embeddings
This PR adds a new LLM and an Embeddings class for the
[Bedrock](https://aws.amazon.com/bedrock) service. The PR also includes
example notebooks for using the LLM class in a conversation chain and
embeddings usage in creating an embedding for a query and document.
**Note**: AWS is doing a private release of the Bedrock service on
05/31/2023; users need to request access and added to an allowlist in
order to start using the Bedrock models and embeddings. Please use the
[Bedrock Home Page](https://aws.amazon.com/bedrock) to request access
and to learn more about the models available in Bedrock.
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# Support Qdrant filters
Qdrant has an [extensive filtering
system](https://qdrant.tech/documentation/concepts/filtering/) with rich
type support. This PR makes it possible to use the filters in Langchain
by passing an additional param to both the
`similarity_search_with_score` and `similarity_search` methods.
## Who can review?
@dev2049 @hwchase17
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# SQLite-backed Entity Memory
Following the initiative of
https://github.com/hwchase17/langchain/pull/2397 I think it would be
helpful to be able to persist Entity Memory on disk by default
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This PR adds a new method `from_es_connection` to the
`ElasticsearchEmbeddings` class allowing users to use Elasticsearch
clusters outside of Elastic Cloud.
Users can create an Elasticsearch Client object and pass that to the new
function.
The returned object is identical to the one returned by calling
`from_credentials`
```
# Create Elasticsearch connection
es_connection = Elasticsearch(
hosts=['https://es_cluster_url:port'],
basic_auth=('user', 'password')
)
# Instantiate ElasticsearchEmbeddings using es_connection
embeddings = ElasticsearchEmbeddings.from_es_connection(
model_id,
es_connection,
)
```
I also added examples to the elasticsearch jupyter notebook
Fixes # https://github.com/hwchase17/langchain/issues/5239
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
As the title says, I added more code splitters.
The implementation is trivial, so i don't add separate tests for each
splitter.
Let me know if any concerns.
Fixes # (issue)
https://github.com/hwchase17/langchain/issues/5170
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev @hwchase17
---------
Signed-off-by: byhsu <byhsu@linkedin.com>
Co-authored-by: byhsu <byhsu@linkedin.com>
# Creates GitHubLoader (#5257)
GitHubLoader is a DocumentLoader that loads issues and PRs from GitHub.
Fixes#5257
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Added New Trello loader class and documentation
Simple Loader on top of py-trello wrapper.
With a board name you can pull cards and to do some field parameter
tweaks on load operation.
I included documentation and examples.
Included unit test cases using patch and a fixture for py-trello client
class.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Add ToolException that a tool can throw
This is an optional exception that tool throws when execution error
occurs.
When this exception is thrown, the agent will not stop working,but will
handle the exception according to the handle_tool_error variable of the
tool,and the processing result will be returned to the agent as
observation,and printed in pink on the console.It can be used like this:
```python
from langchain.schema import ToolException
from langchain import LLMMathChain, SerpAPIWrapper, OpenAI
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI
from langchain.tools import BaseTool, StructuredTool, Tool, tool
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0)
llm_math_chain = LLMMathChain(llm=llm, verbose=True)
class Error_tool:
def run(self, s: str):
raise ToolException('The current search tool is not available.')
def handle_tool_error(error) -> str:
return "The following errors occurred during tool execution:"+str(error)
search_tool1 = Error_tool()
search_tool2 = SerpAPIWrapper()
tools = [
Tool.from_function(
func=search_tool1.run,
name="Search_tool1",
description="useful for when you need to answer questions about current events.You should give priority to using it.",
handle_tool_error=handle_tool_error,
),
Tool.from_function(
func=search_tool2.run,
name="Search_tool2",
description="useful for when you need to answer questions about current events",
return_direct=True,
)
]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True,
handle_tool_errors=handle_tool_error)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
```

## Who can review?
- @vowelparrot
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# docs: ecosystem/integrations update
It is the first in a series of `ecosystem/integrations` updates.
The ecosystem/integrations list is missing many integrations.
I'm adding the missing integrations in a consistent format:
1. description of the integrated system
2. `Installation and Setup` section with 'pip install ...`, Key setup,
and other necessary settings
3. Sections like `LLM`, `Text Embedding Models`, `Chat Models`... with
links to correspondent examples and imports of the used classes.
This PR keeps new docs, that are presented in the
`docs/modules/models/text_embedding/examples` but missed in the
`ecosystem/integrations`. The next PRs will cover the next example
sections.
Also updated `integrations.rst`: added the `Dependencies` section with a
link to the packages used in LangChain.
## Who can review?
@hwchase17
@eyurtsev
@dev2049
# docs: ecosystem/integrations update 2
#5219 - part 1
The second part of this update (parts are independent of each other! no
overlap):
- added diffbot.md
- updated confluence.ipynb; added confluence.md
- updated college_confidential.md
- updated openai.md
- added blackboard.md
- added bilibili.md
- added azure_blob_storage.md
- added azlyrics.md
- added aws_s3.md
## Who can review?
@hwchase17@agola11
@agola11
@vowelparrot
@dev2049
# Update llamacpp demonstration notebook
Add instructions to install with BLAS backend, and update the example of
model usage.
Fixes#5071. However, it is more like a prevention of similar issues in
the future, not a fix, since there was no problem in the framework
functionality
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
- @hwchase17
- @agola11
# Fix for `update_document` Function in Chroma
## Summary
This pull request addresses an issue with the `update_document` function
in the Chroma class, as described in
[#5031](https://github.com/hwchase17/langchain/issues/5031#issuecomment-1562577947).
The issue was identified as an `AttributeError` raised when calling
`update_document` due to a missing corresponding method in the
`Collection` object. This fix refactors the `update_document` method in
`Chroma` to correctly interact with the `Collection` object.
## Changes
1. Fixed the `update_document` method in the `Chroma` class to correctly
call methods on the `Collection` object.
2. Added the corresponding test `test_chroma_update_document` in
`tests/integration_tests/vectorstores/test_chroma.py` to reflect the
updated method call.
3. Added an example and explanation of how to use the `update_document`
function in the Jupyter notebook tutorial for Chroma.
## Test Plan
All existing tests pass after this change. In addition, the
`test_chroma_update_document` test case now correctly checks the
functionality of `update_document`, ensuring that the function works as
expected and updates the content of documents correctly.
## Reviewers
@dev2049
This fix will ensure that users are able to use the `update_document`
function as expected, without encountering the previous
`AttributeError`. This will enhance the usability and reliability of the
Chroma class for all users.
Thank you for considering this pull request. I look forward to your
feedback and suggestions.
# Add SKLearnVectorStore
This PR adds SKLearnVectorStore, a simply vector store based on
NearestNeighbors implementations in the scikit-learn package. This
provides a simple drop-in vector store implementation with minimal
dependencies (scikit-learn is typically installed in a data scientist /
ml engineer environment). The vector store can be persisted and loaded
from json, bson and parquet format.
SKLearnVectorStore has soft (dynamic) dependency on the scikit-learn,
numpy and pandas packages. Persisting to bson requires the bson package,
persisting to parquet requires the pyarrow package.
## Before submitting
Integration tests are provided under
`tests/integration_tests/vectorstores/test_sklearn.py`
Sample usage notebook is provided under
`docs/modules/indexes/vectorstores/examples/sklear.ipynb`
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Sample Notebook for DynamoDB Chat Message History
@dev2049
Adding a sample notebook for the DynamoDB Chat Message History class.
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# Add Chainlit to deployment options
Add [Chainlit](https://github.com/Chainlit/chainlit) as deployment
options
Used links to Github examples and Chainlit doc on the LangChain
integration
Co-authored-by: Dan Constantini <danconstantini@Dan-Constantini-MacBook.local>
# docs: improve flow of llm caching notebook
The notebook `llm_caching` demos various caching providers. In the
previous version, there was setup common to all examples but under the
`In Memory Caching` heading.
If a user comes and only wants to try a particular example, they will
run the common setup, then the cells for the specific provider they are
interested in. Then they will get import and variable reference errors.
This commit moves the common setup to the top to avoid this.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@dev2049
# Better docs for weaviate hybrid search
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes: NA
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@dev2049
This PR adds LLM wrapper for Databricks. It supports two endpoint types:
* serving endpoint
* cluster driver proxy app
An integration notebook is included to show how it works.
Co-authored-by: Davis Chase <130488702+dev2049@users.noreply.github.com>
Co-authored-by: Gengliang Wang <gengliang@apache.org>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Fixed typo: 'ouput' to 'output' in all documentation
In this instance, the typo 'ouput' was amended to 'output' in all
occurrences within the documentation. There are no dependencies required
for this change.
# Add Momento as a standard cache and chat message history provider
This PR adds Momento as a standard caching provider. Implements the
interface, adds integration tests, and documentation. We also add
Momento as a chat history message provider along with integration tests,
and documentation.
[Momento](https://www.gomomento.com/) is a fully serverless cache.
Similar to S3 or DynamoDB, it requires zero configuration,
infrastructure management, and is instantly available. Users sign up for
free and get 50GB of data in/out for free every month.
## Before submitting
✅ We have added documentation, notebooks, and integration tests
demonstrating usage.
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Add Multi-CSV/DF support in CSV and DataFrame Toolkits
* CSV and DataFrame toolkits now accept list of CSVs/DFs
* Add default prompts for many dataframes in `pandas_dataframe` toolkit
Fixes#1958
Potentially fixes#4423
## Testing
* Add single and multi-dataframe integration tests for
`pandas_dataframe` toolkit with permutations of `include_df_in_prompt`
* Add single and multi-CSV integration tests for csv toolkit
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Add C Transformers for GGML Models
I created Python bindings for the GGML models:
https://github.com/marella/ctransformers
Currently it supports GPT-2, GPT-J, GPT-NeoX, LLaMA, MPT, etc. See
[Supported
Models](https://github.com/marella/ctransformers#supported-models).
It provides a unified interface for all models:
```python
from langchain.llms import CTransformers
llm = CTransformers(model='/path/to/ggml-gpt-2.bin', model_type='gpt2')
print(llm('AI is going to'))
```
It can be used with models hosted on the Hugging Face Hub:
```py
llm = CTransformers(model='marella/gpt-2-ggml')
```
It supports streaming:
```py
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = CTransformers(model='marella/gpt-2-ggml', callbacks=[StreamingStdOutCallbackHandler()])
```
Please see [README](https://github.com/marella/ctransformers#readme) for
more details.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
zep-python's sync methods no longer need an asyncio wrapper. This was
causing issues with FastAPI deployment.
Zep also now supports putting and getting of arbitrary message metadata.
Bump zep-python version to v0.30
Remove nest-asyncio from Zep example notebooks.
Modify tests to include metadata.
---------
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
Co-authored-by: Daniel Chalef <131175+danielchalef@users.noreply.github.com>
For most queries it's the `size` parameter that determines final number
of documents to return. Since our abstractions refer to this as `k`, set
this to be `k` everywhere instead of expecting a separate param. Would
be great to have someone more familiar with OpenSearch validate that
this is reasonable (e.g. that having `size` and what OpenSearch calls
`k` be the same won't lead to any strange behavior). cc @naveentatikonda
Closes#5212
# Resolve error in StructuredOutputParser docs
Documentation for `StructuredOutputParser` currently not reproducible,
that is, `output_parser.parse(output)` raises an error because the LLM
returns a response with an invalid format
```python
_input = prompt.format_prompt(question="what's the capital of france")
output = model(_input.to_string())
output
# ?
#
# ```json
# {
# "answer": "Paris",
# "source": "https://www.worldatlas.com/articles/what-is-the-capital-of-france.html"
# }
# ```
```
Was fixed by adding a question mark to the prompt
# Add QnA with sources example
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes: see
https://stackoverflow.com/questions/76207160/langchain-doesnt-work-with-weaviate-vector-database-getting-valueerror/76210017#76210017
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@dev2049
# Bibtex integration
Wrap bibtexparser to retrieve a list of docs from a bibtex file.
* Get the metadata from the bibtex entries
* `page_content` get from the local pdf referenced in the `file` field
of the bibtex entry using `pymupdf`
* If no valid pdf file, `page_content` set to the `abstract` field of
the bibtex entry
* Support Zotero flavour using regex to get the file path
* Added usage example in
`docs/modules/indexes/document_loaders/examples/bibtex.ipynb`
---------
Co-authored-by: Sébastien M. Popoff <sebastien.popoff@espci.fr>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
I found an API key for `serpapi_api_key` while reading the docs. It
seems to have been modified very recently. Removed it in this PR
@hwchase17 - project lead
# fix a mistake in concepts.md
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
# Add Joplin document loader
[Joplin](https://joplinapp.org/) is an open source note-taking app.
Joplin has a [REST API](https://joplinapp.org/api/references/rest_api/)
for accessing its local database. The proposed `JoplinLoader` uses the
API to retrieve all notes in the database and their metadata. Joplin
needs to be installed and running locally, and an access token is
required.
- The PR includes an integration test.
- The PR includes an example notebook.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Beam
Calls the Beam API wrapper to deploy and make subsequent calls to an
instance of the gpt2 LLM in a cloud deployment. Requires installation of
the Beam library and registration of Beam Client ID and Client Secret.
Additional calls can then be made through the instance of the large
language model in your code or by calling the Beam API.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Vectara Integration
This PR provides integration with Vectara. Implemented here are:
* langchain/vectorstore/vectara.py
* tests/integration_tests/vectorstores/test_vectara.py
* langchain/retrievers/vectara_retriever.py
And two IPYNB notebooks to do more testing:
* docs/modules/chains/index_examples/vectara_text_generation.ipynb
* docs/modules/indexes/vectorstores/examples/vectara.ipynb
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# DOCS added missed document_loader examples
Added missed examples: `JSON`, `Open Document Format (ODT)`,
`Wikipedia`, `tomarkdown`.
Updated them to a consistent format.
## Who can review?
@hwchase17
@dev2049
# Clarification of the reference to the "get_text_legth" function in
getting_started.md
Reference to the function "get_text_legth" in the documentation did not
make sense. Comment added for clarification.
@hwchase17
# Docs: updated getting_started.md
Just accommodating some unnecessary spaces in the example of "pass few
shot examples to a prompt template".
@vowelparrot
# Add MosaicML inference endpoints
This PR adds support in langchain for MosaicML inference endpoints. We
both serve a select few open source models, and allow customers to
deploy their own models using our inference service. Docs are here
(https://docs.mosaicml.com/en/latest/inference.html), and sign up form
is here (https://forms.mosaicml.com/demo?utm_source=langchain). I'm not
intimately familiar with the details of langchain, or the contribution
process, so please let me know if there is anything that needs fixing or
this is the wrong way to submit a new integration, thanks!
I'm also not sure what the procedure is for integration tests. I have
tested locally with my api key.
## Who can review?
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
This PR introduces a new module, `elasticsearch_embeddings.py`, which
provides a wrapper around Elasticsearch embedding models. The new
ElasticsearchEmbeddings class allows users to generate embeddings for
documents and query texts using a [model deployed in an Elasticsearch
cluster](https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding).
### Main features:
1. The ElasticsearchEmbeddings class initializes with an Elasticsearch
connection object and a model_id, providing an interface to interact
with the Elasticsearch ML client through
[infer_trained_model](https://elasticsearch-py.readthedocs.io/en/v8.7.0/api.html?highlight=trained%20model%20infer#elasticsearch.client.MlClient.infer_trained_model)
.
2. The `embed_documents()` method generates embeddings for a list of
documents, and the `embed_query()` method generates an embedding for a
single query text.
3. The class supports custom input text field names in case the deployed
model expects a different field name than the default `text_field`.
4. The implementation is compatible with any model deployed in
Elasticsearch that generates embeddings as output.
### Benefits:
1. Simplifies the process of generating embeddings using Elasticsearch
models.
2. Provides a clean and intuitive interface to interact with the
Elasticsearch ML client.
3. Allows users to easily integrate Elasticsearch-generated embeddings.
Related issue https://github.com/hwchase17/langchain/issues/3400
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Fix typo + add wikipedia package installation part in
human_input_llm.ipynb
This PR
1. Fixes typo ("the the human input LLM"),
2. Addes wikipedia package installation part (in accordance with
`WikipediaQueryRun`
[documentation](https://python.langchain.com/en/latest/modules/agents/tools/examples/wikipedia.html))
in `human_input_llm.ipynb`
(`docs/modules/models/llms/examples/human_input_llm.ipynb`)
# Add link to Psychic from document loaders documentation page
In my previous PR I forgot to update `document_loaders.rst` to link to
`psychic.ipynb` to make it discoverable from the main documentation.
# Add AzureCognitiveServicesToolkit to call Azure Cognitive Services
API: achieve some multimodal capabilities
This PR adds a toolkit named AzureCognitiveServicesToolkit which bundles
the following tools:
- AzureCogsImageAnalysisTool: calls Azure Cognitive Services image
analysis API to extract caption, objects, tags, and text from images.
- AzureCogsFormRecognizerTool: calls Azure Cognitive Services form
recognizer API to extract text, tables, and key-value pairs from
documents.
- AzureCogsSpeech2TextTool: calls Azure Cognitive Services speech to
text API to transcribe speech to text.
- AzureCogsText2SpeechTool: calls Azure Cognitive Services text to
speech API to synthesize text to speech.
This toolkit can be used to process image, document, and audio inputs.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Add a WhyLabs callback handler
* Adds a simple WhyLabsCallbackHandler
* Add required dependencies as optional
* protect against missing modules with imports
* Add docs/ecosystem basic example
based on initial prototype from @andrewelizondo
> this integration gathers privacy preserving telemetry on text with
whylogs and sends stastical profiles to WhyLabs platform to monitoring
these metrics over time. For more information on what WhyLabs is see:
https://whylabs.ai
After you run the notebook (if you have env variables set for the API
Keys, org_id and dataset_id) you get something like this in WhyLabs:

Co-authored-by: Andre Elizondo <andre@whylabs.ai>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
OpenLM is a zero-dependency OpenAI-compatible LLM provider that can call
different inference endpoints directly via HTTP. It implements the
OpenAI Completion class so that it can be used as a drop-in replacement
for the OpenAI API. This changeset utilizes BaseOpenAI for minimal added
code.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Add Mastodon toots loader.
Loader works either with public toots, or Mastodon app credentials. Toot
text and user info is loaded.
I've also added integration test for this new loader as it works with
public data, and a notebook with example output run now.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Improve pinecone hybrid search retriever adding metadata support
I simply remove the hardwiring of metadata to the existing
implementation allowing one to pass `metadatas` attribute to the
constructors and in `get_relevant_documents`. I also add one missing pip
install to the accompanying notebook (I am not adding dependencies, they
were pre-existing).
First contribution, just hoping to help, feel free to critique :)
my twitter username is `@andreliebschner`
While looking at hybrid search I noticed #3043 and #1743. I think the
former can be closed as following the example right now (even prior to
my improvements) works just fine, the latter I think can be also closed
safely, maybe pointing out the relevant classes and example. Should I
reply those issues mentioning someone?
@dev2049, @hwchase17
---------
Co-authored-by: Andreas Liebschner <a.liebschner@shopfully.com>
# docs: `deployments` page moved into `ecosystem/`
The `Deployments` page moved into the `Ecosystem/` group
Small fixes:
- `index` page: fixed order of items in the `Modules` list, in the `Use
Cases` list
- item `References/Installation` was lost in the `index` page (not on
the Navbar!). Restored it.
- added `|` marker in several places.
NOTE: I also thought about moving the `Additional Resources/Gallery`
page into the `Ecosystem` group but decided to leave it unchanged.
Please, advise on this.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@dev2049
### Submit Multiple Files to the Unstructured API
Enables batching multiple files into a single Unstructured API requests.
Support for requests with multiple files was added to both
`UnstructuredAPIFileLoader` and `UnstructuredAPIFileIOLoader`. Note that
if you submit multiple files in "single" mode, the result will be
concatenated into a single document. We recommend using this feature in
"elements" mode.
### Testing
The following should load both documents, using two of the example docs
from the integration tests folder.
```python
from langchain.document_loaders import UnstructuredAPIFileLoader
file_paths = ["examples/layout-parser-paper.pdf", "examples/whatsapp_chat.txt"]
loader = UnstructuredAPIFileLoader(
file_paths=file_paths,
api_key="FAKE_API_KEY",
strategy="fast",
mode="elements",
)
docs = loader.load()
```
# Corrected Misspelling in agents.rst Documentation
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get
-->
In the
[documentation](https://python.langchain.com/en/latest/modules/agents.html)
it says "in fact, it is often best to have an Action Agent be in
**change** of the execution for the Plan and Execute agent."
**Suggested Change:** I propose correcting change to charge.
Fix for issue: #5039
# Add documentation for Databricks integration
This is a follow-up of https://github.com/hwchase17/langchain/pull/4702
It documents the details of how to integrate Databricks using langchain.
It also provides examples in a notebook.
## Who can review?
@dev2049 @hwchase17 since you are aware of the context. We will promote
the integration after this doc is ready. Thanks in advance!
# Fixes an annoying typo in docs
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes Annoying typo in docs - "Therefor" -> "Therefore". It's so
annoying to read that I just had to make this PR.
# Streaming only final output of agent (#2483)
As requested in issue #2483, this Callback allows to stream only the
final output of an agent (ie not the intermediate steps).
Fixes#2483
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Add self query translator for weaviate vectorstore
Adds support for the EQ comparator and the AND/OR operators.
Co-authored-by: Dominic Chan <dchan@cppib.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
- Higher accuracy on the responses
- New redesigned UI
- Pretty Sources: display the sources by title / sub-section instead of
long URL.
- Fixed Reset Button bugs and some other UI issues
- Other tweaks
# Improve Evernote Document Loader
When exporting from Evernote you may export more than one note.
Currently the Evernote loader concatenates the content of all notes in
the export into a single document and only attaches the name of the
export file as metadata on the document.
This change ensures that each note is loaded as an independent document
and all available metadata on the note e.g. author, title, created,
updated are added as metadata on each document.
It also uses an existing optional dependency of `html2text` instead of
`pypandoc` to remove the need to download the pandoc application via
`download_pandoc()` to be able to use the `pypandoc` python bindings.
Fixes#4493
Co-authored-by: Mike McGarry <mike.mcgarry@finbourne.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Remove autoreload in examples
Remove the `autoreload` in examples since it is not necessary for most
users:
```
%load_ext autoreload,
%autoreload 2
```
# Powerbi API wrapper bug fix + integration tests
- Bug fix by removing `TYPE_CHECKING` in in utilities/powerbi.py
- Added integration test for power bi api in
utilities/test_powerbi_api.py
- Added integration test for power bi agent in
agent/test_powerbi_agent.py
- Edited .env.examples to help set up power bi related environment
variables
- Updated demo notebook with working code in
docs../examples/powerbi.ipynb - AzureOpenAI -> ChatOpenAI
Notes:
Chat models (gpt3.5, gpt4) are much more capable than davinci at writing
DAX queries, so that is important to getting the agent to work properly.
Interestingly, gpt3.5-turbo needed the examples=DEFAULT_FEWSHOT_EXAMPLES
to write consistent DAX queries, so gpt4 seems necessary as the smart
llm.
Fixes#4325
## Before submitting
Azure-core and Azure-identity are necessary dependencies
check integration tests with the following:
`pytest tests/integration_tests/utilities/test_powerbi_api.py`
`pytest tests/integration_tests/agent/test_powerbi_agent.py`
You will need a power bi account with a dataset id + table name in order
to test. See .env.examples for details.
## Who can review?
@hwchase17
@vowelparrot
---------
Co-authored-by: aditya-pethe <adityapethe1@gmail.com>
# Added a YouTube Tutorial
Added a LangChain tutorial playlist aimed at onboarding newcomers to
LangChain and its use cases.
I've shared the video in the #tutorials channel and it seemed to be well
received. I think this could be useful to the greater community.
## Who can review?
@dev2049
This PR adds support for Databricks runtime and Databricks SQL by using
[Databricks SQL Connector for
Python](https://docs.databricks.com/dev-tools/python-sql-connector.html).
As a cloud data platform, accessing Databricks requires a URL as follows
`databricks://token:{api_token}@{hostname}?http_path={http_path}&catalog={catalog}&schema={schema}`.
**The URL is **complicated** and it may take users a while to figure it
out**. Since the fields `api_token`/`hostname`/`http_path` fields are
known in the Databricks notebook, I am proposing a new method
`from_databricks` to simplify the connection to Databricks.
## In Databricks Notebook
After changes, Databricks users only need to specify the `catalog` and
`schema` field when using langchain.
<img width="881" alt="image"
src="https://github.com/hwchase17/langchain/assets/1097932/984b4c57-4c2d-489d-b060-5f4918ef2f37">
## In Jupyter Notebook
The method can be used on the local setup as well:
<img width="678" alt="image"
src="https://github.com/hwchase17/langchain/assets/1097932/142e8805-a6ef-4919-b28e-9796ca31ef19">
# Add Spark SQL support
* Add Spark SQL support. It can connect to Spark via building a
local/remote SparkSession.
* Include a notebook example
I tried some complicated queries (window function, table joins), and the
tool works well.
Compared to the [Spark Dataframe
agent](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/spark.html),
this tool is able to generate queries across multiple tables.
---------
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Gengliang Wang <gengliang@apache.org>
Co-authored-by: Mike W <62768671+skcoirz@users.noreply.github.com>
Co-authored-by: Eugene Yurtsev <eyurtsev@gmail.com>
Co-authored-by: UmerHA <40663591+UmerHA@users.noreply.github.com>
Co-authored-by: 张城铭 <z@hyperf.io>
Co-authored-by: assert <zhangchengming@kkguan.com>
Co-authored-by: blob42 <spike@w530>
Co-authored-by: Yuekai Zhang <zhangyuekai@foxmail.com>
Co-authored-by: Richard He <he.yucheng@outlook.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Co-authored-by: Leonid Ganeline <leo.gan.57@gmail.com>
Co-authored-by: Alexey Nominas <60900649+Chae4ek@users.noreply.github.com>
Co-authored-by: elBarkey <elbarkey@gmail.com>
Co-authored-by: Davis Chase <130488702+dev2049@users.noreply.github.com>
Co-authored-by: Jeffrey D <1289344+verygoodsoftwarenotvirus@users.noreply.github.com>
Co-authored-by: so2liu <yangliu35@outlook.com>
Co-authored-by: Viswanadh Rayavarapu <44315599+vishwa-rn@users.noreply.github.com>
Co-authored-by: Chakib Ben Ziane <contact@blob42.xyz>
Co-authored-by: Daniel Chalef <131175+danielchalef@users.noreply.github.com>
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
Co-authored-by: Jari Bakken <jari.bakken@gmail.com>
Co-authored-by: escafati <scafatieugenio@gmail.com>
# Zep Retriever - Vector Search Over Chat History with the Zep Long-term
Memory Service
More on Zep: https://github.com/getzep/zep
Note: This PR is related to and relies on
https://github.com/hwchase17/langchain/pull/4834. I did not want to
modify the `pyproject.toml` file to add the `zep-python` dependency a
second time.
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
# docs: updated `Supabase` notebook
- the title of the notebook was inconsistent (included redundant
"Vectorstore"). Removed this "Vectorstore"
- added `Postgress` to the title. It is important. The `Postgres` name
is much more popular than `Supabase`.
- added description for the `Postrgress`
- added more info to the `Supabase` description
# Update GPT4ALL integration
GPT4ALL have completely changed their bindings. They use a bit odd
implementation that doesn't fit well into base.py and it will probably
be changed again, so it's a temporary solution.
Fixes#3839, #4628
# Docs: compound ecosystem and integrations
**Problem statement:** We have a big overlap between the
References/Integrations and Ecosystem/LongChain Ecosystem pages. It
confuses users. It creates a situation when new integration is added
only on one of these pages, which creates even more confusion.
- removed References/Integrations page (but move all its information
into the individual integration pages - in the next PR).
- renamed Ecosystem/LongChain Ecosystem into Integrations/Integrations.
I like the Ecosystem term. It is more generic and semantically richer
than the Integration term. But it mentally overloads users. The
`integration` term is more concrete.
UPDATE: after discussion, the Ecosystem is the term.
Ecosystem/Integrations is the page (in place of Ecosystem/LongChain
Ecosystem).
As a result, a user gets a single place to start with the individual
integration.
# Fix bilibili api import error
bilibili-api package is depracated and there is no sync module.
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes#2673#2724
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@vowelparrot @liaokongVFX
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# TextLoader auto detect encoding and enhanced exception handling
- Add an option to enable encoding detection on `TextLoader`.
- The detection is done using `chardet`
- The loading is done by trying all detected encodings by order of
confidence or raise an exception otherwise.
### New Dependencies:
- `chardet`
Fixes#4479
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
- @eyurtsev
---------
Co-authored-by: blob42 <spike@w530>
# Load specific file types from Google Drive (issue #4878)
Add the possibility to define what file types you want to load from
Google Drive.
```
loader = GoogleDriveLoader(
folder_id="1yucgL9WGgWZdM1TOuKkeghlPizuzMYb5",
file_types=["document", "pdf"]
recursive=False
)
```
Fixes ##4878
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
DataLoaders
- @eyurtsev
Twitter: [@UmerHAdil](https://twitter.com/@UmerHAdil) | Discord:
RicChilligerDude#7589
---------
Co-authored-by: UmerHA <40663591+UmerHA@users.noreply.github.com>
#docs: text splitters improvements
Changes are only in the Jupyter notebooks.
- added links to the source packages and a short description of these
packages
- removed " Text Splitters" suffixes from the TOC elements (they made
the list of the text splitters messy)
- moved text splitters, based on the length function into a separate
list. They can be mixed with any classes from the "Text Splitters", so
it is a different classification.
## Who can review?
@hwchase17 - project lead
@eyurtsev
@vowelparrot
NOTE: please, check out the results of the `Python code` text splitter
example (text_splitters/examples/python.ipynb). It looks suboptimal.
# Added another helpful way for developers who want to set OpenAI API
Key dynamically
Previous methods like exporting environment variables are good for
project-wide settings.
But many use cases need to assign API keys dynamically, recently.
```python
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="OPENAI_API_KEY")
```
## Before submitting
```bash
export OPENAI_API_KEY="..."
```
Or,
```python
import os
os.environ["OPENAI_API_KEY"] = "..."
```
<hr>
Thank you.
Cheers,
Bongsang
# Documentation for Azure OpenAI embeddings model
- OPENAI_API_VERSION environment variable is needed for the endpoint
- The constructor does not work with model, it works with deployment.
I fixed it in the notebook.
(This is my first contribution)
## Who can review?
@hwchase17
@agola
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Update deployments doc with langcorn API server
API server example
```python
from fastapi import FastAPI
from langcorn import create_service
app: FastAPI = create_service(
"examples.ex1:chain",
"examples.ex2:chain",
"examples.ex3:chain",
"examples.ex4:sequential_chain",
"examples.ex5:conversation",
"examples.ex6:conversation_with_summary",
)
```
More examples: https://github.com/msoedov/langcorn/tree/main/examples
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Docs and code review fixes for Docugami DataLoader
1. I noticed a couple of hyperlinks that are not loading in the
langchain docs (I guess need explicit anchor tags). Added those.
2. In code review @eyurtsev had a
[suggestion](https://github.com/hwchase17/langchain/pull/4727#discussion_r1194069347)
to allow string paths. Turns out just updating the type works (I tested
locally with string paths).
# Pre-submission checks
I ran `make lint` and `make tests` successfully.
---------
Co-authored-by: Taqi Jaffri <tjaffri@docugami.com>
# Fix Homepage Typo
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested... not sure
# Docs: improvements in the `retrievers/examples/` notebooks
Its primary purpose is to make the Jupyter notebook examples
**consistent** and more suitable for first-time viewers.
- add links to the integration source (if applicable) with a short
description of this source;
- removed `_retriever` suffix from the file names (where it existed) for
consistency;
- removed ` retriever` from the notebook title (where it existed) for
consistency;
- added code to install necessary Python package(s);
- added code to set up the necessary API Key.
- very small fixes in notebooks from other folders (for consistency):
- docs/modules/indexes/vectorstores/examples/elasticsearch.ipynb
- docs/modules/indexes/vectorstores/examples/pinecone.ipynb
- docs/modules/models/llms/integrations/cohere.ipynb
- fixed misspelling in langchain/retrievers/time_weighted_retriever.py
comment (sorry, about this change in a .py file )
## Who can review
@dev2049
# Fixed typos (issues #4818 & #4668 & more typos)
- At some places, it said `model = ChatOpenAI(model='gpt-3.5-turbo')`
but should be `model = ChatOpenAI(model_name='gpt-3.5-turbo')`
- Fixes some other typos
Fixes#4818, #4668
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
# Removed usage of deprecated methods
Replaced `SQLDatabaseChain` deprecated direct initialisation with
`from_llm` method
## Who can review?
@hwchase17
@agola11
---------
Co-authored-by: imeckr <chandanroutray2012@gmail.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
- Installation of non-colab packages
- Get API keys
# Added dependencies to make notebook executable on hosted notebooks
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@hwchase17
@vowelparrot
- Installation of non-colab packages
- Get API keys
- Get rid of warnings
# Cleanup and added dependencies to make notebook executable on hosted
notebooks
@hwchase17
@vowelparrot
The current example in
https://python.langchain.com/en/latest/modules/agents/plan_and_execute.html
has inconsistent reasoning step (observing 28 years and thinking it's 26
years):
```
Observation: 28 years
Thought:Based on my search, Gigi Hadid's current age is 26 years old.
Action:
{
"action": "Final Answer",
"action_input": "Gigi Hadid's current age is 26 years old."
}
```
Guessing this is model noise. Rerunning seems to give correct answer of
28 years.
# Fix Telegram API loader + add tests.
I was testing this integration and it was broken with next error:
```python
message_threads = loader._get_message_threads(df)
KeyError: False
```
Also, this particular loader didn't have any tests / related group in
poetry, so I added those as well.
@hwchase17 / @eyurtsev please take a look on this fix PR.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Cassandra support for chat history
### Description
- Store chat messages in cassandra
### Dependency
- cassandra-driver - Python Module
## Before submitting
- Added Integration Test
## Who can review?
@hwchase17
@agola11
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, include an integration test and
an example notebook showing its use! -->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Co-authored-by: Jinto Jose <129657162+jj701@users.noreply.github.com>
# docs: added `additional_resources` folder
The additional resource files were inside the doc top-level folder,
which polluted the top-level folder.
- added the `additional_resources` folder and moved correspondent files
to this folder;
- fixed a broken link to the "Model comparison" page (model_laboratory
notebook)
- fixed a broken link to one of the YouTube videos (sorry, it is not
directly related to this PR)
## Who can review?
@dev2049
This reverts commit 5111bec540.
This PR introduced a bug in the async API (the `url` param isn't bound);
it also didn't update the synchronous API correctly, which makes it
error-prone (the behavior of the async and sync endpoints would be
different)
- added an official LangChain YouTube channel :)
- added new tutorials and videos (only videos with enough subscriber or
view numbers)
- added a "New video" icon
## Who can review?
@dev2049
# Add GraphQL Query Support
This PR introduces a GraphQL API Wrapper tool that allows LLM agents to
query GraphQL databases. The tool utilizes the httpx and gql Python
packages to interact with GraphQL APIs and provides a simple interface
for running queries with LLM agents.
@vowelparrot
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# glossary.md renamed as concepts.md and moved under the Getting Started
small PR.
`Concepts` looks right to the point. It is moved under Getting Started
(typical place). Previously it was lost in the Additional Resources
section.
## Who can review?
@hwchase17
### Adds a document loader for Docugami
Specifically:
1. Adds a data loader that talks to the [Docugami](http://docugami.com)
API to download processed documents as semantic XML
2. Parses the semantic XML into chunks, with additional metadata
capturing chunk semantics
3. Adds a detailed notebook showing how you can use additional metadata
returned by Docugami for techniques like the [self-querying
retriever](https://python.langchain.com/en/latest/modules/indexes/retrievers/examples/self_query_retriever.html)
4. Adds an integration test, and related documentation
Here is an example of a result that is not possible without the
capabilities added by Docugami (from the notebook):
<img width="1585" alt="image"
src="https://github.com/hwchase17/langchain/assets/749277/bb6c1ce3-13dc-4349-a53b-de16681fdd5b">
---------
Co-authored-by: Taqi Jaffri <tjaffri@docugami.com>
Co-authored-by: Taqi Jaffri <tjaffri@gmail.com>
# Added Tutorials section on the top-level of documentation
**Problem Statement**: the Tutorials section in the documentation is
top-priority. Not every project has resources to make tutorials. We have
such a privilege. Community experts created several tutorials on
YouTube.
But the tutorial links are now hidden on the YouTube page and not easily
discovered by first-time visitors.
**PR**: I've created the `Tutorials` page (from the `Additional
Resources/YouTube` page) and moved it to the top level of documentation
in the `Getting Started` section.
## Who can review?
@dev2049
NOTE:
PR checks are randomly failing
3aefaafcdb258819eadf514d81b5b3
[OpenWeatherMapAPIWrapper](f70e18a5b3/docs/modules/agents/tools/examples/openweathermap.ipynb)
works wonderfully, but the _tool_ itself can't be used in master branch.
- added OpenWeatherMap **tool** to the public api, to be loadable with
`load_tools` by using "openweathermap-api" tool name (that name is used
in the existing
[docs](aff33d52c5/docs/modules/agents/tools/getting_started.md),
at the bottom of the page)
- updated OpenWeatherMap tool's **description** to make the input format
match what the API expects (e.g. `London,GB` instead of `'London,GB'`)
- added [ecosystem documentation page for
OpenWeatherMap](f9c41594fe/docs/ecosystem/openweathermap.md)
- added tool usage example to [OpenWeatherMap's
notebook](f9c41594fe/docs/modules/agents/tools/examples/openweathermap.ipynb)
Let me know if there's something I missed or something needs to be
updated! Or feel free to make edits yourself if that makes it easier for
you 🙂