Implementation of similarity_search_with_relevance_scores for quadrant
vector store.
As implemented the method is also compatible with other capacities such
as filtering.
Integration tests updated.
#### Who can review?
Tag maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
This PR adds documentation for Shale Protocol's integration with
LangChain.
[Shale Protocol](https://shaleprotocol.com) provides forever-free
production-ready inference APIs to the open-source community. We have
global data centers and plan to support all major open LLMs (estimated
~1,000 by 2025).
The team consists of software and ML engineers, AI researchers,
designers, and operators across North America and Asia. Combined
together, the team has 50+ years experience in machine learning, cloud
infrastructure, software engineering and product development. Team
members have worked at places like Google and Microsoft.
#### Who can review?
Tag maintainers/contributors who might be interested:
- @hwchase17
- @agola11
---------
Co-authored-by: Karen Sheng <46656667+karensheng@users.noreply.github.com>
## Changes
- Added the `stop` param to the `_VertexAICommon` class so it can be set
at llm initialization
## Example Usage
```python
VertexAI(
# ...
temperature=0.15,
max_output_tokens=128,
top_p=1,
top_k=40,
stop=["\n```"],
)
```
## Possible Reviewers
- @hwchase17
- @agola11
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
Add some logging into the powerbi tool so that you can see the queries
being sent to PBI and attempts to correct them.
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested: @vowelparrot
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
### Summary
Adds an `UnstructuredCSVLoader` for loading CSVs. One advantage of using
`UnstructuredCSVLoader` relative to the standard `CSVLoader` is that if
you use `UnstructuredCSVLoader` in `"elements"` mode, an HTML
representation of the table will be available in the metadata.
#### Who can review?
@hwchase17
@eyurtsev
Hi! I just added an example of how to use a custom scraping function
with the sitemap loader. I recently used this feature and had to dig in
the source code to find it. I thought it might be useful to other devs
to have an example in the Jupyter Notebook directly.
I only added the example to the documentation page.
@eyurtsev I was not able to run the lint. Please let me know if I have
to do anything else.
I know this is a very small contribution, but I hope it will be
valuable. My Twitter handle is @web3Dav3.
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17 - project lead
- @agola11
---------
Co-authored-by: Yessen Kanapin <yessen@deepinfra.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
LatexTextSplitter needs to use "\n\\\chapter" when separators are
escaped, such as "\n\\\chapter", otherwise it will report an error:
(re.error: bad escape \c at position 1 (line 2, column 1))
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
re.error: bad escape \c at position 1 (line 2, column 1)
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
@hwchase17 @dev2049
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Co-authored-by: Pang <ugfly@qq.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes#5822
I upgrade my langchain lib by execute `pip install -U langchain`, and
the verion is 0.0.192。But i found that openai.api_base not working. I
use azure openai service as openai backend, the openai.api_base is very
import for me. I hava compared tag/0.0.192 and tag/0.0.191, and figure
out that:

openai params is moved inside `_invocation_params` function,and used in
some openai invoke:

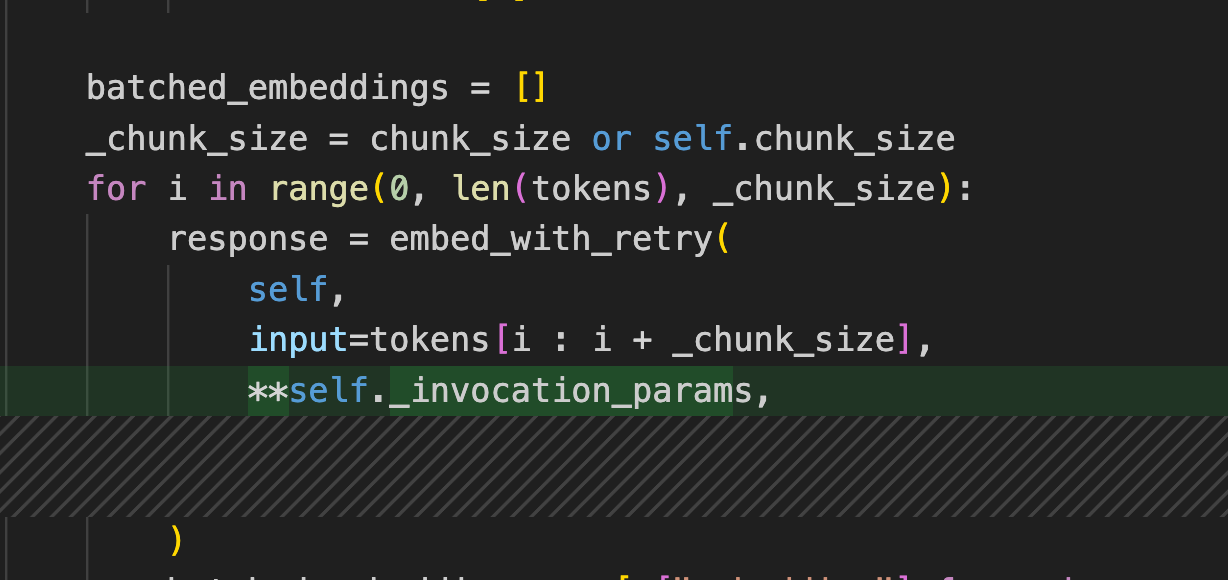
but still some case not covered like:
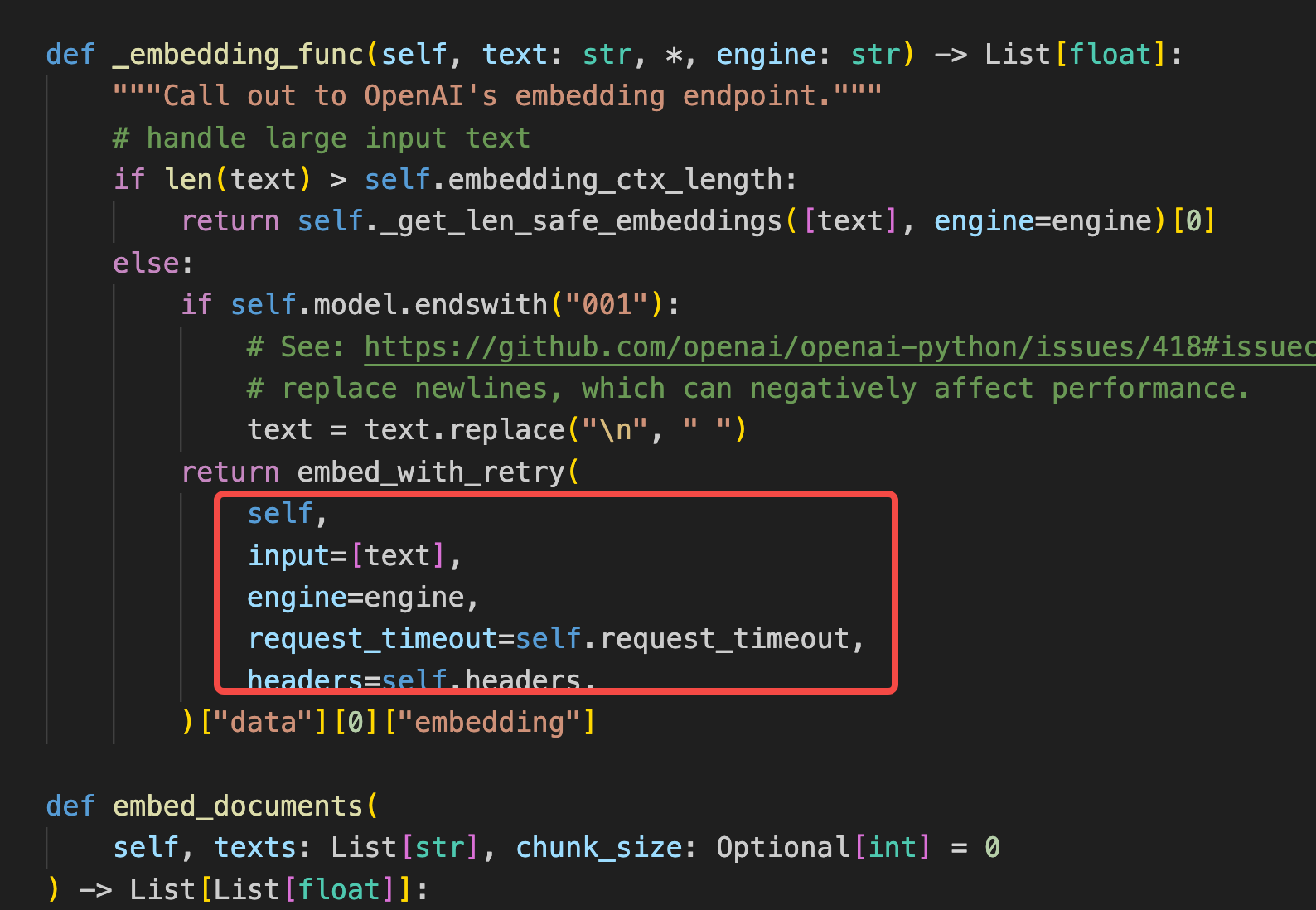
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
just change "to" to "too" so it matches the above prompt
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Fixes # 5807
Realigned tests with implementation.
Also reinforced folder unicity for the test_faiss_local_save_load test
using date-time suffix
#### Before submitting
- Integration test updated
- formatting and linting ok (locally)
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17 - project lead
VectorStores / Retrievers / Memory
-@dev2049
I added support for specifing different types with ResponseSchema
objects:
## before
`
extracted_info = ResponseSchema(name="extracted_info", description="List
of extracted information")
`
generate the following doc: ```json\n{\n\t\"extracted_info\": string //
List of extracted information}```
This brings GPT to create a JSON with only one string in the specified
field even if you requested a List in the description.
## now
`extracted_info = ResponseSchema(name="extracted_info",
type="List[string]", description="List of extracted information")
`
generate the following doc: ```json\n{\n\t\"extracted_info\":
List[string] // List of extracted information}```
This way the model responds better to the prompt generating an array of
strings.
Tag maintainers/contributors who might be interested:
Agents / Tools / Toolkits
@vowelparrot
Don't know who can be interested, I suppose this is a tool, so I tagged
you vowelparrot,
anyway, it's a minor change, and shouldn't impact any other part of the
framework.
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Some links were broken from the previous merge. This PR fixes them.
Tested locally.
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Signed-off-by: Kourosh Hakhamaneshi <kourosh@anyscale.com>
This introduces the `YoutubeAudioLoader`, which will load blobs from a
YouTube url and write them. Blobs are then parsed by
`OpenAIWhisperParser()`, as show in this
[PR](https://github.com/hwchase17/langchain/pull/5580), but we extend
the parser to split audio such that each chuck meets the 25MB OpenAI
size limit. As shown in the notebook, this enables a very simple UX:
```
# Transcribe the video to text
loader = GenericLoader(YoutubeAudioLoader([url],save_dir),OpenAIWhisperParser())
docs = loader.load()
```
Tested on full set of Karpathy lecture videos:
```
# Karpathy lecture videos
urls = ["https://youtu.be/VMj-3S1tku0"
"https://youtu.be/PaCmpygFfXo",
"https://youtu.be/TCH_1BHY58I",
"https://youtu.be/P6sfmUTpUmc",
"https://youtu.be/q8SA3rM6ckI",
"https://youtu.be/t3YJ5hKiMQ0",
"https://youtu.be/kCc8FmEb1nY"]
# Directory to save audio files
save_dir = "~/Downloads/YouTube"
# Transcribe the videos to text
loader = GenericLoader(YoutubeAudioLoader(urls,save_dir),OpenAIWhisperParser())
docs = loader.load()
```
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
In the [Databricks
integration](https://python.langchain.com/en/latest/integrations/databricks.html)
and [Databricks
LLM](https://python.langchain.com/en/latest/modules/models/llms/integrations/databricks.html),
we suggestted users to set the ENV variable `DATABRICKS_API_TOKEN`.
However, this is inconsistent with the other Databricks library. To make
it consistent, this PR changes the variable from `DATABRICKS_API_TOKEN`
to `DATABRICKS_TOKEN`
After changes, there is no more `DATABRICKS_API_TOKEN` in the doc
```
$ git grep DATABRICKS_API_TOKEN|wc -l
0
$ git grep DATABRICKS_TOKEN|wc -l
8
```
cc @hwchase17 @dev2049 @mengxr since you have reviewed the previous PRs.
# What does this PR do?
Change the HTML tags so that a tag with attributes can be found.
## Before submitting
- [x] Tests added
- [x] CI/CD validated
### Who can review?
Anyone in the community is free to review the PR once the tests have
passed. Feel free to tag
members/contributors who may be interested in your PR.
- Remove the client implementation (this breaks backwards compatibility
for existing testers. I could keep the stub in that file if we want, but
not many people are using it yet
- Add SDK as dependency
- Update the 'run_on_dataset' method to be a function that optionally
accepts a client as an argument
- Remove the langchain plus server implementation (you get it for free
with the SDK now)
We could make the SDK optional for now, but the plan is to use w/in the
tracer so it would likely become a hard dependency at some point.
# Scores in Vectorestores' Docs Are Explained
Following vectorestores can return scores with similar documents by
using `similarity_search_with_score`:
- chroma
- docarray_hnsw
- docarray_in_memory
- faiss
- myscale
- qdrant
- supabase
- vectara
- weaviate
However, in documents, these scores were either not explained at all or
explained in a way that could lead to misunderstandings (e.g., FAISS).
For instance in FAISS document: if we consider the score returned by the
function as a similarity score, we understand that a document returning
a higher score is more similar to the source document. However, since
the scores returned by the function are distance scores, we should
understand that smaller scores correspond to more similar documents.
For the libraries other than Vectara, I wrote the scores they use by
investigating from the source libraries. Since I couldn't be certain
about the score metric used by Vectara, I didn't make any changes in its
documentation. The links mentioned in Vectara's documentation became
broken due to updates, so I replaced them with working ones.
VectorStores / Retrievers / Memory
- @dev2049
my twitter: [berkedilekoglu](https://twitter.com/berkedilekoglu)
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# Added an overview of LangChain modules
Aimed at introducing newcomers to LangChain's main modules :)
Twitter handle is @edrick_dch
## Who can review?
@eyurtsev
Fixes#5614
#### Issue
The `***` combination produces an exception when used as a seperator in
`re.split`. Instead `\*\*\*` should be used for regex exprations.
#### Who can review?
@eyurtsev
Fixes#5699
#### Who can review?
Tag maintainers/contributors who might be interested:
@woodworker @LeSphax @johannhartmann
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
…719)
A minor update to retry Cohore API call in case of errors using tenacity
as it is done for OpenAI LLMs.
#### Who can review?
@hwchase17, @agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Sagar Sapkota <22609549+sagar-spkt@users.noreply.github.com>
Aviary is an open source toolkit for evaluating and deploying open
source LLMs. You can find out more about it on
[http://github.com/ray-project/aviary). You can try it out at
[http://aviary.anyscale.com](aviary.anyscale.com).
This code adds support for Aviary in LangChain. To minimize
dependencies, it connects directly to the HTTP endpoint.
The current implementation is not accelerated and uses the default
implementation of `predict` and `generate`.
It includes a test and a simple example.
@hwchase17 and @agola11 could you have a look at this?
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
Adding a class attribute "return_generated_question" to class
"BaseConversationalRetrievalChain". If set to `True`, the chain's output
has a key "generated_question" with the question generated by the
sub-chain `question_generator` as the value. This way the generated
question can be logged.
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@dev2049 @vowelparrot
# OpenAIWhisperParser
This PR creates a new parser, `OpenAIWhisperParser`, that uses the
[OpenAI Whisper
model](https://platform.openai.com/docs/guides/speech-to-text/quickstart)
to perform transcription of audio files to text (`Documents`). Please
see the notebook for usage.
Fixed python deprecation warning:
DeprecationWarning: invalid escape sequence '`'
backticks (`) do not have special meaning in python strings and should
not be escaped.
-- @spazm on twitter
### Who can review:
@nfcampos ported this change from javascript, @hwchase17 wrote the
original STRUCTURED_FORMAT_INSTRUCTIONS,