Zep now supports persisting custom metadata with messages and hybrid
search across both message embeddings and structured metadata. This PR
implements custom metadata and enhancements to the
`ZepChatMessageHistory` and `ZepRetriever` classes to implement this
support.
Tag maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
---------
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
# Check if generated Cypher code is wrapped in backticks
Some LLMs like the VertexAI like to explain how they generated the
Cypher statement and wrap the actual code in three backticks:
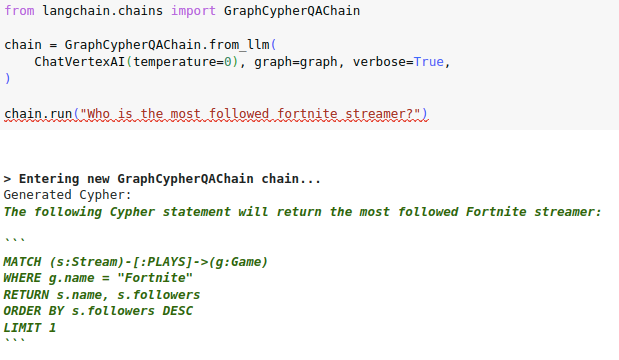
I have observed a similar pattern with OpenAI chat models in a
conversational settings, where multiple user and assistant message are
provided to the LLM to generate Cypher statements, where then the LLM
wants to maybe apologize for previous steps or explain its thoughts.
Interestingly, both OpenAI and VertexAI wrap the code in three backticks
if they are doing any explaining or apologizing. Checking if the
generated cypher is wrapped in backticks seems like a low-hanging fruit
to expand the cypher search to other LLMs and conversational settings.
# Adding support to save multiple memories at a time. Cuts save time by
more then half
<!--
Thank you for contributing to LangChain! Your PR will appear in our next
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
-
VectorStores / Retrievers / Memory
- @dev2049
-->
@dev2049
@vowelparrot
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
Fixes#5720.
A more in-depth discussion is in my comment here:
https://github.com/hwchase17/langchain/issues/5720#issuecomment-1577047018
In a nutshell, there has been a subtle change in the latest version of
GPT4Alls Python bindings. The change I submitted yesterday is compatible
with this version, however, this version is as of yet unreleased and
thus the code change breaks Langchain's wrapper under the currently
released version of GPT4All.
This pull request proposes a backwards-compatible solution.
fix for the sqlalchemy deprecated declarative_base import :
```
MovedIn20Warning: The ``declarative_base()`` function is now available as sqlalchemy.orm.declarative_base(). (deprecated since: 2.0) (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9)
Base = declarative_base() # type: Any
```
Import is wrapped in an try catch Block to fallback to the old import if
needed.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Token text splitter for sentence transformers
The current TokenTextSplitter only works with OpenAi models via the
`tiktoken` package. This is not clear from the name `TokenTextSplitter`.
In this (first PR) a token based text splitter for sentence transformer
models is added. In the future I think we should work towards injecting
a tokenizer into the TokenTextSplitter to make ti more flexible.
Could perhaps be reviewed by @dev2049
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Raises exception if OutputParsers receive a response with both a valid
action and a final answer
Currently, if an OutputParser receives a response which includes both an
action and a final answer, they return a FinalAnswer object. This allows
the parser to accept responses which propose an action and hallucinate
an answer without the action being parsed or taken by the agent.
This PR changes the logic to:
1. store a variable checking whether a response contains the
`FINAL_ANSWER_ACTION` (this is the easier condition to check).
2. store a variable checking whether the response contains a valid
action
3. if both are present, raise a new exception stating that both are
present
4. if an action is present, return an AgentAction
5. if an answer is present, return an AgentAnswer
6. if neither is present, raise the relevant exception based around the
action format (these have been kept consistent with the prior exception
messages)
Disclaimer:
* Existing mock data included strings which did include an action and an
answer. This might indicate that prioritising returning AgentAnswer was
always correct, and I am patching out desired behaviour? @hwchase17 to
advice. Curious if there are allowed cases where this is not
hallucinating, and we do want the LLM to output an action which isn't
taken.
* I have not passed `send_to_llm` through this new exception
Fixes#5601
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@hwchase17 - project lead
@vowelparrot
All the queries to the database are done based on the SessionId
property, this will optimize how Mongo retrieves all messages from a
session
#### Who can review?
Tag maintainers/contributors who might be interested:
@dev2049
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes#5638. Retitles "Amazon Bedrock" page to "Bedrock" so that the
Integrations section of the left nav is properly sorted in alphabetical
order.
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@vowelparrot:
Minor change to the SQL agent:
Tells agent to introspect the schema of the most relevant tables, I
found this to dramatically decrease the chance that the agent wastes
times guessing column names.
Fixes https://github.com/hwchase17/langchain/issues/5067
Verified the following code now works correctly:
```
db = Chroma(persist_directory=index_directory(index_name), embedding_function=embeddings)
retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.4})
docs = retriever.get_relevant_documents(query)
```
## Improve Error Messaging for APOC Procedure Failure in Neo4jGraph
This commit revises the error message provided when the
'apoc.meta.data()' procedure fails. Previously, the message simply
instructed the user to install the APOC plugin in Neo4j. The new error
message is more specific.
Also removed an unnecessary newline in the Cypher statement variable:
`node_properties_query`.
Fixes#5545
## Who can review?
- @vowelparrot
- @dev2049
This commit addresses a ValueError occurring when the YoutubeLoader
class tries to add datetime metadata from a YouTube video's publish
date. The error was happening because the ChromaDB metadata validation
only accepts str, int, or float data types.
In the `_get_video_info` method of the `YoutubeLoader` class, the
publish date retrieved from the YouTube video was of datetime type. This
commit fixes the issue by converting the datetime object to a string
before adding it to the metadata dictionary.
Additionally, this commit introduces error handling in the
`_get_video_info` method to ensure that all metadata fields have valid
values. If a metadata field is found to be None, a default value is
assigned. This prevents potential errors during metadata validation when
metadata fields are None.
The file modified in this commit is youtube.py.
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
# refactor BaseStringMessagePromptTemplate from_template method
Refactor the `from_template` method of the
`BaseStringMessagePromptTemplate` class to allow passing keyword
arguments to the `from_template` method of `PromptTemplate`.
Enable the usage of arguments like `template_format`.
In my scenario, I intend to utilize Jinja2 for formatting the human
message prompt in the chat template.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Models
- @hwchase17
- @agola11
- @jonasalexander
-->
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
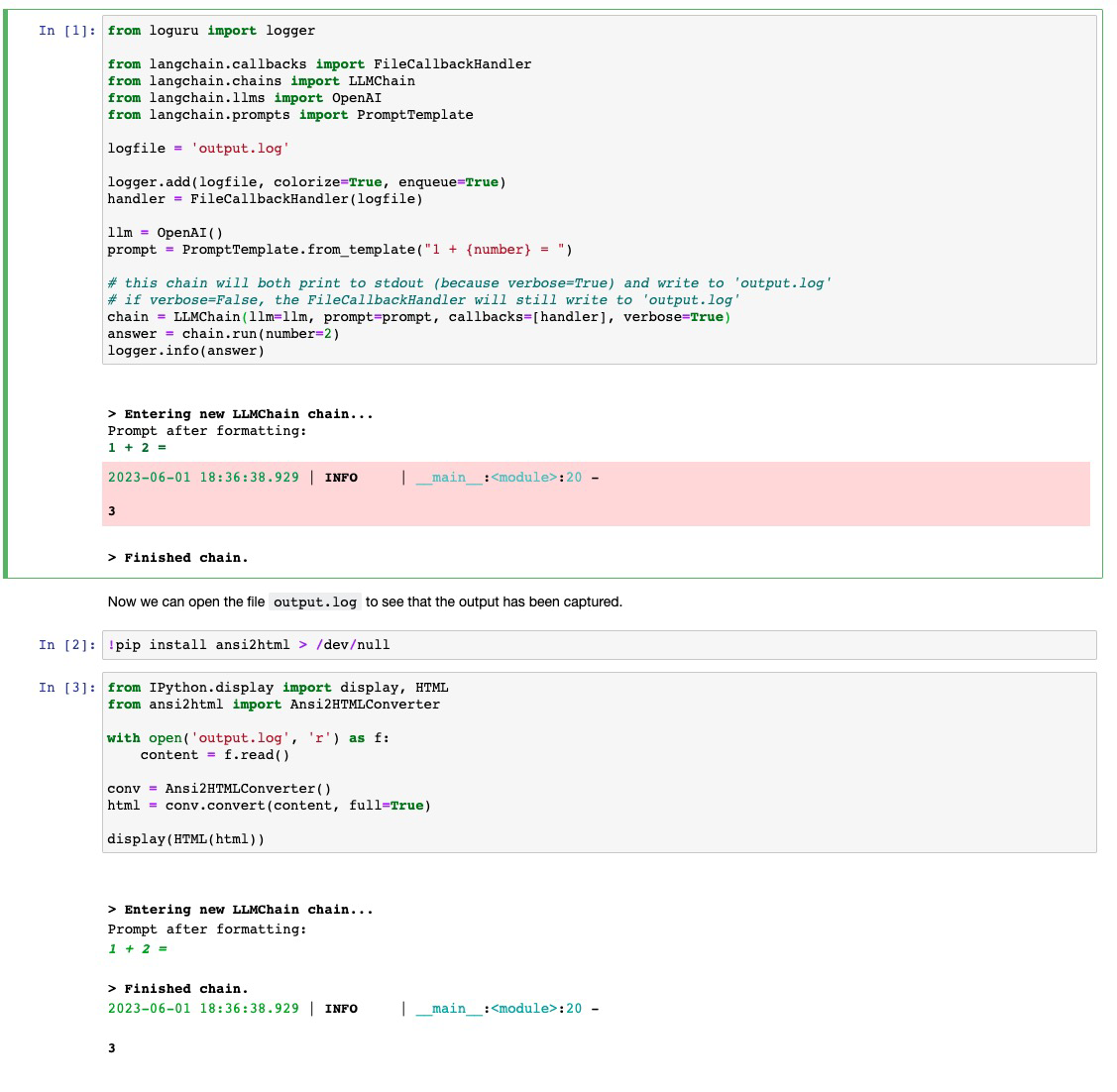
# like
[StdoutCallbackHandler](https://github.com/hwchase17/langchain/blob/master/langchain/callbacks/stdout.py),
but writes to a file
When running experiments I have found myself wanting to log the outputs
of my chains in a more lightweight way than using WandB tracing. This PR
contributes a callback handler that writes to file what
`StdoutCallbackHandler` would print.
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
## Example Notebook
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
See the included `filecallbackhandler.ipynb` notebook for usage. Would
it be better to include this notebook under `modules/callbacks` or under
`integrations/`?
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Created fix for 5475
Currently in PGvector, we do not have any function that returns the
instance of an existing store. The from_documents always adds embeddings
and then returns the store. This fix is to add a function that will
return the instance of an existing store
Also changed the jupyter example for PGVector to show the example of
using the function
<!-- Remove if not applicable -->
Fixes # 5475
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
@dev2049
@hwchase17
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: rajib76 <rajib76@yahoo.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
This PR corrects a minor typo in the Momento chat message history
notebook and also expands the title from "Momento" to "Momento Chat
History", inline with other chat history storage providers.
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
cc @dev2049 who reviewed the original integration
# Your PR Title (What it does)
Fixes the pgvector python example notebook : one of the variables was
not referencing anything
## Before submitting
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
# Ensure parameters are used by vertexai chat models (PaLM2)
The current version of the google aiplatform contains a bug where
parameters for a chat model are not used as intended.
See https://github.com/googleapis/python-aiplatform/issues/2263
Params can be passed both to start_chat() and send_message(); however,
the parameters passed to start_chat() will not be used if send_message()
is called without the overrides. This is due to the defaults in
send_message() being global values rather than None (there is code in
send_message() which would use the params from start_chat() if the param
passed to send_message() evaluates to False, but that won't happen as
the defaults are global values).
Fixes # 5531
@hwchase17
@agola11
# Make FinalStreamingStdOutCallbackHandler more robust by ignoring new
lines & white spaces
`FinalStreamingStdOutCallbackHandler` doesn't work out of the box with
`ChatOpenAI`, as it tokenized slightly differently than `OpenAI`. The
response of `OpenAI` contains the tokens `["\nFinal", " Answer", ":"]`
while `ChatOpenAI` contains `["Final", " Answer", ":"]`.
This PR make `FinalStreamingStdOutCallbackHandler` more robust by
ignoring new lines & white spaces when determining if the answer prefix
has been reached.
Fixes#5433
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
Tracing / Callbacks
- @agola11
Twitter: [@UmerHAdil](https://twitter.com/@UmerHAdil) | Discord:
RicChilligerDude#7589
# Adds the option to pass the original prompt into the AgentExecutor for
PlanAndExecute agents
This PR allows the user to optionally specify that they wish for the
original prompt/objective to be passed into the Executor agent used by
the PlanAndExecute agent. This solves a potential problem where the plan
is formed referring to some context contained in the original prompt,
but which is not included in the current prompt.
Currently, the prompt format given to the Executor is:
```
System: Respond to the human as helpfully and accurately as possible. You have access to the following tools:
<Tool and Action Description>
<Output Format Description>
Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary. Respond directly if appropriate. Format is Action:```$JSON_BLOB```then Observation:.
Thought:
Human: <Previous steps>
<Current step>
```
This PR changes the final part after `Human:` to optionally insert the
objective:
```
Human: <objective>
<Previous steps>
<Current step>
```
I have given a specific example in #5400 where the context of a database
path is lost, since the plan refers to the "given path".
The PR has been linted and formatted. So that existing behaviour is not
changed, I have defaulted the argument to `False` and added it as the
last argument in the signature, so it does not cause issues for any
users passing args positionally as opposed to using keywords.
Happy to take any feedback or make required changes!
Fixes#5400
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@vowelparrot
---------
Co-authored-by: Nathan Azrak <nathan.azrak@gmail.com>
# Implements support for Personal Access Token Authentication in the
ConfluenceLoader
Fixes#5191
Implements a new optional parameter for the ConfluenceLoader: `token`.
This allows the use of personal access authentication when using the
on-prem server version of Confluence.
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev @Jflick58
Twitter Handle: felipe_yyc
---------
Co-authored-by: Felipe <feferreira@ea.com>
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Update confluence.py to return spaces between elements like headers
and links.
Please see
https://stackoverflow.com/questions/48913975/how-to-return-nicely-formatted-text-in-beautifulsoup4-when-html-text-is-across-m
Given:
```html
<address>
183 Main St<br>East Copper<br>Massachusetts<br>U S A<br>
MA 01516-113
</address>
```
The document loader currently returns:
```
'183 Main StEast CopperMassachusettsU S A MA 01516-113'
```
After this change, the document loader will return:
```
183 Main St East Copper Massachusetts U S A MA 01516-113
```
@eyurtsev would you prefer this to be an option that can be passed in?
# Reduce DB query error rate
If you use sql agent of `SQLDatabaseToolkit` to query data, it is prone
to errors in query fields and often uses fields that do not exist in
database tables for queries. However, the existing prompt does not
effectively make the agent aware that there are problems with the fields
they query. At this time, we urgently need to improve the prompt so that
the agent realizes that they have queried non-existent fields and allows
them to use the `schema_sql_db`, that is,` ListSQLDatabaseTool` first
queries the corresponding fields in the table in the database, and then
uses `QuerySQLDatabaseTool` for querying.
There is a demo of my project to show this problem.
**Original Agent**
```python
def create_mysql_kit():
db = SQLDatabase.from_uri("mysql+pymysql://xxxxxxx")
llm = OpenAI(temperature=0)
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("Who are the users of sysuser in this system? Tell me the username of all users")
if __name__ == '__main__':
create_mysql_kit()
```
**original output**
```
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input: ""
Observation: app_sysrole_menus, app_bimfacemodel, app_project_users, app_measuringpointdata, auth_user, auth_user_groups, django_apscheduler_djangojobexecution, app_project, app_elementpoint, django_apscheduler_djangojob, django_content_type, app_sysrole, django_admin_log, app_bimfaceaccount, app_measuringpoint_warning_thresholds, app_measuringpoint, app_company, auth_group_permissions, app_sysuser, app_sysuser_companies, app_sysmenu, app_datawarningthreshold, auth_group, auth_permission, app_datawarningrecord, auth_user_user_permissions, app_bimfaceaccount_bimface_models, django_migrations, app_measuringitem, django_session
Thought: I should query the app_sysuser table to get the users in the system.
Action: query_sql_db
Action Input: SELECT username FROM app_sysuser LIMIT 10;
Observation: Error: (pymysql.err.OperationalError) (1054, "Unknown column 'username' in 'field list'")
[SQL: SELECT username FROM app_sysuser LIMIT 10;]
(Background on this error at: https://sqlalche.me/e/20/e3q8)
Thought: I should double check my query before executing it.
Action: query_checker_sql_db
Action Input: SELECT username FROM app_sysuser LIMIT 10;
Observation:
SELECT username FROM app_sysuser LIMIT 10;
Thought: The query looks correct, so I should execute it.
Action: query_sql_db
Action Input: SELECT username FROM app_sysuser LIMIT 10;
Observation: Error: (pymysql.err.OperationalError) (1054, "Unknown column 'username' in 'field list'")
[SQL: SELECT username FROM app_sysuser LIMIT 10;]
(Background on this error at: https://sqlalche.me/e/20/e3q8)
Thought: I should double check my query before executing it.
Action: query_checker_sql_db
Action Input: SELECT name FROM app_sysuser LIMIT 10;
Observation:
SELECT name FROM app_sysuser LIMIT 10;
Thought: The query looks correct, so I should execute it.
Action: query_sql_db
Action Input: SELECT name FROM app_sysuser LIMIT 10;
Observation: Error: (pymysql.err.OperationalError) (1054, "Unknown column 'name' in 'field list'")
[SQL: SELECT name FROM app_sysuser LIMIT 10;]
(Background on this error at: https://sqlalche.me/e/20/e3q8)
Thought: I should double check my query before executing it.
Action: query_checker_sql_db
Action Input: SELECT id, username FROM app_sysuser LIMIT 10;
Observation:
SELECT id, username FROM app_sysuser LIMIT 10;
Thought: The query looks correct, so I should execute it.
Action: query_sql_db
Action Input: SELECT id, username FROM app_sysuser LIMIT 10;
Observation: Error: (pymysql.err.OperationalError) (1054, "Unknown column 'id' in 'field list'")
[SQL: SELECT id, username FROM app_sysuser LIMIT 10;]
(Background on this error at: https://sqlalche.me/e/20/e3q8)
Thought: I should double check my query before executing it.
Action: query_checker_sql_db
Action Input: SELECT user_id, username FROM app_sysuser LIMIT 10;
Observation:
SELECT user_id, username FROM app_sysuser WHERE user_id IS NOT NULL AND user_id BETWEEN 0 AND 10 UNION ALL SELECT user_id, username FROM app_sysuser WHERE username IS NOT NULL ORDER BY user_id ASC LIMIT 10;
Thought: The query looks correct, so I should execute it.
Action: query_sql_db
Action Input: SELECT user_id, username FROM app_sysuser WHERE user_id IS NOT NULL AND user_id BETWEEN 0 AND 10 UNION ALL SELECT user_id, username FROM app_sysuser WHERE username IS NOT NULL ORDER BY user_id ASC LIMIT 10;
Observation: Error: (pymysql.err.OperationalError) (1054, "Unknown column 'username' in 'field list'")
[SQL: SELECT user_id, username FROM app_sysuser WHERE user_id IS NOT NULL AND user_id BETWEEN 0 AND 10 UNION ALL SELECT user_id, username FROM app_sysuser WHERE username IS NOT NULL ORDER BY user_id ASC LIMIT 10;]
(Background on this error at: https://sqlalche.me/e/20/e3q8)
Thought: I should double check my query before executing it.
Action: query_checker_sql_db
Action Input: SELECT user_id, user_name FROM app_sysuser LIMIT 10;
Observation:
SELECT user_id, user_name FROM app_sysuser WHERE user_id NOT IN (NULL) AND user_name BETWEEN 'A' AND 'Z' UNION ALL SELECT user_id, user_name FROM app_sysuser WHERE user_id IS NOT NULL AND user_name LIKE '%a%' LIMIT 10;
Thought: The query looks correct, so I should execute it.
Action: query_sql_db
Action Input: SELECT user_id, user_name FROM app_sysuser WHERE user_id NOT IN (NULL) AND user_name BETWEEN 'A' AND 'Z' UNION ALL SELECT user_id, user_name FROM app_sysuser WHERE user_id IS NOT NULL AND user_name LIKE '%a%' LIMIT 10;
Observation: []
Thought: I now know the final answer.
Final Answer: There are no users in the sysuser table.
> Finished chain.
Process finished with exit code 0
```
As you can see, agent always use incorrect sql to query the data.
Actually, the username field name of my `app_sysuser` table is
`user_name`, not the `username` believed by the agent.
**Optimized agent output**
```
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input: ""
Observation: app_project_users, django_content_type, app_measuringpoint_warning_thresholds, app_bimfaceaccount_bimface_models, django_session, app_sysuser, django_migrations, app_bimfacemodel, app_elementpoint, app_measuringpoint, django_apscheduler_djangojobexecution, auth_permission, app_sysuser_companies, app_measuringpointdata, app_measuringitem, app_sysrole_menus, django_admin_log, auth_group, django_apscheduler_djangojob, app_sysmenu, app_project, app_bimfaceaccount, app_datawarningthreshold, app_datawarningrecord, auth_user_groups, auth_user_user_permissions, auth_group_permissions, auth_user, app_company, app_sysrole
Thought: I should query the app_sysuser table to get the usernames of all the users.
Action: query_sql_db
Action Input: SELECT username FROM app_sysuser
Observation: Error: (pymysql.err.OperationalError) (1054, "Unknown column 'username' in 'field list'")
[SQL: SELECT username FROM app_sysuser]
(Background on this error at: https://sqlalche.me/e/20/e3q8)
Thought: I should use the schema_sql_db tool to get the correct table fields.
Action: schema_sql_db
Action Input: app_sysuser
Observation:
CREATE TABLE app_sysuser (
user_id INTEGER NOT NULL AUTO_INCREMENT,
user_account VARCHAR(50) COLLATE utf8mb4_general_ci NOT NULL,
user_password VARCHAR(255) COLLATE utf8mb4_general_ci NOT NULL,
user_name VARCHAR(50) COLLATE utf8mb4_general_ci NOT NULL,
user_avatar VARCHAR(255) COLLATE utf8mb4_general_ci,
user_email VARCHAR(254) COLLATE utf8mb4_general_ci,
user_phone VARCHAR(20) COLLATE utf8mb4_general_ci,
user_create_time DATETIME(6) NOT NULL,
user_update_time DATETIME(6) NOT NULL,
user_status SMALLINT,
role_id_id INTEGER,
PRIMARY KEY (user_id),
CONSTRAINT app_sysuser_role_id_id_51b50f39_fk_app_sysrole_role_id FOREIGN KEY(role_id_id) REFERENCES app_sysrole (role_id)
)COLLATE utf8mb4_general_ci DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB
/*
3 rows from app_sysuser table:
user_id user_account user_password user_name user_avatar user_email user_phone user_create_time user_update_time user_status role_id_id
xxxxxxxxxxxxxx
*/
Thought: I should query the app_sysuser table to get the usernames of all the users.
Action: query_sql_db
Action Input: SELECT user_account FROM app_sysuser LIMIT 10
Observation: [('baiyun',), ('eatrice',), ('lisi',), ('pingxiang',), ('wangwu',), ('zeeland',), ('zsj',), ('zzw',)]
Thought: I now know the final answer
Final Answer: The usernames of the users in the sysuser table are baiyun, eatrice, lisi, pingxiang, wangwu, zeeland, zsj, and zzw.
> Finished chain.
Process finished with exit code 0
```
I have tested about 10 related prompts and they all work properly, with
a much lower error rate compared to before
## Who can review?
@vowelparrot
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# minor refactor of GenerativeAgentMemory
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
-->
<!-- Remove if not applicable -->
- refactor `format_memories_detail` to be more reusable
- modified prompts for getting topics for reflection and for generating
insights
- update `characters.ipynb` to reflect changes
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
@vowelparrot
@hwchase17
@dev2049
# docs: modules pages simplified
Fixied #5627 issue
Merged several repetitive sections in the `modules` pages. Some texts,
that were hard to understand, were also simplified.
## Who can review?
@hwchase17
@dev2049
# Fixed multi input prompt for MapReduceChain
Added `kwargs` support for inner chains of `MapReduceChain` via
`from_params` method
Currently the `from_method` method of intialising `MapReduceChain` chain
doesn't work if prompt has multiple inputs. It happens because it uses
`StuffDocumentsChain` and `MapReduceDocumentsChain` underneath, both of
them require specifying `document_variable_name` if `prompt` of their
`llm_chain` has more than one `input`.
With this PR, I have added support for passing their respective `kwargs`
via the `from_params` method.
## Fixes https://github.com/hwchase17/langchain/issues/4752
## Who can review?
@dev2049 @hwchase17 @agola11
---------
Co-authored-by: imeckr <chandanroutray2012@gmail.com>
# Unstructured Excel Loader
Adds an `UnstructuredExcelLoader` class for `.xlsx` and `.xls` files.
Works with `unstructured>=0.6.7`. A plain text representation of the
Excel file will be available under the `page_content` attribute in the
doc. If you use the loader in `"elements"` mode, an HTML representation
of the Excel file will be available under the `text_as_html` metadata
key. Each sheet in the Excel document is its own document.
### Testing
```python
from langchain.document_loaders import UnstructuredExcelLoader
loader = UnstructuredExcelLoader(
"example_data/stanley-cups.xlsx",
mode="elements"
)
docs = loader.load()
```
## Who can review?
@hwchase17
@eyurtsev
# fix for the import issue
Added document loader classes from [`figma`, `iugu`, `onedrive_file`] to
`document_loaders/__inti__.py` imports
Also sorted `__all__`
Fixed#5623 issue
# Chroma update_document full document embeddings bugfix
Chroma update_document takes a single document, but treats the
page_content sting of that document as a list when getting the new
document embedding.
This is a two-fold problem, where the resulting embedding for the
updated document is incorrect (it's only an embedding of the first
character in the new page_content) and it calls the embedding function
for every character in the new page_content string, using many tokens in
the process.
Fixes#5582
Co-authored-by: Caleb Ellington <calebellington@Calebs-MBP.hsd1.ca.comcast.net>
Co-authored-by: Alvaro Bartolome <alvarobartt@gmail.com>
Co-authored-by: Daniel Vila Suero <daniel@argilla.io>
Co-authored-by: Tom Aarsen <37621491+tomaarsen@users.noreply.github.com>
Co-authored-by: Tom Aarsen <Cubiegamedev@gmail.com>
# Fix Qdrant ids creation
There has been a bug in how the ids were created in the Qdrant vector
store. They were previously calculated based on the texts. However,
there are some scenarios in which two documents may have the same piece
of text but different metadata, and that's a valid case. Deduplication
should be done outside of insertion.
It has been fixed and covered with the integration tests.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Create elastic_vector_search.ElasticKnnSearch class
This extends `langchain/vectorstores/elastic_vector_search.py` by adding
a new class `ElasticKnnSearch`
Features:
- Allow creating an index with the `dense_vector` mapping compataible
with kNN search
- Store embeddings in index for use with kNN search (correct mapping
creates HNSW data structure)
- Perform approximate kNN search
- Perform hybrid BM25 (`query{}`) + kNN (`knn{}`) search
- perform knn search by either providing a `query_vector` or passing a
hosted `model_id` to use query_vector_builder to automatically generate
a query_vector at search time
Connection options
- Using `cloud_id` from Elastic Cloud
- Passing elasticsearch client object
search options
- query
- k
- query_vector
- model_id
- size
- source
- knn_boost (hybrid search)
- query_boost (hybrid search)
- fields
This also adds examples to
`docs/modules/indexes/vectorstores/examples/elasticsearch.ipynb`
Fixes # [5346](https://github.com/hwchase17/langchain/issues/5346)
cc: @dev2049
-->
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>