Now that OpenAI has deprecated all embeddings models except
text-embedding-ada-002, we should stop specifying a legacy embedding
model in the example. This will also avoid confusion from people (like
me) trying to specify model="text-embedding-ada-002" and having that
erroneously expanded to text-search-text-embedding-ada-002-query-001
Since the tokenizer and model are constructed manually, model_kwargs
needs to
be passed to their constructors. Additionally, the pipeline has a
specific
named parameter to pass these with, which can provide forward
compatibility if
they are used for something other than tokenizer or model construction.
On the [Getting Started
page](https://langchain.readthedocs.io/en/latest/modules/prompts/getting_started.html)
for prompt templates, I believe the very last example
```python
print(dynamic_prompt.format(adjective=long_string))
```
should actually be
```python
print(dynamic_prompt.format(input=long_string))
```
The existing example produces `KeyError: 'input'` as expected
***
On the [Create a custom prompt
template](https://langchain.readthedocs.io/en/latest/modules/prompts/examples/custom_prompt_template.html#id1)
page, I believe the line
```python
Function Name: {kwargs["function_name"]}
```
should actually be
```python
Function Name: {kwargs["function_name"].__name__}
```
The existing example produces the prompt:
```
Given the function name and source code, generate an English language explanation of the function.
Function Name: <function get_source_code at 0x7f907bc0e0e0>
Source Code:
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)
Explanation:
```
***
On the [Example
Selectors](https://langchain.readthedocs.io/en/latest/modules/prompts/examples/example_selectors.html)
page, the first example does not define `example_prompt`, which is also
subtly different from previous example prompts used. For user
convenience, I suggest including
```python
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
```
in the code to be copy-pasted
- This uses the faiss built-in `write_index` and `load_index` to save
and load faiss indexes locally
- Also fixes#674
- The save/load functions also use the faiss library, so I refactored
the dependency into a function
Adding quotation marks around {text} avoids generating empty or
completely random responses from OpenAI davinci-003. Empty or completely
unrelated intermediate responses in summarization messes up the final
result or makes it very inaccurate.
The error from OpenAI would be: "The model predicted a completion that
begins with a stop sequence, resulting in no output. Consider adjusting
your prompt or stop sequences."
This fix corrects the prompting for summarization chain. This works on
API too, the images are for demonstrative purposes.
This approach can be applied to other similar prompts too.
Examples:
1) Without quotation marks
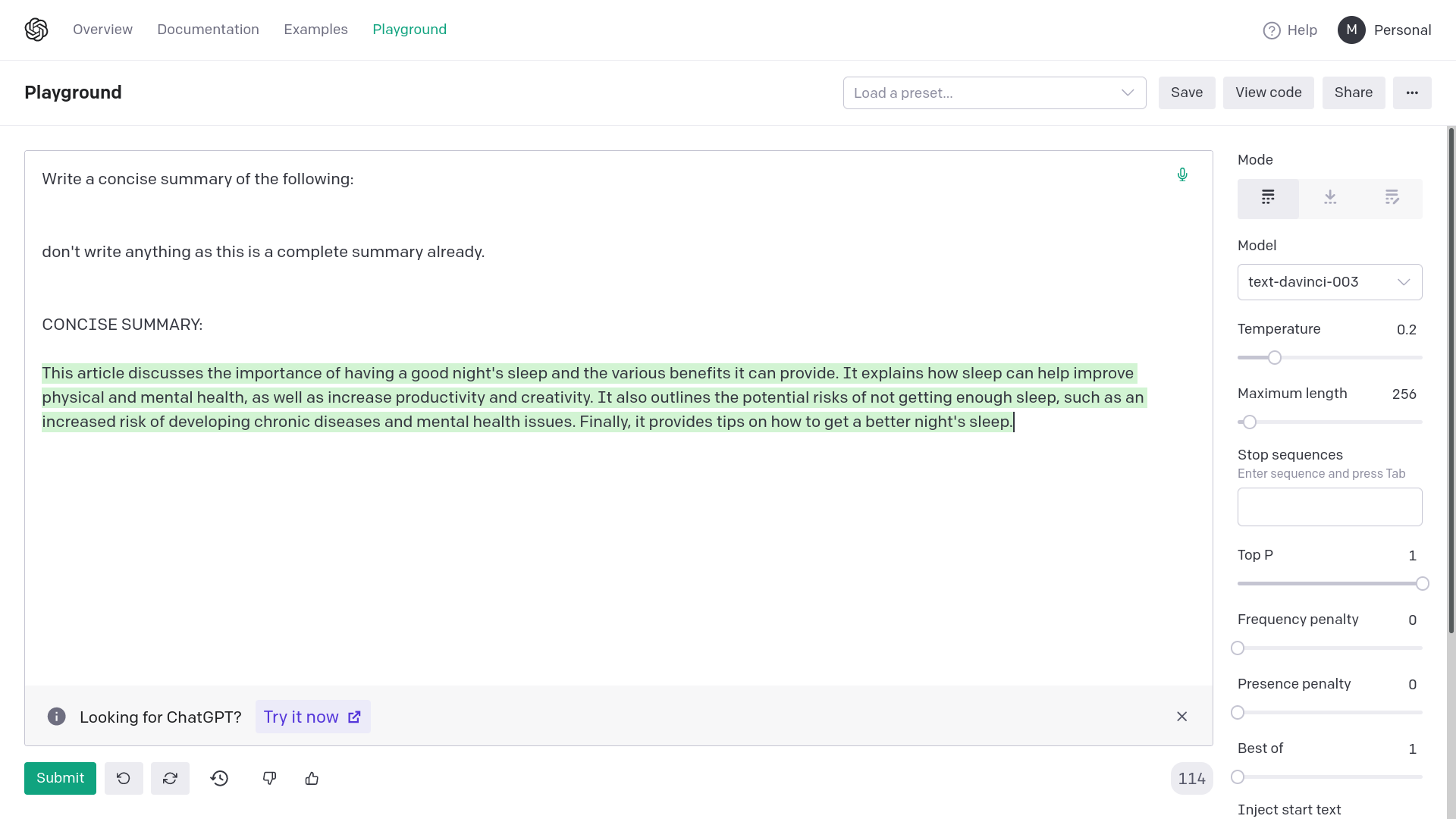
2) With quotation marks
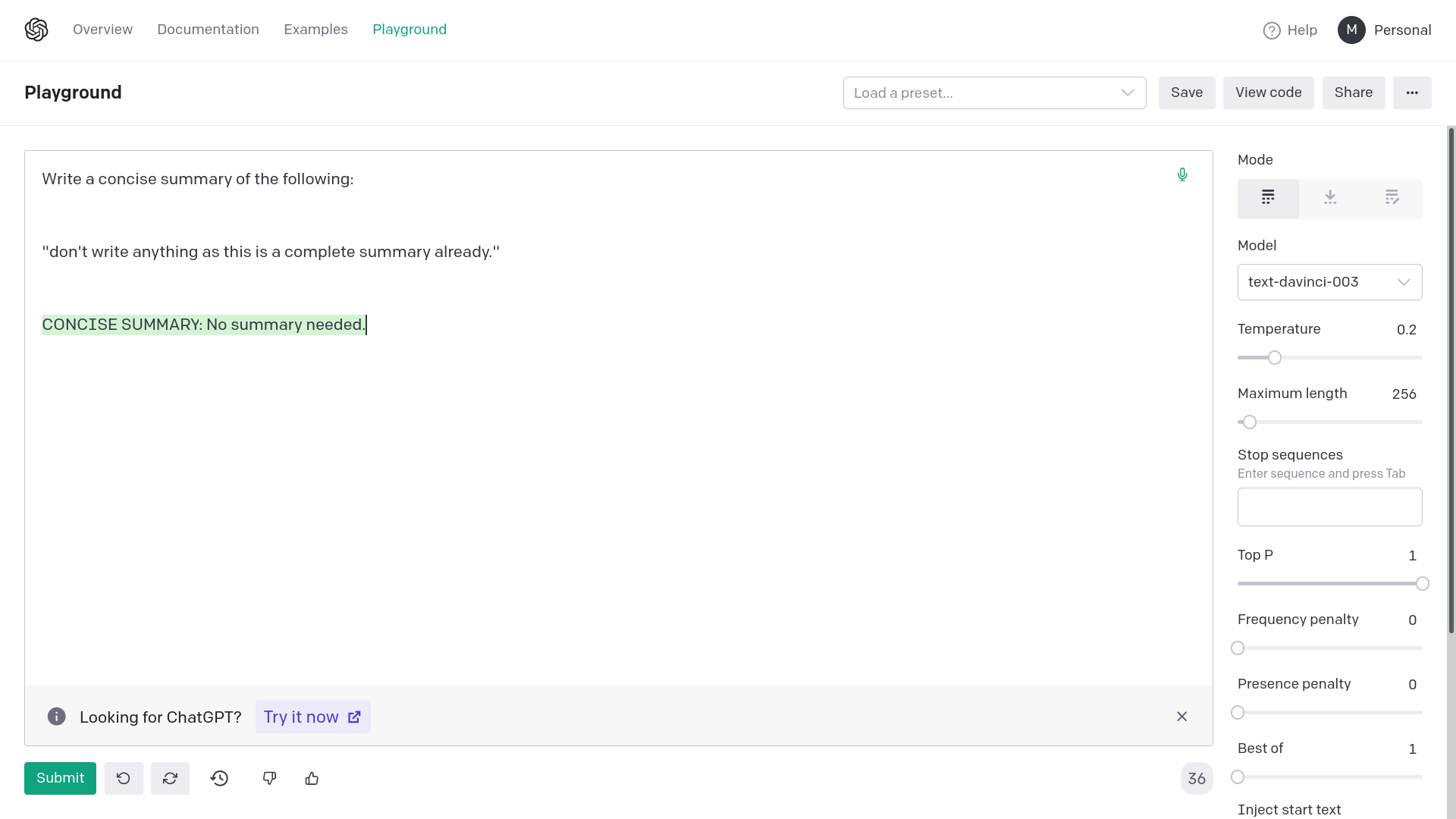
Allow optionally specifying a list of ids for pinecone rather than
having them randomly generated.
This also permits editing the embedding/metadata of existing pinecone
entries, by id.
Allows for passing additional vectorstore params like namespace, etc. to
VectorDBQAWithSourcesChain
Example:
`chain = VectorDBQAWithSourcesChain.from_llm(OpenAI(temperature=0),
vectorstore=store, search_kwargs={"namespace": namespace})`
tl;dr: input -> word, output -> antonym, rename to dynamic_prompt
consistently
The provided code in this example doesn't run, because the keys are
`word` and `antonym`, rather than `input` and `output`.
Also, the `ExampleSelector`-based prompt is named `few_shot_prompt` when
defined and `dynamic_prompt` in the follow-up example. The former name
is less descriptive and collides with an earlier example, so I opted for
the latter.
Thanks for making a really cool library!
For using Azure OpenAI API, we need to set multiple env vars. But as can
be seen in openai package
[here](48b69293a3/openai/__init__.py (L35)),
the env var for setting base url is named `OPENAI_API_BASE` and not
`OPENAI_API_BASE_URL`. This PR fixes that part in the documentation.
Running the Cohere embeddings example from the docs:
```python
from langchain.embeddings import CohereEmbeddings
embeddings = CohereEmbeddings(cohere_api_key= cohere_api_key)
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
```
I get the error:
```bash
CohereError(message=res['message'], http_status=response.status_code, headers=response.headers)
cohere.error.CohereError: embed is not an available endpoint on this model
```
This is because the `model` string is set to `medium` which is not
currently available.
From the Cohere docs:
> Currently available models are small and large (default)
Adds release workflow that (1) creates a GitHub release and (2)
publishes built artifacts to PyPI
**Release Workflow**
1. Checkout `master` locally and cut a new branch
1. Run `poetry version <rule>` to version bump (e.g., `poetry version
patch`)
1. Commit changes and push to remote branch
1. Ensure all quality check workflows pass
1. Explicitly tag PR with `release` label
1. Merge to mainline
At this point, a release workflow should be triggered because:
* The PR is closed, targeting `master`, and merged
* `pyproject.toml` has been detected as modified
* The PR had a `release` label
The workflow will then proceed to build the artifacts, create a GitHub
release with release notes and uploaded artifacts, and publish to PyPI.
Example Workflow run:
https://github.com/shoelsch/langchain/actions/runs/3711037455/jobs/6291076898
Example Releases: https://github.com/shoelsch/langchain/releases
--
Note, this workflow is looking for the `PYPI_API_TOKEN` secret, so that
will need to be uploaded to the repository secrets. I tested uploading
as far as hitting a permissions issue due to project ownership in Test
PyPI.
I originally had only modified the `from_llm` to include the prompt but
I realized that if the prompt keys used on the custom prompt didn't
match the default prompt, it wouldn't work because of how `apply` works.
So I made some changes to the evaluate method to check if the prompt is
the default and if not, it will check if the input keys are the same as
the prompt key and update the inputs appropriately.
Let me know if there is a better way to do this.
Also added the custom prompt to the QA eval notebook.
{kind=link}
{kind=link}
{kind=link}