Already supported in the reverse operation in
`_convert_message_to_dict()`, this just provides parity.
@hwchase17
@agola11
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
W.r.t recent changes, ChatPromptTemplate does not accepting partial
variables. This PR should fix that issue.
Fixes#6431
#### Who can review?
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
Throwing ToolException when incorrect arguments are passed to tools so
that that agent can course correct them.
# Incorrect argument count handling
I was facing an error where the agent passed incorrect arguments to
tools. As per the discussions going around, I started throwing
ToolException to allow the model to course correct.
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
#### Before submitting
Add memory support for `OpenAIFunctionsAgent` like
`StructuredChatAgent`.
#### Who can review?
@hwchase17
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
In LangChain, all module classes are enumerated in the `__init__.py`
file of the correspondent module. But some classes were missed and were
not included in the module `__init__.py`
This PR:
- added the missed classes to the module `__init__.py` files
- `__init__.py:__all_` variable value (a list of the class names) was
sorted
- `langchain.tools.sql_database.tool.QueryCheckerTool` was renamed into
the `QuerySQLCheckerTool` because it conflicted with
`langchain.tools.spark_sql.tool.QueryCheckerTool`
- changes to `pyproject.toml`:
- added `pgvector` to `pyproject.toml:extended_testing`
- added `pandas` to
`pyproject.toml:[tool.poetry.group.test.dependencies]`
- commented out the `streamlit` from `collbacks/__init__.py`, It is
because now the `streamlit` requires Python >=3.7, !=3.9.7
- fixed duplicate names in `tools`
- fixed correspondent ut-s
#### Who can review?
@hwchase17
@dev2049
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
## Add Solidity programming language support for code splitter.
Twitter: @0xjord4n_
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@hwchase17
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @hwchase17
VectorStores / Retrievers / Memory
- @dev2049
-->
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#### Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
Fixes (not reported) an error that may occur in some cases in the
RecursiveCharacterTextSplitter.
An empty `new_separators` array ([]) would end up in the else path of
the condition below and used in a function where it is expected to be
non empty.
```python
if new_separators is None:
...
else:
# _split_text() expects this array to be non-empty!
other_info = self._split_text(s, new_separators)
```
resulting in an `IndexError`
```python
def _split_text(self, text: str, separators: List[str]) -> List[str]:
"""Split incoming text and return chunks."""
final_chunks = []
# Get appropriate separator to use
> separator = separators[-1]
E IndexError: list index out of range
langchain/text_splitter.py:425: IndexError
```
#### Who can review?
@hwchase17 @eyurtsev
---------
Co-authored-by: Harrison Chase <hw.chase.17@gmail.com>
<!--
Thank you for contributing to LangChain! Your PR will appear in our
release under the title you set. Please make sure it highlights your
valuable contribution.
Replace this with a description of the change, the issue it fixes (if
applicable), and relevant context. List any dependencies required for
this change.
After you're done, someone will review your PR. They may suggest
improvements. If no one reviews your PR within a few days, feel free to
@-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd
like us to shout you out on Twitter, please also include your handle!
-->
#### Add start index to metadata in TextSplitter
- Modified method `create_documents` to track start position of each
chunk
- The `start_index` is included in the metadata if the `add_start_index`
parameter in the class constructor is set to `True`
This enables referencing back to the original document, particularly
useful when a specific chunk is retrieved.
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on
network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests,
lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
#### Who can review?
Tag maintainers/contributors who might be interested:
@eyurtsev @agola11
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
This introduces the `YoutubeAudioLoader`, which will load blobs from a
YouTube url and write them. Blobs are then parsed by
`OpenAIWhisperParser()`, as show in this
[PR](https://github.com/hwchase17/langchain/pull/5580), but we extend
the parser to split audio such that each chuck meets the 25MB OpenAI
size limit. As shown in the notebook, this enables a very simple UX:
```
# Transcribe the video to text
loader = GenericLoader(YoutubeAudioLoader([url],save_dir),OpenAIWhisperParser())
docs = loader.load()
```
Tested on full set of Karpathy lecture videos:
```
# Karpathy lecture videos
urls = ["https://youtu.be/VMj-3S1tku0"
"https://youtu.be/PaCmpygFfXo",
"https://youtu.be/TCH_1BHY58I",
"https://youtu.be/P6sfmUTpUmc",
"https://youtu.be/q8SA3rM6ckI",
"https://youtu.be/t3YJ5hKiMQ0",
"https://youtu.be/kCc8FmEb1nY"]
# Directory to save audio files
save_dir = "~/Downloads/YouTube"
# Transcribe the videos to text
loader = GenericLoader(YoutubeAudioLoader(urls,save_dir),OpenAIWhisperParser())
docs = loader.load()
```
# What does this PR do?
Change the HTML tags so that a tag with attributes can be found.
## Before submitting
- [x] Tests added
- [x] CI/CD validated
### Who can review?
Anyone in the community is free to review the PR once the tests have
passed. Feel free to tag
members/contributors who may be interested in your PR.
- Remove the client implementation (this breaks backwards compatibility
for existing testers. I could keep the stub in that file if we want, but
not many people are using it yet
- Add SDK as dependency
- Update the 'run_on_dataset' method to be a function that optionally
accepts a client as an argument
- Remove the langchain plus server implementation (you get it for free
with the SDK now)
We could make the SDK optional for now, but the plan is to use w/in the
tracer so it would likely become a hard dependency at some point.
Fixes#5614
#### Issue
The `***` combination produces an exception when used as a seperator in
`re.split`. Instead `\*\*\*` should be used for regex exprations.
#### Who can review?
@eyurtsev
# OpenAIWhisperParser
This PR creates a new parser, `OpenAIWhisperParser`, that uses the
[OpenAI Whisper
model](https://platform.openai.com/docs/guides/speech-to-text/quickstart)
to perform transcription of audio files to text (`Documents`). Please
see the notebook for usage.
Zep now supports persisting custom metadata with messages and hybrid
search across both message embeddings and structured metadata. This PR
implements custom metadata and enhancements to the
`ZepChatMessageHistory` and `ZepRetriever` classes to implement this
support.
Tag maintainers/contributors who might be interested:
VectorStores / Retrievers / Memory
- @dev2049
---------
Co-authored-by: Daniel Chalef <daniel.chalef@private.org>
# Check if generated Cypher code is wrapped in backticks
Some LLMs like the VertexAI like to explain how they generated the
Cypher statement and wrap the actual code in three backticks:
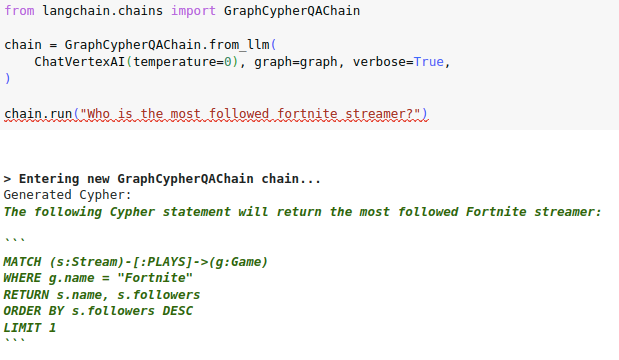
I have observed a similar pattern with OpenAI chat models in a
conversational settings, where multiple user and assistant message are
provided to the LLM to generate Cypher statements, where then the LLM
wants to maybe apologize for previous steps or explain its thoughts.
Interestingly, both OpenAI and VertexAI wrap the code in three backticks
if they are doing any explaining or apologizing. Checking if the
generated cypher is wrapped in backticks seems like a low-hanging fruit
to expand the cypher search to other LLMs and conversational settings.
Raises exception if OutputParsers receive a response with both a valid
action and a final answer
Currently, if an OutputParser receives a response which includes both an
action and a final answer, they return a FinalAnswer object. This allows
the parser to accept responses which propose an action and hallucinate
an answer without the action being parsed or taken by the agent.
This PR changes the logic to:
1. store a variable checking whether a response contains the
`FINAL_ANSWER_ACTION` (this is the easier condition to check).
2. store a variable checking whether the response contains a valid
action
3. if both are present, raise a new exception stating that both are
present
4. if an action is present, return an AgentAction
5. if an answer is present, return an AgentAnswer
6. if neither is present, raise the relevant exception based around the
action format (these have been kept consistent with the prior exception
messages)
Disclaimer:
* Existing mock data included strings which did include an action and an
answer. This might indicate that prioritising returning AgentAnswer was
always correct, and I am patching out desired behaviour? @hwchase17 to
advice. Curious if there are allowed cases where this is not
hallucinating, and we do want the LLM to output an action which isn't
taken.
* I have not passed `send_to_llm` through this new exception
Fixes#5601
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@hwchase17 - project lead
@vowelparrot
# Fixes SQLAlchemy truncating the result if you have a big/text column
with many chars.
SQLAlchemy truncates columns if you try to convert a Row or Sequence to
a string directly
For comparison:
- Before:
```[('Harrison', 'That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio ... (2 characters truncated) ... hat is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio That is my Bio ')]```
- After:
```[('Harrison', 'That is my Bio That is my Bio That is my Bio That is
my Bio That is my Bio That is my Bio That is my Bio That is my Bio That
is my Bio That is my Bio That is my Bio That is my Bio That is my Bio
That is my Bio That is my Bio That is my Bio That is my Bio That is my
Bio That is my Bio That is my Bio ')]```
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
I'm not sure who to tag for chains, maybe @vowelparrot ?
when the LLMs output 'yes|no',BooleanOutputParser can parse it to
'True|False', fix the ValueError in parse().
<!--
when use the BooleanOutputParser in the chain_filter.py, the LLMs output
'yes|no',the function 'parse' will throw ValueError。
-->
Fixes # (issue)
#5396https://github.com/hwchase17/langchain/issues/5396
---------
Co-authored-by: gaofeng27692 <gaofeng27692@hundsun.com>
# Add maximal relevance search to SKLearnVectorStore
This PR implements the maximum relevance search in SKLearnVectorStore.
Twitter handle: jtolgyesi (I submitted also the original implementation
of SKLearnVectorStore)
## Before submitting
Unit tests are included.
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Handles the edge scenario in which the action input is a well formed
SQL query which ends with a quoted column
There may be a cleaner option here (or indeed other edge scenarios) but
this seems to robustly determine if the action input is likely to be a
well formed SQL query in which we don't want to arbitrarily trim off `"`
characters
Fixes#5423
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Agents / Tools / Toolkits
- @vowelparrot
As the title says, I added more code splitters.
The implementation is trivial, so i don't add separate tests for each
splitter.
Let me know if any concerns.
Fixes # (issue)
https://github.com/hwchase17/langchain/issues/5170
## Who can review?
Community members can review the PR once tests pass. Tag
maintainers/contributors who might be interested:
@eyurtsev @hwchase17
---------
Signed-off-by: byhsu <byhsu@linkedin.com>
Co-authored-by: byhsu <byhsu@linkedin.com>
# Creates GitHubLoader (#5257)
GitHubLoader is a DocumentLoader that loads issues and PRs from GitHub.
Fixes#5257
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Added New Trello loader class and documentation
Simple Loader on top of py-trello wrapper.
With a board name you can pull cards and to do some field parameter
tweaks on load operation.
I included documentation and examples.
Included unit test cases using patch and a fixture for py-trello client
class.
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>
# Add ToolException that a tool can throw
This is an optional exception that tool throws when execution error
occurs.
When this exception is thrown, the agent will not stop working,but will
handle the exception according to the handle_tool_error variable of the
tool,and the processing result will be returned to the agent as
observation,and printed in pink on the console.It can be used like this:
```python
from langchain.schema import ToolException
from langchain import LLMMathChain, SerpAPIWrapper, OpenAI
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI
from langchain.tools import BaseTool, StructuredTool, Tool, tool
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0)
llm_math_chain = LLMMathChain(llm=llm, verbose=True)
class Error_tool:
def run(self, s: str):
raise ToolException('The current search tool is not available.')
def handle_tool_error(error) -> str:
return "The following errors occurred during tool execution:"+str(error)
search_tool1 = Error_tool()
search_tool2 = SerpAPIWrapper()
tools = [
Tool.from_function(
func=search_tool1.run,
name="Search_tool1",
description="useful for when you need to answer questions about current events.You should give priority to using it.",
handle_tool_error=handle_tool_error,
),
Tool.from_function(
func=search_tool2.run,
name="Search_tool2",
description="useful for when you need to answer questions about current events",
return_direct=True,
)
]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True,
handle_tool_errors=handle_tool_error)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
```

## Who can review?
- @vowelparrot
---------
Co-authored-by: Dev 2049 <dev.dev2049@gmail.com>