mirror of https://github.com/hwchase17/langchain
docs: Update Portkey provider integration (#20412)
**Description:** Updates the documentation for Portkey and Langchain. Also updates the notebook. The current documentation is fairly old and is non-functional. **Twitter handle:** @portkeyai --------- Co-authored-by: Bagatur <baskaryan@gmail.com>pull/19680/head
parent
0758da8940
commit
7d7a08e458
@ -1,113 +1,174 @@
|
||||
# Portkey
|
||||
|
||||
>[Portkey](https://docs.portkey.ai/overview/introduction) is a platform designed to streamline the deployment
|
||||
> and management of Generative AI applications.
|
||||
> It provides comprehensive features for monitoring, managing models,
|
||||
> and improving the performance of your AI applications.
|
||||
[Portkey](https://portkey.ai) is the Control Panel for AI apps. With it's popular AI Gateway and Observability Suite, hundreds of teams ship **reliable**, **cost-efficient**, and **fast** apps.
|
||||
|
||||
## LLMOps for Langchain
|
||||
|
||||
Portkey brings production readiness to Langchain. With Portkey, you can
|
||||
- [x] view detailed **metrics & logs** for all requests,
|
||||
- [x] enable **semantic cache** to reduce latency & costs,
|
||||
- [x] implement automatic **retries & fallbacks** for failed requests,
|
||||
- [x] add **custom tags** to requests for better tracking and analysis and [more](https://docs.portkey.ai).
|
||||
- [x] Connect to 150+ models through a unified API,
|
||||
- [x] View 42+ **metrics & logs** for all requests,
|
||||
- [x] Enable **semantic cache** to reduce latency & costs,
|
||||
- [x] Implement automatic **retries & fallbacks** for failed requests,
|
||||
- [x] Add **custom tags** to requests for better tracking and analysis and [more](https://portkey.ai/docs).
|
||||
|
||||
### Using Portkey with Langchain
|
||||
Using Portkey is as simple as just choosing which Portkey features you want, enabling them via `headers=Portkey.Config` and passing it in your LLM calls.
|
||||
|
||||
To start, get your Portkey API key by [signing up here](https://app.portkey.ai/login). (Click the profile icon on the top left, then click on "Copy API Key")
|
||||
## Quickstart - Portkey & Langchain
|
||||
Since Portkey is fully compatible with the OpenAI signature, you can connect to the Portkey AI Gateway through the `ChatOpenAI` interface.
|
||||
|
||||
- Set the `base_url` as `PORTKEY_GATEWAY_URL`
|
||||
- Add `default_headers` to consume the headers needed by Portkey using the `createHeaders` helper method.
|
||||
|
||||
To start, get your Portkey API key by [signing up here](https://app.portkey.ai/signup). (Click the profile icon on the bottom left, then click on "Copy API Key") or deploy the open source AI gateway in [your own environment](https://github.com/Portkey-AI/gateway/blob/main/docs/installation-deployments.md).
|
||||
|
||||
Next, install the Portkey SDK
|
||||
```python
|
||||
pip install -U portkey_ai
|
||||
```
|
||||
|
||||
We can now connect to the Portkey AI Gateway by updating the `ChatOpenAI` model in Langchain
|
||||
```python
|
||||
from langchain_openai import ChatOpenAI
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
PORTKEY_API_KEY = "..." # Not needed when hosting your own gateway
|
||||
PROVIDER_API_KEY = "..." # Add the API key of the AI provider being used
|
||||
|
||||
portkey_headers = createHeaders(api_key=PORTKEY_API_KEY,provider="openai")
|
||||
|
||||
llm = ChatOpenAI(api_key=PROVIDER_API_KEY, base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers)
|
||||
|
||||
llm.invoke("What is the meaning of life, universe and everything?")
|
||||
```
|
||||
|
||||
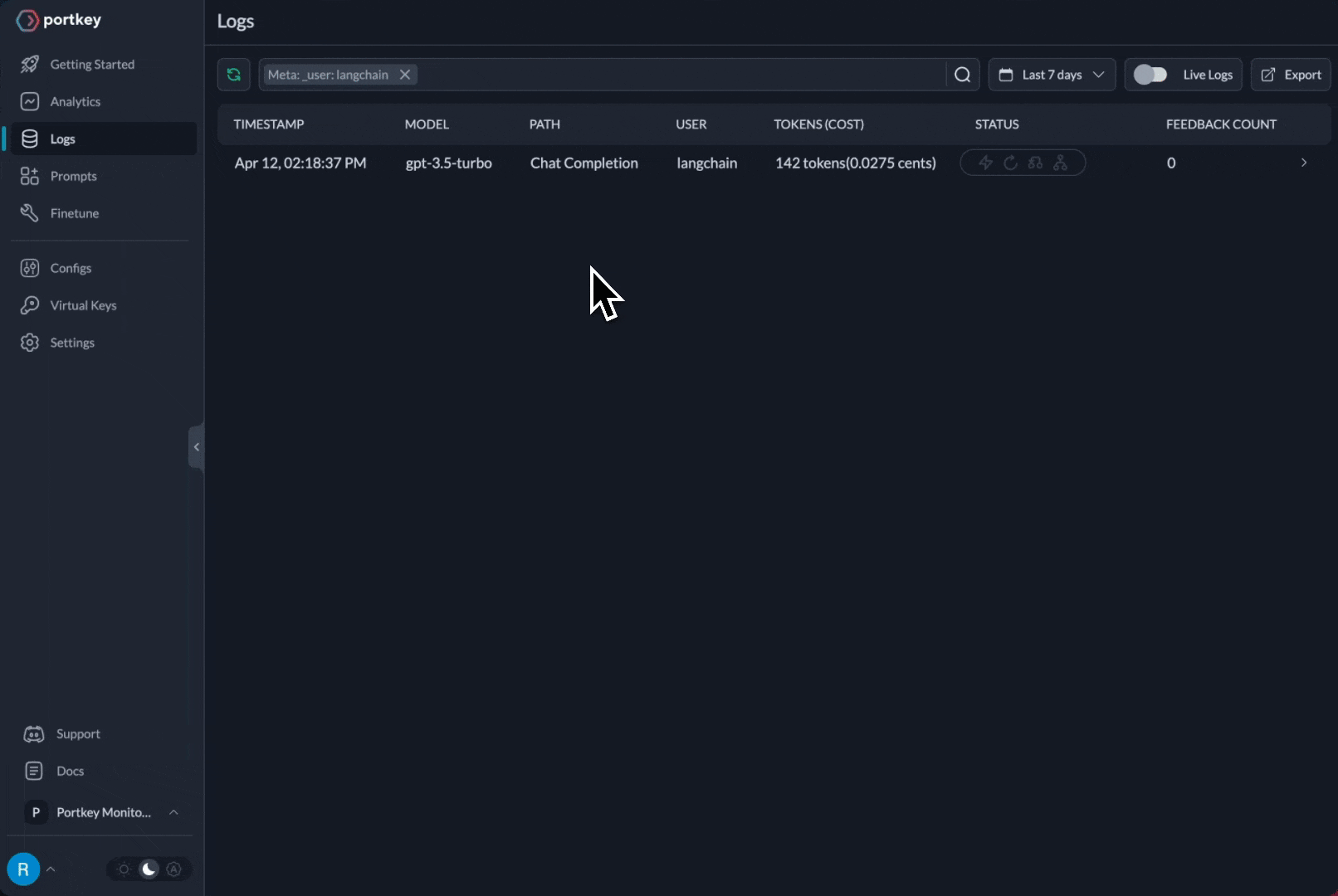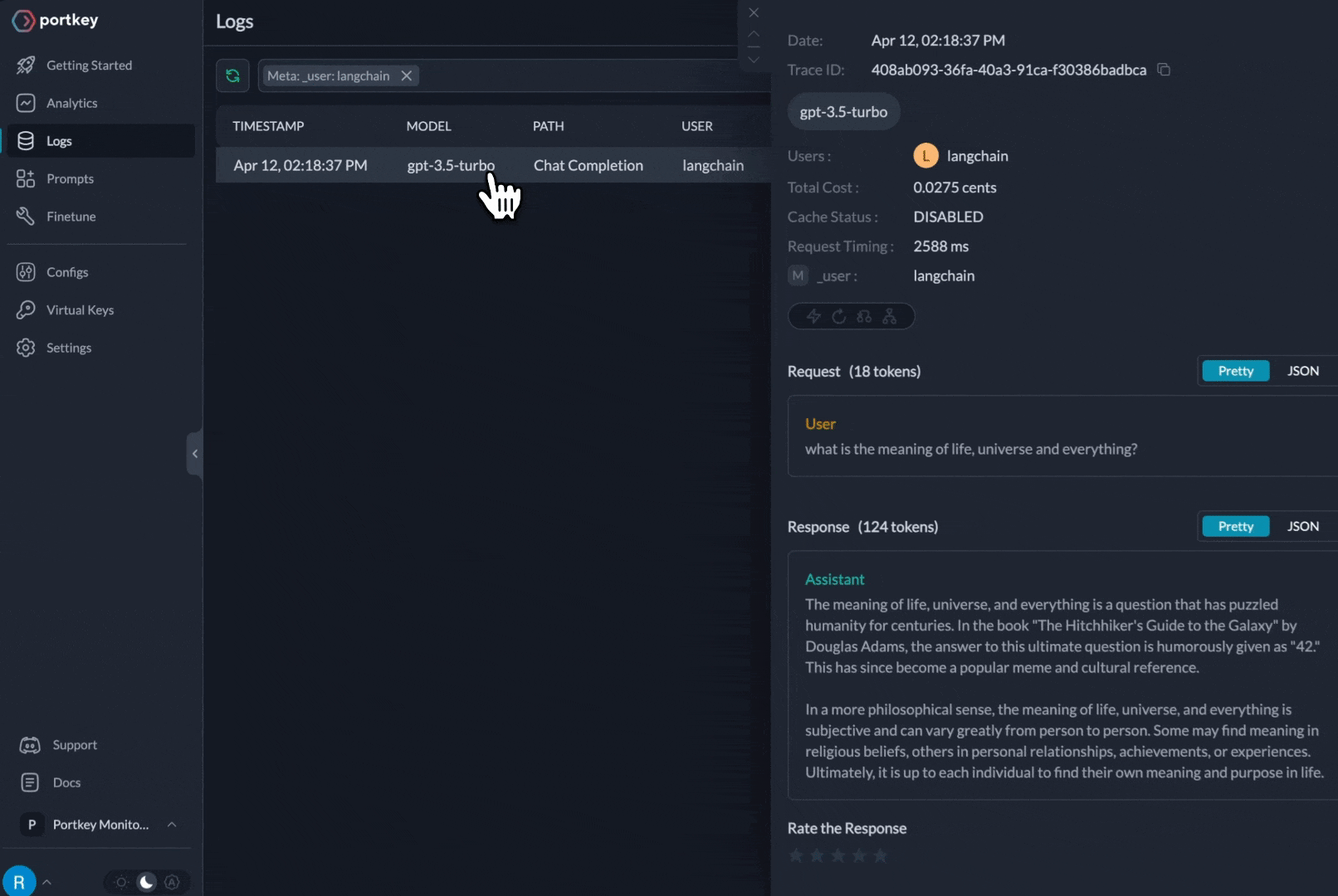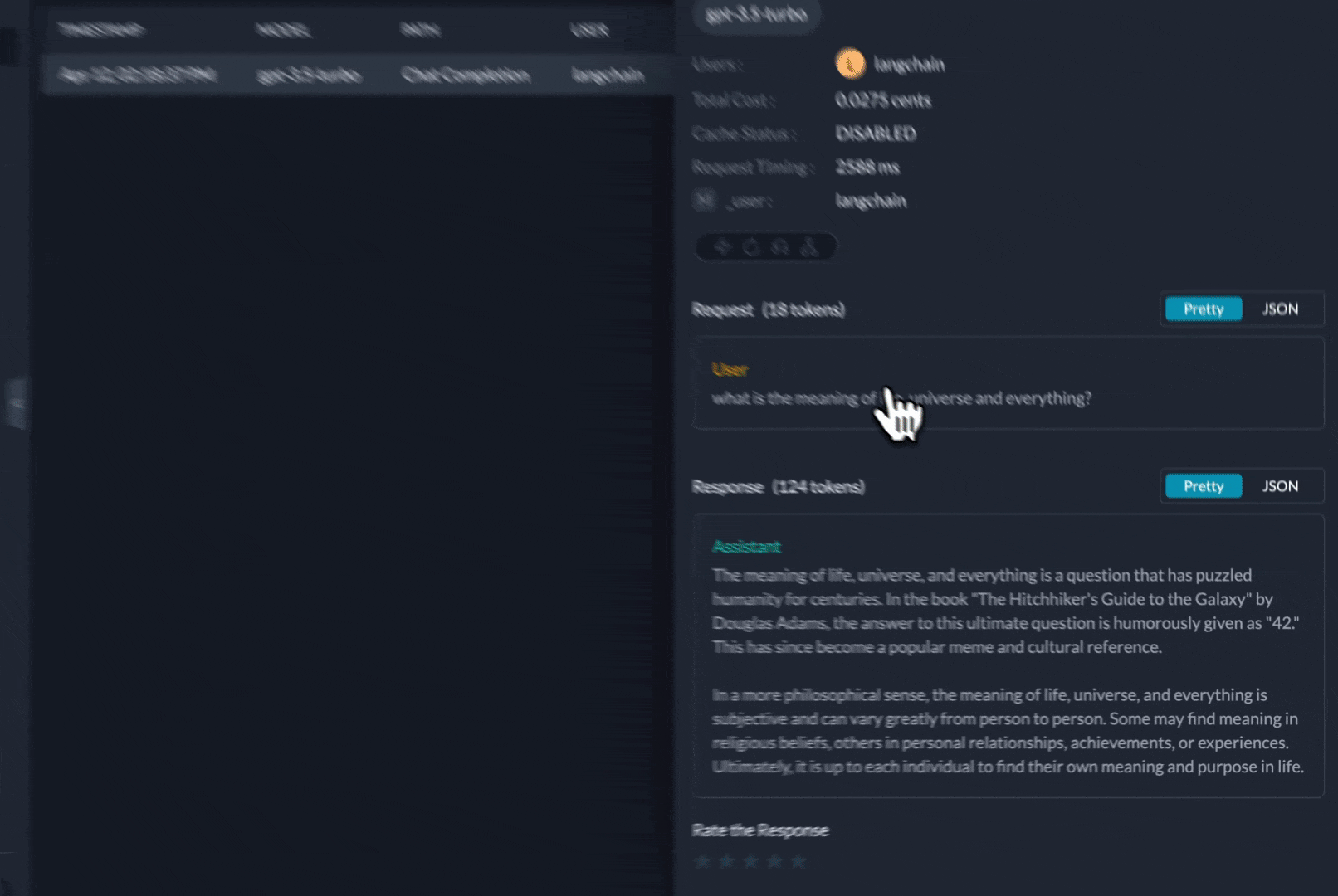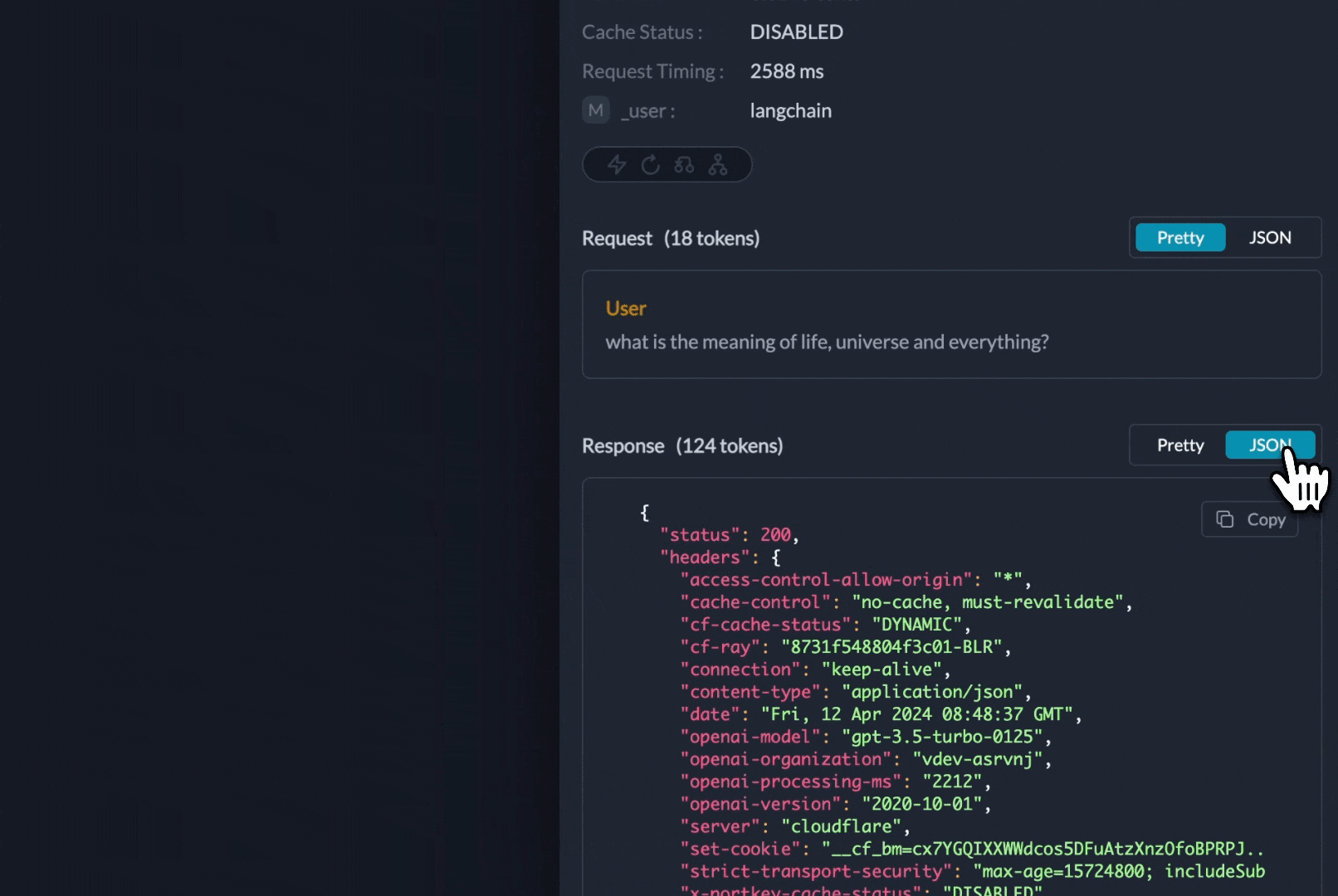
The request is routed through your Portkey AI Gateway to the specified `provider`. Portkey will also start logging all the requests in your account that makes debugging extremely simple.
|
||||
|
||||
|
||||
|
||||
## Using 150+ models through the AI Gateway
|
||||
The power of the AI gateway comes when you're able to use the above code snippet to connect with 150+ models across 20+ providers supported through the AI gateway.
|
||||
|
||||
Let's modify the code above to make a call to Anthropic's `claude-3-opus-20240229` model.
|
||||
|
||||
Portkey supports **[Virtual Keys](https://docs.portkey.ai/docs/product/ai-gateway-streamline-llm-integrations/virtual-keys)** which are an easy way to store and manage API keys in a secure vault. Lets try using a Virtual Key to make LLM calls. You can navigate to the Virtual Keys tab in Portkey and create a new key for Anthropic.
|
||||
|
||||
The `virtual_key` parameter sets the authentication and provider for the AI provider being used. In our case we're using the Anthropic Virtual key.
|
||||
|
||||
> Notice that the `api_key` can be left blank as that authentication won't be used.
|
||||
|
||||
For OpenAI, a simple integration with logging feature would look like this:
|
||||
```python
|
||||
from langchain_openai import OpenAI
|
||||
from langchain_community.utilities import Portkey
|
||||
from langchain_openai import ChatOpenAI
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
PORTKEY_API_KEY = "..."
|
||||
VIRTUAL_KEY = "..." # Anthropic's virtual key we copied above
|
||||
|
||||
portkey_headers = createHeaders(api_key=PORTKEY_API_KEY,virtual_key=VIRTUAL_KEY)
|
||||
|
||||
llm = ChatOpenAI(api_key="X", base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers, model="claude-3-opus-20240229")
|
||||
|
||||
llm.invoke("What is the meaning of life, universe and everything?")
|
||||
```
|
||||
|
||||
# Add the Portkey API Key from your account
|
||||
headers = Portkey.Config(
|
||||
api_key = "<PORTKEY_API_KEY>"
|
||||
The Portkey AI gateway will authenticate the API request to Anthropic and get the response back in the OpenAI format for you to consume.
|
||||
|
||||
The AI gateway extends Langchain's `ChatOpenAI` class making it a single interface to call any provider and any model.
|
||||
|
||||
## Advanced Routing - Load Balancing, Fallbacks, Retries
|
||||
The Portkey AI Gateway brings capabilities like load-balancing, fallbacks, experimentation and canary testing to Langchain through a configuration-first approach.
|
||||
|
||||
Let's take an **example** where we might want to split traffic between `gpt-4` and `claude-opus` 50:50 to test the two large models. The gateway configuration for this would look like the following:
|
||||
|
||||
```python
|
||||
config = {
|
||||
"strategy": {
|
||||
"mode": "loadbalance"
|
||||
},
|
||||
"targets": [{
|
||||
"virtual_key": "openai-25654", # OpenAI's virtual key
|
||||
"override_params": {"model": "gpt4"},
|
||||
"weight": 0.5
|
||||
}, {
|
||||
"virtual_key": "anthropic-25654", # Anthropic's virtual key
|
||||
"override_params": {"model": "claude-3-opus-20240229"},
|
||||
"weight": 0.5
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
We can then use this config in our requests being made from langchain.
|
||||
|
||||
```python
|
||||
portkey_headers = createHeaders(
|
||||
api_key=PORTKEY_API_KEY,
|
||||
config=config
|
||||
)
|
||||
|
||||
llm = OpenAI(temperature=0.9, headers=headers)
|
||||
llm.predict("What would be a good company name for a company that makes colorful socks?")
|
||||
llm = ChatOpenAI(api_key="X", base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers)
|
||||
|
||||
llm.invoke("What is the meaning of life, universe and everything?")
|
||||
```
|
||||
Your logs will be captured on your [Portkey dashboard](https://app.portkey.ai).
|
||||
|
||||
A common Portkey X Langchain use case is to **trace a chain or an agent** and view all the LLM calls originating from that request.
|
||||
When the LLM is invoked, Portkey will distribute the requests to `gpt-4` and `claude-3-opus-20240229` in the ratio of the defined weights.
|
||||
|
||||
You can find more config examples [here](https://docs.portkey.ai/docs/api-reference/config-object#examples).
|
||||
|
||||
## **Tracing Chains & Agents**
|
||||
|
||||
### **Tracing Chains & Agents**
|
||||
Portkey's Langchain integration gives you full visibility into the running of an agent. Let's take an example of a [popular agentic workflow](https://python.langchain.com/docs/use_cases/tool_use/quickstart/#agents).
|
||||
|
||||
We only need to modify the `ChatOpenAI` class to use the AI Gateway as above.
|
||||
|
||||
```python
|
||||
from langchain.agents import AgentType, initialize_agent, load_tools
|
||||
from langchain_openai import OpenAI
|
||||
from langchain_community.utilities import Portkey
|
||||
|
||||
# Add the Portkey API Key from your account
|
||||
headers = Portkey.Config(
|
||||
api_key = "<PORTKEY_API_KEY>",
|
||||
trace_id = "fef659"
|
||||
from langchain import hub
|
||||
from langchain.agents import AgentExecutor, create_openai_tools_agent
|
||||
from langchain_openai import ChatOpenAI
|
||||
from langchain_core.tools import tool
|
||||
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
|
||||
|
||||
prompt = hub.pull("hwchase17/openai-tools-agent")
|
||||
|
||||
portkey_headers = createHeaders(
|
||||
api_key=PORTKEY_API_KEY,
|
||||
virtual_key=OPENAI_VIRTUAL_KEY,
|
||||
trace_id="uuid-uuid-uuid-uuid"
|
||||
)
|
||||
|
||||
llm = OpenAI(temperature=0, headers=headers)
|
||||
tools = load_tools(["serpapi", "llm-math"], llm=llm)
|
||||
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
|
||||
@tool
|
||||
def multiply(first_int: int, second_int: int) -> int:
|
||||
"""Multiply two integers together."""
|
||||
return first_int * second_int
|
||||
|
||||
|
||||
@tool
|
||||
def exponentiate(base: int, exponent: int) -> int:
|
||||
"Exponentiate the base to the exponent power."
|
||||
return base**exponent
|
||||
|
||||
|
||||
tools = [multiply, exponentiate]
|
||||
|
||||
model = ChatOpenAI(api_key="X", base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers, temperature=0)
|
||||
|
||||
# Let's test it out!
|
||||
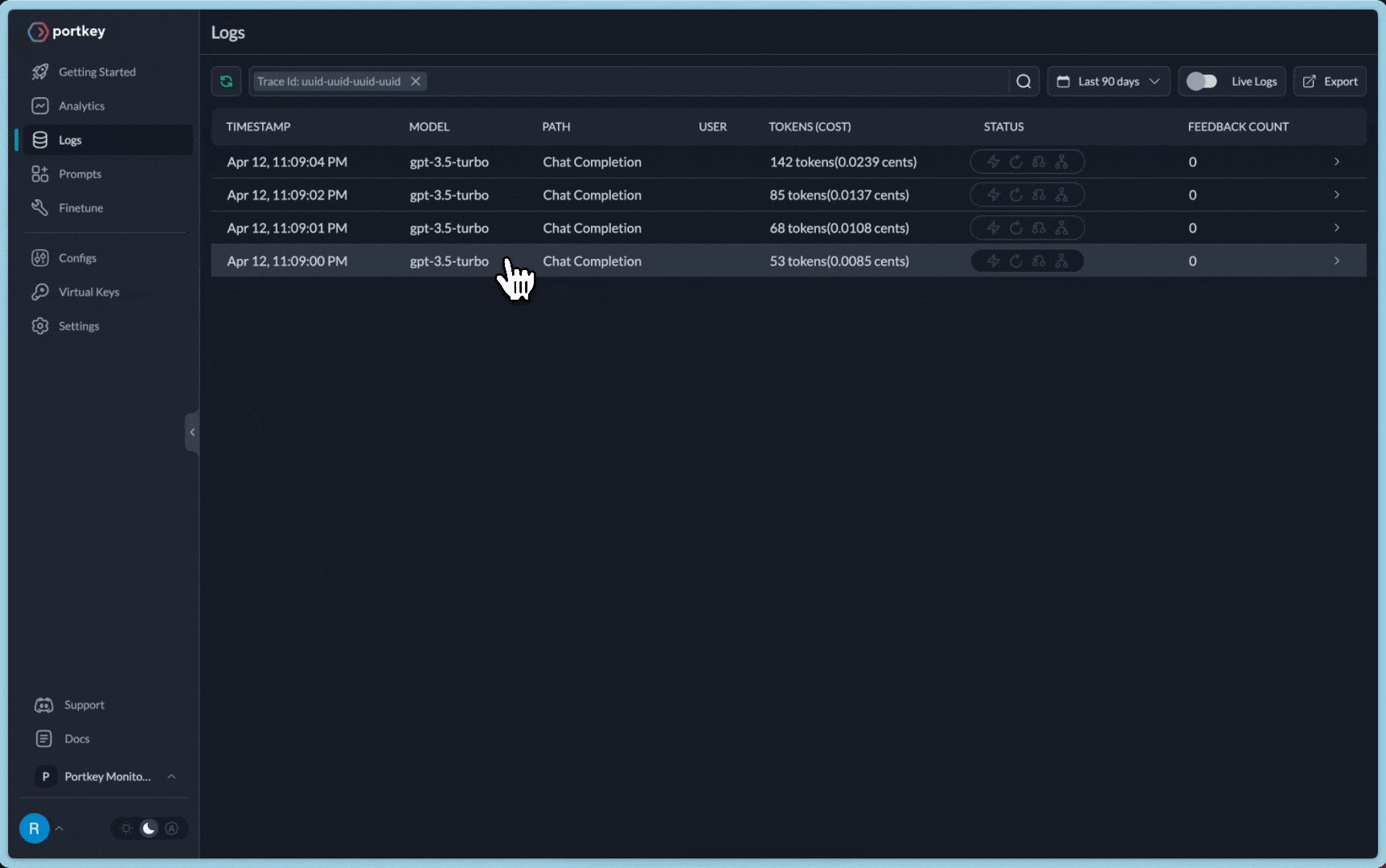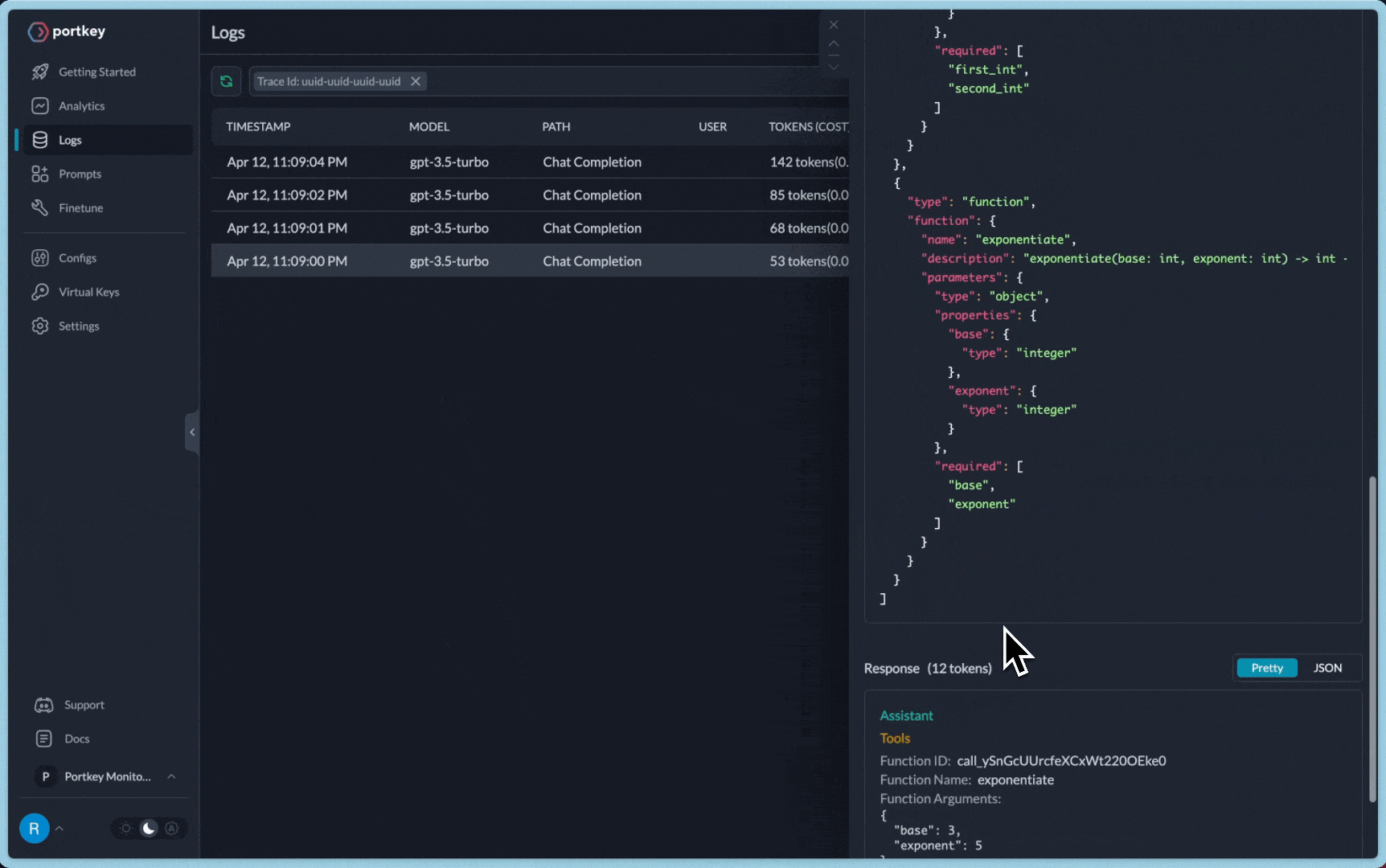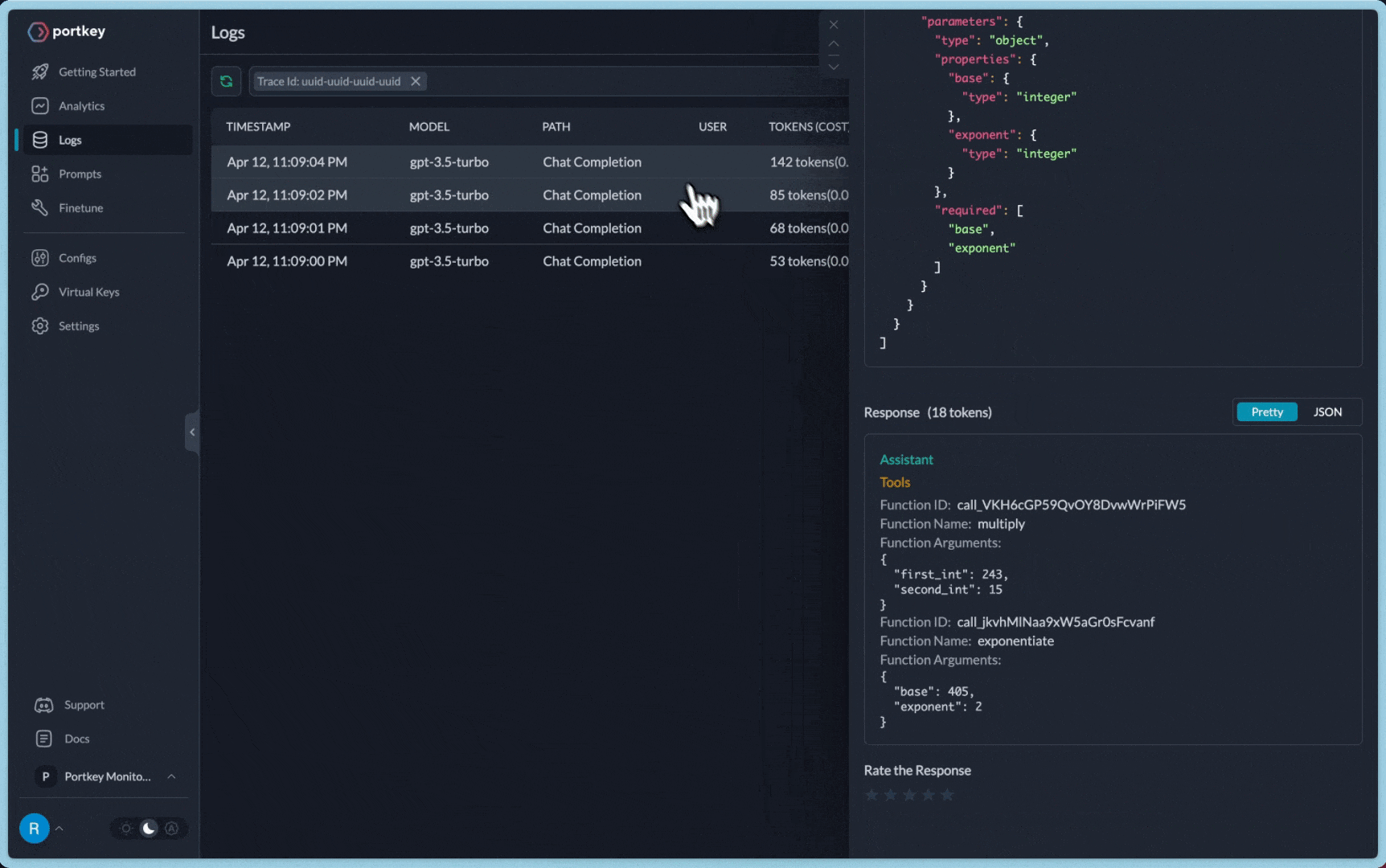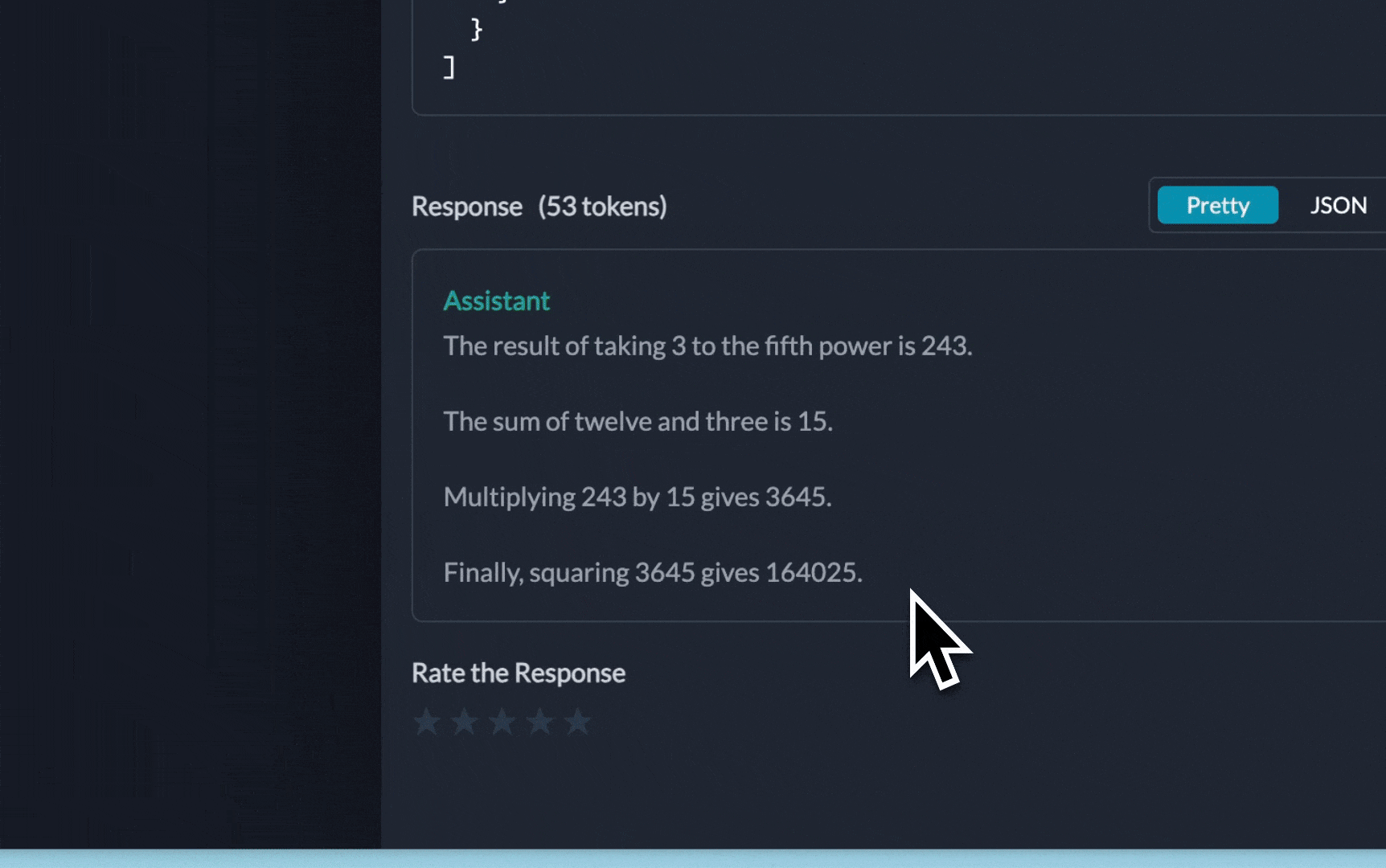
agent.run("What was the high temperature in SF yesterday in Fahrenheit? What is that number raised to the .023 power?")
|
||||
# Construct the OpenAI Tools agent
|
||||
agent = create_openai_tools_agent(model, tools, prompt)
|
||||
|
||||
# Create an agent executor by passing in the agent and tools
|
||||
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
|
||||
|
||||
agent_executor.invoke({
|
||||
"input": "Take 3 to the fifth power and multiply that by thirty six, then square the result"
|
||||
})
|
||||
```
|
||||
|
||||
**You can see the requests' logs along with the trace id on Portkey dashboard:**
|
||||
|
||||
|
||||
<img src="/img/portkey-dashboard.gif" height="250"/>
|
||||
<img src="/img/portkey-tracing.png" height="250"/>
|
||||
|
||||
## Advanced Features
|
||||
|
||||
1. **Logging:** Log all your LLM requests automatically by sending them through Portkey. Each request log contains `timestamp`, `model name`, `total cost`, `request time`, `request json`, `response json`, and additional Portkey features.
|
||||
2. **Tracing:** Trace id can be passed along with each request and is visibe on the logs on Portkey dashboard. You can also set a **distinct trace id** for each request. You can [append user feedback](https://docs.portkey.ai/key-features/feedback-api) to a trace id as well.
|
||||
3. **Caching:** Respond to previously served customers queries from cache instead of sending them again to OpenAI. Match exact strings OR semantically similar strings. Cache can save costs and reduce latencies by 20x.
|
||||
4. **Retries:** Automatically reprocess any unsuccessful API requests **`upto 5`** times. Uses an **`exponential backoff`** strategy, which spaces out retry attempts to prevent network overload.
|
||||
5. **Tagging:** Track and audit each user interaction in high detail with predefined tags.
|
||||
|
||||
| Feature | Config Key | Value (Type) | Required/Optional |
|
||||
| -- | -- | -- | -- |
|
||||
| API Key | `api_key` | API Key (`string`) | ✅ Required |
|
||||
| [Tracing Requests](https://docs.portkey.ai/key-features/request-tracing) | `trace_id` | Custom `string` | ❔ Optional |
|
||||
| [Automatic Retries](https://docs.portkey.ai/key-features/automatic-retries) | `retry_count` | `integer` [1,2,3,4,5] | ❔ Optional |
|
||||
| [Enabling Cache](https://docs.portkey.ai/key-features/request-caching) | `cache` | `simple` OR `semantic` | ❔ Optional |
|
||||
| Cache Force Refresh | `cache_force_refresh` | `True` | ❔ Optional |
|
||||
| Set Cache Expiry | `cache_age` | `integer` (in seconds) | ❔ Optional |
|
||||
| [Add User](https://docs.portkey.ai/key-features/custom-metadata) | `user` | `string` | ❔ Optional |
|
||||
| [Add Organisation](https://docs.portkey.ai/key-features/custom-metadata) | `organisation` | `string` | ❔ Optional |
|
||||
| [Add Environment](https://docs.portkey.ai/key-features/custom-metadata) | `environment` | `string` | ❔ Optional |
|
||||
| [Add Prompt (version/id/string)](https://docs.portkey.ai/key-features/custom-metadata) | `prompt` | `string` | ❔ Optional |
|
||||
|
||||
|
||||
## **Enabling all Portkey Features:**
|
||||
|
||||
```py
|
||||
headers = Portkey.Config(
|
||||
|
||||
# Mandatory
|
||||
api_key="<PORTKEY_API_KEY>",
|
||||
|
||||
# Cache Options
|
||||
cache="semantic",
|
||||
cache_force_refresh="True",
|
||||
cache_age=1729,
|
||||
|
||||
# Advanced
|
||||
retry_count=5,
|
||||
trace_id="langchain_agent",
|
||||
|
||||
# Metadata
|
||||
environment="production",
|
||||
user="john",
|
||||
organisation="acme",
|
||||
prompt="Frost"
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Additional Docs are available here:
|
||||
- Observability - https://portkey.ai/docs/product/observability-modern-monitoring-for-llms
|
||||
- AI Gateway - https://portkey.ai/docs/product/ai-gateway-streamline-llm-integrations
|
||||
- Prompt Library - https://portkey.ai/docs/product/prompt-library
|
||||
|
||||
You can check out our popular Open Source AI Gateway here - https://github.com/portkey-ai/gateway
|
||||
|
||||
For detailed information on each feature and how to use it, [please refer to the Portkey docs](https://docs.portkey.ai). If you have any questions or need further assistance, [reach out to us on Twitter.](https://twitter.com/portkeyai).
|
||||
For detailed information on each feature and how to use it, [please refer to the Portkey docs](https://portkey.ai/docs). If you have any questions or need further assistance, [reach out to us on Twitter.](https://twitter.com/portkeyai) or our [support email](mailto:hello@portkey.ai).
|
||||
|
||||
Loading…
Reference in New Issue