mirror of https://github.com/hwchase17/langchain
templates: Add neo4j semantic layer template (#15652)
Co-authored-by: Tomaz Bratanic <tomazbratanic@Tomazs-MacBook-Pro.local> Co-authored-by: Erick Friis <erick@langchain.dev>pull/15786/head
parent
70b6315b23
commit
3e0cd11f51
@ -0,0 +1,92 @@
|
||||
# neo4j-semantic-layer
|
||||
|
||||
This template is designed to implement an agent capable of interacting with a graph database like Neo4j through a semantic layer using OpenAI function calling.
|
||||
The semantic layer equips the agent with a suite of robust tools, allowing it to interact with the graph databas based on the user's intent.
|
||||
|
||||
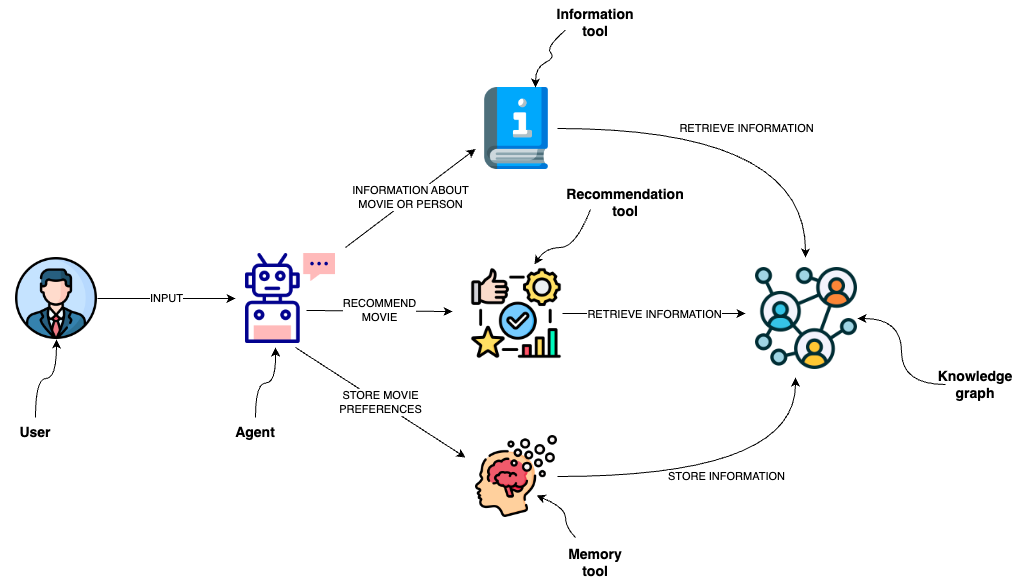
|
||||
|
||||
## Tools
|
||||
|
||||
The agent utilizes several tools to interact with the Neo4j graph database effectively:
|
||||
|
||||
1. **Information tool**:
|
||||
- Retrieves data about movies or individuals, ensuring the agent has access to the latest and most relevant information.
|
||||
2. **Recommendation Tool**:
|
||||
- Provides movie recommendations based upon user preferences and input.
|
||||
3. **Memory Tool**:
|
||||
- Stores information about user preferences in the knowledge graph, allowing for a personalized experience over multiple interactions.
|
||||
|
||||
## Environment Setup
|
||||
|
||||
You need to define the following environment variables
|
||||
|
||||
```
|
||||
OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
|
||||
NEO4J_URI=<YOUR_NEO4J_URI>
|
||||
NEO4J_USERNAME=<YOUR_NEO4J_USERNAME>
|
||||
NEO4J_PASSWORD=<YOUR_NEO4J_PASSWORD>
|
||||
```
|
||||
|
||||
## Populating with data
|
||||
|
||||
If you want to populate the DB with an example movie dataset, you can run `python ingest.py`.
|
||||
The script import information about movies and their rating by users.
|
||||
Additionally, the script creates two [fulltext indices](https://neo4j.com/docs/cypher-manual/current/indexes-for-full-text-search/), which are used to map information from user input to the database.
|
||||
|
||||
## Usage
|
||||
|
||||
To use this package, you should first have the LangChain CLI installed:
|
||||
|
||||
```shell
|
||||
pip install -U "langchain-cli[serve]"
|
||||
```
|
||||
|
||||
To create a new LangChain project and install this as the only package, you can do:
|
||||
|
||||
```shell
|
||||
langchain app new my-app --package neo4j-semantic-layer
|
||||
```
|
||||
|
||||
If you want to add this to an existing project, you can just run:
|
||||
|
||||
```shell
|
||||
langchain app add neo4j-semantic-layer
|
||||
```
|
||||
|
||||
And add the following code to your `server.py` file:
|
||||
```python
|
||||
from neo4j_semantic_layer import agent_executor as neo4j_semantic_agent
|
||||
|
||||
add_routes(app, neo4j_semantic_agent, path="/neo4j-semantic-layer")
|
||||
```
|
||||
|
||||
(Optional) Let's now configure LangSmith.
|
||||
LangSmith will help us trace, monitor and debug LangChain applications.
|
||||
LangSmith is currently in private beta, you can sign up [here](https://smith.langchain.com/).
|
||||
If you don't have access, you can skip this section
|
||||
|
||||
```shell
|
||||
export LANGCHAIN_TRACING_V2=true
|
||||
export LANGCHAIN_API_KEY=<your-api-key>
|
||||
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
|
||||
```
|
||||
|
||||
If you are inside this directory, then you can spin up a LangServe instance directly by:
|
||||
|
||||
```shell
|
||||
langchain serve
|
||||
```
|
||||
|
||||
This will start the FastAPI app with a server is running locally at
|
||||
[http://localhost:8000](http://localhost:8000)
|
||||
|
||||
We can see all templates at [http://127.0.0.1:8000/docs](http://127.0.0.1:8000/docs)
|
||||
We can access the playground at [http://127.0.0.1:8000/neo4j-semantic-layer/playground](http://127.0.0.1:8000/neo4j-semantic-layer/playground)
|
||||
|
||||
We can access the template from code with:
|
||||
|
||||
```python
|
||||
from langserve.client import RemoteRunnable
|
||||
|
||||
runnable = RemoteRunnable("http://localhost:8000/neo4j-semantic-layer")
|
||||
```
|
||||
@ -0,0 +1,59 @@
|
||||
from langchain_community.graphs import Neo4jGraph
|
||||
|
||||
# Instantiate connection to Neo4j
|
||||
graph = Neo4jGraph()
|
||||
|
||||
# Define unique constraints
|
||||
graph.query("CREATE CONSTRAINT IF NOT EXISTS FOR (m:Movie) REQUIRE m.id IS UNIQUE;")
|
||||
graph.query("CREATE CONSTRAINT IF NOT EXISTS FOR (u:User) REQUIRE u.id IS UNIQUE;")
|
||||
graph.query("CREATE CONSTRAINT IF NOT EXISTS FOR (p:Person) REQUIRE p.name IS UNIQUE;")
|
||||
graph.query("CREATE CONSTRAINT IF NOT EXISTS FOR (g:Genre) REQUIRE g.name IS UNIQUE;")
|
||||
|
||||
# Import movie information
|
||||
|
||||
movies_query = """
|
||||
LOAD CSV WITH HEADERS FROM
|
||||
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies.csv'
|
||||
AS row
|
||||
CALL {
|
||||
WITH row
|
||||
MERGE (m:Movie {id:row.movieId})
|
||||
SET m.released = date(row.released),
|
||||
m.title = row.title,
|
||||
m.imdbRating = toFloat(row.imdbRating)
|
||||
FOREACH (director in split(row.director, '|') |
|
||||
MERGE (p:Person {name:trim(director)})
|
||||
MERGE (p)-[:DIRECTED]->(m))
|
||||
FOREACH (actor in split(row.actors, '|') |
|
||||
MERGE (p:Person {name:trim(actor)})
|
||||
MERGE (p)-[:ACTED_IN]->(m))
|
||||
FOREACH (genre in split(row.genres, '|') |
|
||||
MERGE (g:Genre {name:trim(genre)})
|
||||
MERGE (m)-[:IN_GENRE]->(g))
|
||||
} IN TRANSACTIONS
|
||||
"""
|
||||
|
||||
graph.query(movies_query)
|
||||
|
||||
# Import rating information
|
||||
rating_query = """
|
||||
LOAD CSV WITH HEADERS FROM
|
||||
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/ratings.csv'
|
||||
AS row
|
||||
CALL {
|
||||
WITH row
|
||||
MATCH (m:Movie {id:row.movieId})
|
||||
MERGE (u:User {id:row.userId})
|
||||
MERGE (u)-[r:RATED]->(m)
|
||||
SET r.rating = toFloat(row.rating),
|
||||
r.timestamp = row.timestamp
|
||||
} IN TRANSACTIONS OF 10000 ROWS
|
||||
"""
|
||||
|
||||
graph.query(rating_query)
|
||||
|
||||
# Define fulltext indices
|
||||
graph.query("CREATE FULLTEXT INDEX movie IF NOT EXISTS FOR (m:Movie) ON EACH [m.title]")
|
||||
graph.query(
|
||||
"CREATE FULLTEXT INDEX person IF NOT EXISTS FOR (p:Person) ON EACH [p.name]"
|
||||
)
|
||||
@ -0,0 +1,17 @@
|
||||
from neo4j_semantic_layer import agent_executor
|
||||
|
||||
if __name__ == "__main__":
|
||||
original_query = "What do you know about person John?"
|
||||
followup_query = "John Travolta"
|
||||
chat_history = [
|
||||
(
|
||||
"What do you know about person John?",
|
||||
"I found multiple people named John. Could you please specify "
|
||||
"which one you are interested in? Here are some options:"
|
||||
"\n\n1. John Travolta\n2. John McDonough",
|
||||
)
|
||||
]
|
||||
print(agent_executor.invoke({"input": original_query}))
|
||||
print(
|
||||
agent_executor.invoke({"input": followup_query, "chat_history": chat_history})
|
||||
)
|
||||
@ -0,0 +1,3 @@
|
||||
from neo4j_semantic_layer.agent import agent_executor
|
||||
|
||||
__all__ = ["agent_executor"]
|
||||
@ -0,0 +1,71 @@
|
||||
from typing import List, Tuple
|
||||
|
||||
from langchain.agents import AgentExecutor
|
||||
from langchain.agents.format_scratchpad import format_to_openai_function_messages
|
||||
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
|
||||
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.schema import AIMessage, HumanMessage
|
||||
from langchain.tools.render import format_tool_to_openai_function
|
||||
from langchain_community.chat_models import ChatOpenAI
|
||||
|
||||
from neo4j_semantic_layer.information_tool import InformationTool
|
||||
from neo4j_semantic_layer.memory_tool import MemoryTool
|
||||
from neo4j_semantic_layer.recommendation_tool import RecommenderTool
|
||||
|
||||
llm = ChatOpenAI(temperature=0, model="gpt-4")
|
||||
tools = [InformationTool(), RecommenderTool(), MemoryTool()]
|
||||
|
||||
llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
|
||||
|
||||
prompt = ChatPromptTemplate.from_messages(
|
||||
[
|
||||
(
|
||||
"system",
|
||||
"You are a helpful assistant that finds information about movies "
|
||||
" and recommends them. If tools require follow up questions, "
|
||||
"make sure to ask the user for clarification. Make sure to include any "
|
||||
"available options that need to be clarified in the follow up questions",
|
||||
),
|
||||
MessagesPlaceholder(variable_name="chat_history"),
|
||||
("user", "{input}"),
|
||||
MessagesPlaceholder(variable_name="agent_scratchpad"),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def _format_chat_history(chat_history: List[Tuple[str, str]]):
|
||||
buffer = []
|
||||
for human, ai in chat_history:
|
||||
buffer.append(HumanMessage(content=human))
|
||||
buffer.append(AIMessage(content=ai))
|
||||
return buffer
|
||||
|
||||
|
||||
agent = (
|
||||
{
|
||||
"input": lambda x: x["input"],
|
||||
"chat_history": lambda x: _format_chat_history(x["chat_history"])
|
||||
if x.get("chat_history")
|
||||
else [],
|
||||
"agent_scratchpad": lambda x: format_to_openai_function_messages(
|
||||
x["intermediate_steps"]
|
||||
),
|
||||
}
|
||||
| prompt
|
||||
| llm_with_tools
|
||||
| OpenAIFunctionsAgentOutputParser()
|
||||
)
|
||||
|
||||
|
||||
# Add typing for input
|
||||
class AgentInput(BaseModel):
|
||||
input: str
|
||||
chat_history: List[Tuple[str, str]] = Field(
|
||||
..., extra={"widget": {"type": "chat", "input": "input", "output": "output"}}
|
||||
)
|
||||
|
||||
|
||||
agent_executor = AgentExecutor(agent=agent, tools=tools).with_types(
|
||||
input_type=AgentInput
|
||||
)
|
||||
@ -0,0 +1,74 @@
|
||||
from typing import Optional, Type
|
||||
|
||||
from langchain.callbacks.manager import (
|
||||
AsyncCallbackManagerForToolRun,
|
||||
CallbackManagerForToolRun,
|
||||
)
|
||||
|
||||
# Import things that are needed generically
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.tools import BaseTool
|
||||
|
||||
from neo4j_semantic_layer.utils import get_candidates, graph
|
||||
|
||||
description_query = """
|
||||
MATCH (m:Movie|Person)
|
||||
WHERE m.title = $candidate OR m.name = $candidate
|
||||
MATCH (m)-[r:ACTED_IN|DIRECTED|HAS_GENRE]-(t)
|
||||
WITH m, type(r) as type, collect(coalesce(t.name, t.title)) as names
|
||||
WITH m, type+": "+reduce(s="", n IN names | s + n + ", ") as types
|
||||
WITH m, collect(types) as contexts
|
||||
WITH m, "type:" + labels(m)[0] + "\ntitle: "+ coalesce(m.title, m.name)
|
||||
+ "\nyear: "+coalesce(m.released,"") +"\n" +
|
||||
reduce(s="", c in contexts | s + substring(c, 0, size(c)-2) +"\n") as context
|
||||
RETURN context LIMIT 1
|
||||
"""
|
||||
|
||||
|
||||
def get_information(entity: str, type: str) -> str:
|
||||
candidates = get_candidates(entity, type)
|
||||
if not candidates:
|
||||
return "No information was found about the movie or person in the database"
|
||||
elif len(candidates) > 1:
|
||||
newline = "\n"
|
||||
return (
|
||||
"Need additional information, which of these "
|
||||
f"did you mean: {newline + newline.join(str(d) for d in candidates)}"
|
||||
)
|
||||
data = graph.query(
|
||||
description_query, params={"candidate": candidates[0]["candidate"]}
|
||||
)
|
||||
return data[0]["context"]
|
||||
|
||||
|
||||
class InformationInput(BaseModel):
|
||||
entity: str = Field(description="movie or a person mentioned in the question")
|
||||
entity_type: str = Field(
|
||||
description="type of the entity. Available options are 'movie' or 'person'"
|
||||
)
|
||||
|
||||
|
||||
class InformationTool(BaseTool):
|
||||
name = "Information"
|
||||
description = (
|
||||
"useful for when you need to answer questions about various actors or movies"
|
||||
)
|
||||
args_schema: Type[BaseModel] = InformationInput
|
||||
|
||||
def _run(
|
||||
self,
|
||||
entity: str,
|
||||
entity_type: str,
|
||||
run_manager: Optional[CallbackManagerForToolRun] = None,
|
||||
) -> str:
|
||||
"""Use the tool."""
|
||||
return get_information(entity, entity_type)
|
||||
|
||||
async def _arun(
|
||||
self,
|
||||
entity: str,
|
||||
entity_type: str,
|
||||
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
|
||||
) -> str:
|
||||
"""Use the tool asynchronously."""
|
||||
return get_information(entity, entity_type)
|
||||
@ -0,0 +1,72 @@
|
||||
from typing import Optional, Type
|
||||
|
||||
from langchain.callbacks.manager import (
|
||||
AsyncCallbackManagerForToolRun,
|
||||
CallbackManagerForToolRun,
|
||||
)
|
||||
|
||||
# Import things that are needed generically
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.tools import BaseTool
|
||||
|
||||
from neo4j_semantic_layer.utils import get_candidates, get_user_id, graph
|
||||
|
||||
store_rating_query = """
|
||||
MERGE (u:User {userId:$user_id})
|
||||
WITH u
|
||||
UNWIND $candidates as row
|
||||
MATCH (m:Movie {title: row.candidate})
|
||||
MERGE (u)-[r:RATED]->(m)
|
||||
SET r.rating = toFloat($rating)
|
||||
RETURN distinct 'Noted' AS response
|
||||
"""
|
||||
|
||||
|
||||
def store_movie_rating(movie: str, rating: int):
|
||||
user_id = get_user_id()
|
||||
candidates = get_candidates(movie, "movie")
|
||||
if not candidates:
|
||||
return "This movie is not in our database"
|
||||
response = graph.query(
|
||||
store_rating_query,
|
||||
params={"user_id": user_id, "candidates": candidates, "rating": rating},
|
||||
)
|
||||
try:
|
||||
return response[0]["response"]
|
||||
except Exception as e:
|
||||
print(e)
|
||||
return "Something went wrong"
|
||||
|
||||
|
||||
class MemoryInput(BaseModel):
|
||||
movie: str = Field(description="movie the user liked")
|
||||
rating: int = Field(
|
||||
description=(
|
||||
"Rating from 1 to 5, where one represents heavy dislike "
|
||||
"and 5 represent the user loved the movie"
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
class MemoryTool(BaseTool):
|
||||
name = "Memory"
|
||||
description = "useful for memorizing which movies the user liked"
|
||||
args_schema: Type[BaseModel] = MemoryInput
|
||||
|
||||
def _run(
|
||||
self,
|
||||
movie: str,
|
||||
rating: int,
|
||||
run_manager: Optional[CallbackManagerForToolRun] = None,
|
||||
) -> str:
|
||||
"""Use the tool."""
|
||||
return store_movie_rating(movie, rating)
|
||||
|
||||
async def _arun(
|
||||
self,
|
||||
movie: str,
|
||||
rating: int,
|
||||
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
|
||||
) -> str:
|
||||
"""Use the tool asynchronously."""
|
||||
return store_movie_rating(movie, rating)
|
||||
@ -0,0 +1,143 @@
|
||||
from typing import Optional, Type
|
||||
|
||||
from langchain.callbacks.manager import (
|
||||
AsyncCallbackManagerForToolRun,
|
||||
CallbackManagerForToolRun,
|
||||
)
|
||||
from langchain.pydantic_v1 import BaseModel, Field
|
||||
from langchain.tools import BaseTool
|
||||
|
||||
from neo4j_semantic_layer.utils import get_candidates, get_user_id, graph
|
||||
|
||||
recommendation_query_db_history = """
|
||||
MERGE (u:User {userId:$user_id})
|
||||
WITH u
|
||||
// get recommendation candidates
|
||||
OPTIONAL MATCH (u)-[r1:RATED]->()<-[r2:RATED]-()-[r3:RATED]->(recommendation)
|
||||
WHERE r1.rating > 3.5 AND r2.rating > 3.5 AND r3.rating > 3.5
|
||||
AND NOT EXISTS {(u)-[:RATED]->(recommendation)}
|
||||
// rank and limit recommendations
|
||||
WITH u, recommendation, count(*) AS count
|
||||
ORDER BY count DESC LIMIT 3
|
||||
RETURN recommendation.title AS movie
|
||||
"""
|
||||
|
||||
recommendation_query_genre = """
|
||||
MATCH (m:Movie)-[:IN_GENRE]->(g:Genre {name:$genre})
|
||||
// filter out already seen movies by the user
|
||||
WHERE NOT EXISTS {
|
||||
(m)<-[:RATED]-(:User {userId:$user_id})
|
||||
}
|
||||
// rank and limit recommendations
|
||||
WITH m
|
||||
ORDER BY m.imdbRating DESC LIMIT 3
|
||||
RETURN m.title AS movie
|
||||
"""
|
||||
|
||||
|
||||
def recommendation_query_movie(genre: bool) -> str:
|
||||
return f"""
|
||||
MATCH (m1:Movie)<-[r1:RATED]-()-[r2:RATED]->(m2:Movie)
|
||||
WHERE r1.rating > 3.5 AND r2.rating > 3.5 and m1.title IN $movieTitles
|
||||
// filter out already seen movies by the user
|
||||
AND NOT EXISTS {{
|
||||
(m2)<-[:RATED]-(:User {{userId:$user_id}})
|
||||
}}
|
||||
{'AND EXISTS {(m2)-[:IN_GENRE]->(:Genre {name:$genre})}' if genre else ''}
|
||||
// rank and limit recommendations
|
||||
WITH m2, count(*) AS count
|
||||
ORDER BY count DESC LIMIT 3
|
||||
RETURN m2.title As movie
|
||||
"""
|
||||
|
||||
|
||||
def recommend_movie(movie: Optional[str] = None, genre: Optional[str] = None) -> str:
|
||||
"""
|
||||
Recommends movies based on user's history and preference
|
||||
for a specific movie and/or genre.
|
||||
Returns:
|
||||
str: A string containing a list of recommended movies, or an error message.
|
||||
"""
|
||||
user_id = get_user_id()
|
||||
params = {"user_id": user_id, "genre": genre}
|
||||
if not movie and not genre:
|
||||
# Try to recommend a movie based on the information in the db
|
||||
response = graph.query(recommendation_query_db_history, params)
|
||||
try:
|
||||
return ", ".join([el["movie"] for el in response])
|
||||
except Exception:
|
||||
return "Can you tell us about some of the movies you liked?"
|
||||
if not movie and genre:
|
||||
# Recommend top voted movies in the genre the user haven't seen before
|
||||
response = graph.query(recommendation_query_genre, params)
|
||||
try:
|
||||
return ", ".join([el["movie"] for el in response])
|
||||
except Exception:
|
||||
return "Something went wrong"
|
||||
|
||||
candidates = get_candidates(movie, "movie")
|
||||
if not candidates:
|
||||
return "The movie you mentioned wasn't found in the database"
|
||||
params["movieTitles"] = [el["candidate"] for el in candidates]
|
||||
query = recommendation_query_movie(bool(genre))
|
||||
response = graph.query(query, params)
|
||||
try:
|
||||
return ", ".join([el["movie"] for el in response])
|
||||
except Exception:
|
||||
return "Something went wrong"
|
||||
|
||||
|
||||
all_genres = [
|
||||
"Action",
|
||||
"Adventure",
|
||||
"Animation",
|
||||
"Children",
|
||||
"Comedy",
|
||||
"Crime",
|
||||
"Documentary",
|
||||
"Drama",
|
||||
"Fantasy",
|
||||
"Film-Noir",
|
||||
"Horror",
|
||||
"IMAX",
|
||||
"Musical",
|
||||
"Mystery",
|
||||
"Romance",
|
||||
"Sci-Fi",
|
||||
"Thriller",
|
||||
"War",
|
||||
"Western",
|
||||
]
|
||||
|
||||
|
||||
class RecommenderInput(BaseModel):
|
||||
movie: Optional[str] = Field(description="movie used for recommendation")
|
||||
genre: Optional[str] = Field(
|
||||
description=(
|
||||
"genre used for recommendation. Available options are:" f"{all_genres}"
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
class RecommenderTool(BaseTool):
|
||||
name = "Recommender"
|
||||
description = "useful for when you need to recommend a movie"
|
||||
args_schema: Type[BaseModel] = RecommenderInput
|
||||
|
||||
def _run(
|
||||
self,
|
||||
movie: Optional[str] = None,
|
||||
genre: Optional[str] = None,
|
||||
run_manager: Optional[CallbackManagerForToolRun] = None,
|
||||
) -> str:
|
||||
"""Use the tool."""
|
||||
return recommend_movie(movie, genre)
|
||||
|
||||
async def _arun(
|
||||
self,
|
||||
movie: Optional[str] = None,
|
||||
genre: Optional[str] = None,
|
||||
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
|
||||
) -> str:
|
||||
"""Use the tool asynchronously."""
|
||||
return recommend_movie(movie, genre)
|
||||
@ -0,0 +1,84 @@
|
||||
from typing import Dict, List
|
||||
|
||||
from langchain_community.graphs import Neo4jGraph
|
||||
|
||||
graph = Neo4jGraph()
|
||||
|
||||
|
||||
def get_user_id() -> int:
|
||||
"""
|
||||
Placeholder for a function that would normally retrieve
|
||||
a user's ID
|
||||
"""
|
||||
return 1
|
||||
|
||||
|
||||
def remove_lucene_chars(text: str) -> str:
|
||||
"""Remove Lucene special characters"""
|
||||
special_chars = [
|
||||
"+",
|
||||
"-",
|
||||
"&",
|
||||
"|",
|
||||
"!",
|
||||
"(",
|
||||
")",
|
||||
"{",
|
||||
"}",
|
||||
"[",
|
||||
"]",
|
||||
"^",
|
||||
'"',
|
||||
"~",
|
||||
"*",
|
||||
"?",
|
||||
":",
|
||||
"\\",
|
||||
]
|
||||
for char in special_chars:
|
||||
if char in text:
|
||||
text = text.replace(char, " ")
|
||||
return text.strip()
|
||||
|
||||
|
||||
def generate_full_text_query(input: str) -> str:
|
||||
"""
|
||||
Generate a full-text search query for a given input string.
|
||||
|
||||
This function constructs a query string suitable for a full-text search.
|
||||
It processes the input string by splitting it into words and appending a
|
||||
similarity threshold (~0.8) to each word, then combines them using the AND
|
||||
operator. Useful for mapping movies and people from user questions
|
||||
to database values, and allows for some misspelings.
|
||||
"""
|
||||
full_text_query = ""
|
||||
words = [el for el in remove_lucene_chars(input).split() if el]
|
||||
for word in words[:-1]:
|
||||
full_text_query += f" {word}~0.8 AND"
|
||||
full_text_query += f" {words[-1]}~0.8"
|
||||
return full_text_query.strip()
|
||||
|
||||
|
||||
candidate_query = """
|
||||
CALL db.index.fulltext.queryNodes($index, $fulltextQuery, {limit: $limit})
|
||||
YIELD node
|
||||
RETURN coalesce(node.name, node.title) AS candidate,
|
||||
[el in labels(node) WHERE el IN ['Person', 'Movie'] | el][0] AS label
|
||||
"""
|
||||
|
||||
|
||||
def get_candidates(input: str, type: str, limit: int = 3) -> List[Dict[str, str]]:
|
||||
"""
|
||||
Retrieve a list of candidate entities from database based on the input string.
|
||||
|
||||
This function queries the Neo4j database using a full-text search. It takes the
|
||||
input string, generates a full-text query, and executes this query against the
|
||||
specified index in the database. The function returns a list of candidates
|
||||
matching the query, with each candidate being a dictionary containing their name
|
||||
(or title) and label (either 'Person' or 'Movie').
|
||||
"""
|
||||
ft_query = generate_full_text_query(input)
|
||||
candidates = graph.query(
|
||||
candidate_query, {"fulltextQuery": ft_query, "index": type, "limit": limit}
|
||||
)
|
||||
return candidates
|
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,33 @@
|
||||
[tool.poetry]
|
||||
name = "neo4j-semantic-layer"
|
||||
version = "0.1.0"
|
||||
description = "Build a semantic layer to allow an agent to interact with a graph database in consistent and robust way."
|
||||
authors = [
|
||||
"Tomaz Bratanic <tomaz.bratanic@neo4j.com>",
|
||||
]
|
||||
readme = "README.md"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8.1,<4.0"
|
||||
langchain = "^0.1"
|
||||
openai = "<2"
|
||||
neo4j = "^5.14.0"
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
langchain-cli = ">=0.0.20"
|
||||
|
||||
[tool.langserve]
|
||||
export_module = "neo4j_semantic_layer"
|
||||
export_attr = "agent_executor"
|
||||
|
||||
[tool.templates-hub]
|
||||
use-case = "semantic_layer"
|
||||
author = "Neo4j"
|
||||
integrations = ["Neo4j", "OpenAI"]
|
||||
tags = ["search", "graph-database", "function-calling"]
|
||||
|
||||
[build-system]
|
||||
requires = [
|
||||
"poetry-core",
|
||||
]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 92 KiB |
Loading…
Reference in New Issue