mirror of
https://github.com/dair-ai/Prompt-Engineering-Guide
synced 2024-11-10 01:13:36 +00:00
21 lines
2.6 KiB
Plaintext
21 lines
2.6 KiB
Plaintext
# Was ist Groq?
|
||
|
||
[Groq](https://groq.com/) machte kürzlich viele Schlagzeilen als eine der schnellsten LLM-Inferenzlösungen, die heute verfügbar sind. Es gibt großes Interesse von LLM-Praktikern daran, die Latenz bei LLM-Antworten zu reduzieren. Latenz ist eine wichtige Metrik, um Echtzeit-KI-Anwendungen zu optimieren und zu ermöglichen. Es gibt jetzt viele Unternehmen in diesem Bereich, die um LLM-Inferenz konkurrieren.
|
||
|
||
Groq ist eines dieser LLM-Inferenzunternehmen, das zum Zeitpunkt der Verfassung dieses Beitrags eine 18-fach schnellere Inferenzleistung auf dem [Anyscale's LLMPerf Leaderboard](https://github.com/ray-project/llmperf-leaderboard) im Vergleich zu anderen führenden cloud-basierten Anbietern beansprucht. Groq bietet derzeit Modelle wie Meta AI's Llama 2 70B und Mixtral 8x7B über ihre APIs an. Diese Modelle werden von der Groq LPU™-Inferenzmaschine angetrieben, die mit ihrer eigenen, speziell für LLMs entworfenen Hardware, den sogenannten Sprachverarbeitungseinheiten (LPUs), gebaut ist.
|
||
|
||
Laut den FAQs von Groq hilft die LPU dabei, die pro Wort berechnete Zeit zu reduzieren, was eine schnellere Textsequenzgenerierung ermöglicht. Sie können mehr über die technischen Details der LPU und ihre Vorteile in ihren mit dem ISCA-Preis ausgezeichneten [2020](https://wow.groq.com/groq-isca-paper-2020/) und [2022](https://wow.groq.com/isca-2022-paper/) Papieren lesen.
|
||
|
||
Hier ist eine Tabelle mit der Geschwindigkeit und den Preisen für ihre Modelle:
|
||
|
||

|
||
|
||
Die untenstehende Tabelle vergleicht den Durchsatz der Ausgabetokens (Tokens/s), der die durchschnittliche Anzahl an Ausgabetokens pro Sekunde darstellt. Die Zahlen in der Tabelle entsprechen dem mittleren Durchsatz der Ausgabetokens (basierend auf 150 Anfragen) der LLM-Inferenzanbieter für das Modell Llama 2 70B.
|
||
|
||
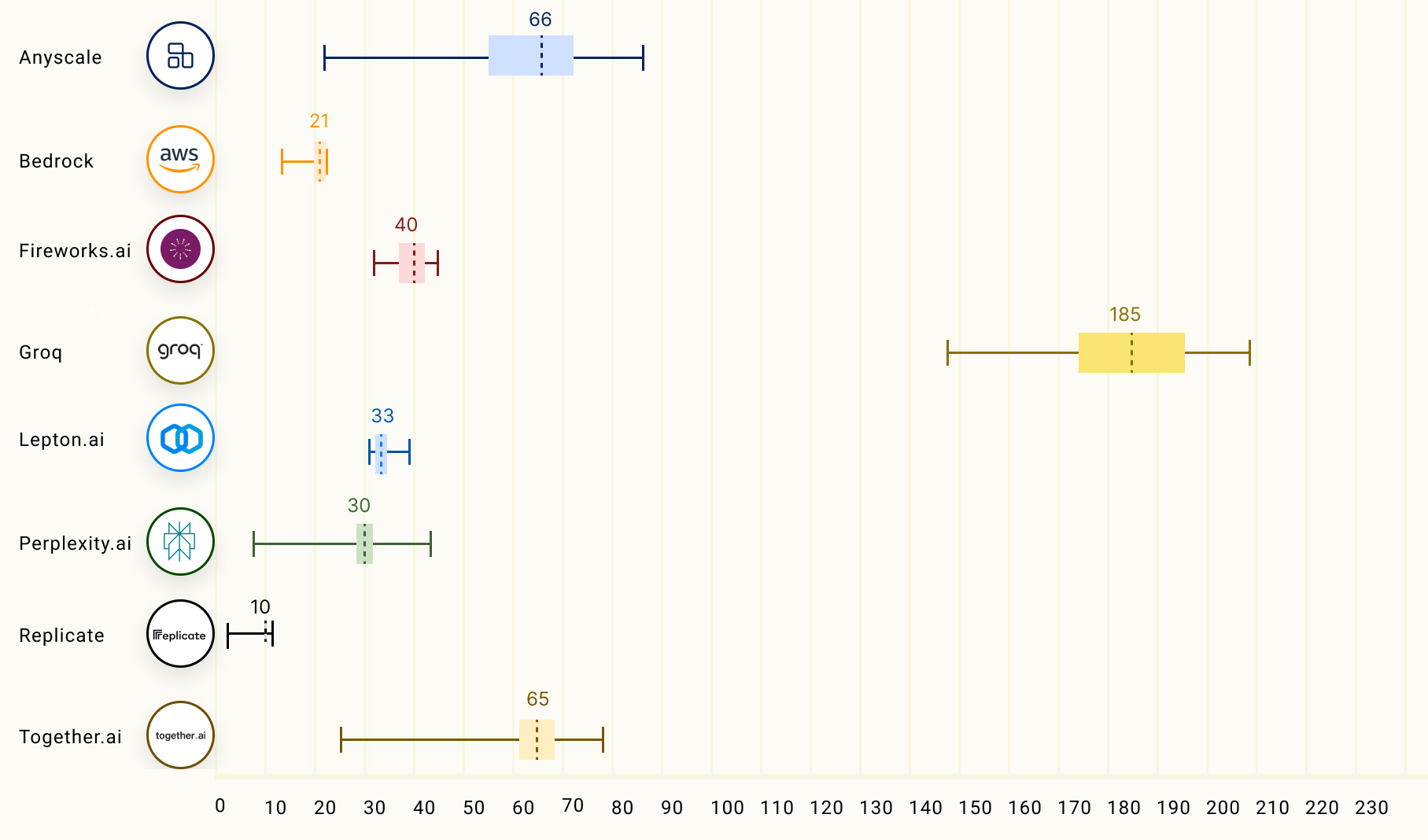
|
||
|
||
Ein weiterer wichtiger Faktor der LLM-Inferenz, insbesondere für Streaming-Anwendungen, wird als Zeit bis zum ersten Token (TTFT) bezeichnet und entspricht der Dauer, die das LLM benötigt, um das erste Token zurückzugeben. Unten ist eine Tabelle, die zeigt, wie sich verschiedene LLM-Inferenzanbieter verhalten:
|
||
|
||
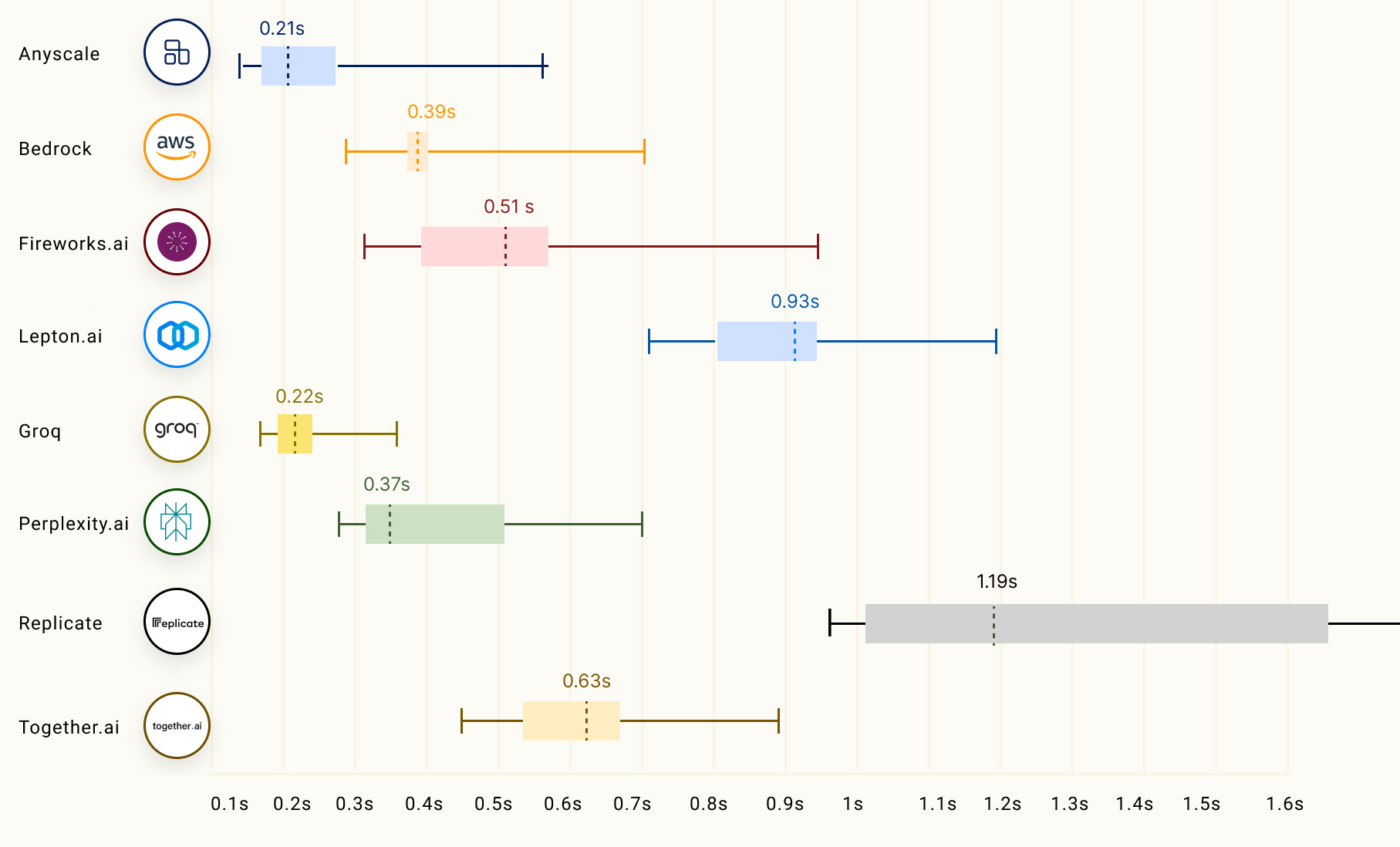
|
||
|
||
Sie können mehr über die LLM-Inferenzleistung von Groq im Anyscale’s LLMPerf Leaderboard [hier](https://wow.groq.com/groq-lpu-inference-engine-crushes-first-public-llm-benchmark/) lesen. |